This Quick Start sets up an architecture for predictive data science with Amazon SageMaker and a data lake on Amazon Web Services (AWS). The deployment, which takes about 10-15 minutes, uses AWS services such as Amazon Simple Storage Service (Amazon S3), Amazon API Gateway, Amazon Kinesis Data Streams, and Amazon Kinesis Data Firehose.
Amazon SageMaker is a managed platform that enables developers and data scientists to build, train, and deploy machine learning (ML) models.
This Quick Start is for those who want to use data to make predictive and prescriptive models, without needing to configure complex ML hardware clusters.
The Quick Start provides a demo created by Pariveda Solutions. The demo shows how to store raw data on Amazon S3, transform the data for consumption in Amazon SageMaker, use Amazon SageMaker to build an ML model, and host the model in a prediction API for Amazon Elastic Compute Cloud (Amazon EC2) Spot pricing.
The AWS CloudFormation templates included with the Quick Start automate the deployment.
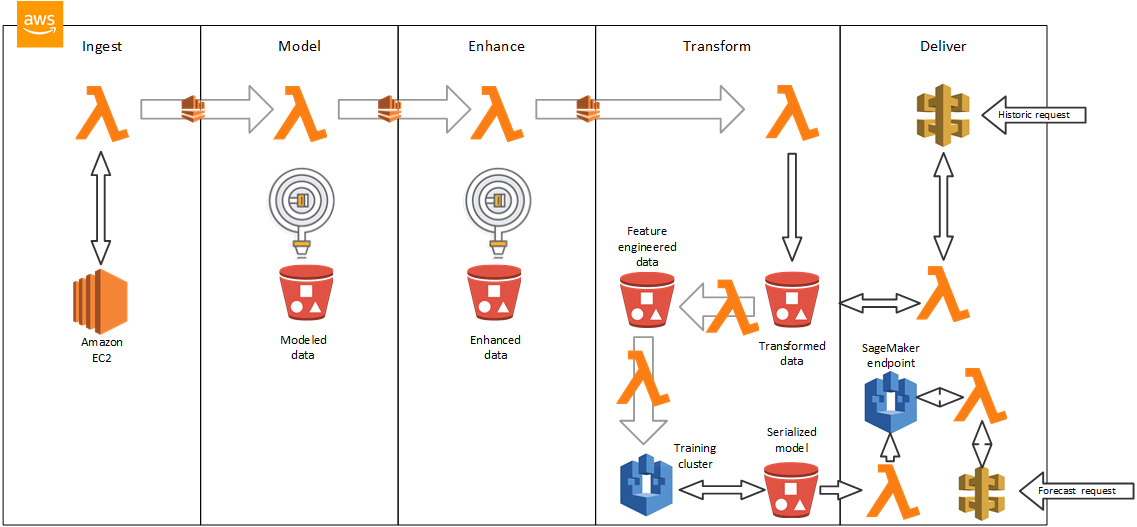
For architectural details, best practices, step-by-step instructions, and customization options, see the deployment guide.
To post feedback, submit feature ideas, or report bugs, use the Issues section of this GitHub repo. If you'd like to submit code for this Quick Start, please review the AWS Quick Start Contributor's Kit.