- 일정한 패턴을 가진 문자열의 집할을 표현하기 위해 사용하는 형식 언어
- 문자열을 대상으로 패턴 매칭 기능 제공: 특정 패턴과 일치하는 문자열을 검색하거나 추출 또는 치환하는 기능
const tel = "010-1234-567팔";
// 정규 표현식 리터럴로 전화번호 패턴을 정의함
const regExp = /^\d{3}-\d{4}-\d{4}$/;
regExp.test(tel); // false=> 정규식 표현식을 사용하여, 반복문과 조건문 없이 패턴 정의
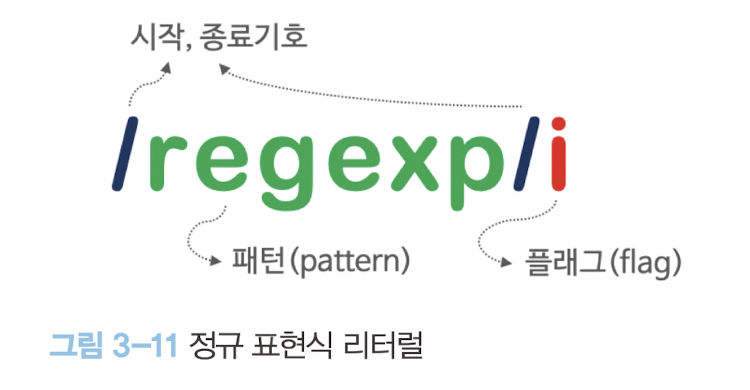
- 정규 표현식 리터럴
/regexp/i: 패턴과 플래그로 구성됨
-
패턴:
regexp& 플래그:iconst target = "Is this all there is?"; // 패턴: is // 플래그: i => 대소문자를 구별하지 않고 검색한다. // 정규 표현식 리터럴 방식 const regexp = /is/i; // 정규 표현식 생성자 함수 방식 const regexp = new RegExp(/is/i); // ES6 // const regexp = new RegExp(/is/, 'i'); // const regexp = new RegExp('is', 'i'); // test 메서드는 target 문자열에 대해 정규표현식 regexp의 패턴을 검색하여 매칭 결과를 불리언 값으로 반환한다. regexp.test(target); // -> true
- RegExp 생성자 함수
// pattern: 정규 표현식의 패턴
// flags: 정규 표현식의 플래그
new RegExp(pattern[ , flags])- 변수를 사용하여 동적으로 RegExp 객체 생성 가능
const count = (str, char) => (str.match(new RegExp(char, "gi")) ?? []).length;
count("Is this all there is?", "is"); // 3 ['Is', 'is', 'is']
count("Is this all there is?", "xx"); // 0(1) RegExp(char, 'gi'): 'is'가 대소문자 구분 없이 문자열 내에 몇 번 있는지 찾음 - g: global, 전체 문자열에서 모두 찾기 - i: ignore case, 대소문자 무시
(2) str.match(...) - match()는 문자열에서 정규식과 일치하는 모든 부분을 배열로 반환
(3) ?? [] - match()가 일치하는 게 없으면, null 반환. - null.length를 하면 오류 발생, 이를 막기 위해 null인 경우 빈 배열 []로 대체. - ?? == “null 병합 연산자”. null이나 undefined면 뒤에 있는 값으로 대체.
- 인수로 전달 받은 문자열에 대해 정규 표현식의 패턴을 검색하여 매칭 결과를 배열로 반환함. 매칭 결과가 없는 경우 null 반환.
- 인수로 전달 받은 문자열에 대해 정규 표현식의 패턴을 검색하여 매칭 결과를 불리언 값으로 반환함.
- 대상 문자열과 인수로 전달 받은 정규 표현식과의 매칭 결과를 배열로 반환함.
- 정규 표현식의 검색 방식을 설정하기 위해 사용함
- 옵션으로 선택적으로 사용 가능함. 순서와 상관없이 하나 이상의 플래그를 동시에 설정 가능함. 아무런 플래그가 없을 땐 대소문자 구별해서 패턴 검색함.
| 플래그 | 의미 | 설명 |
|---|---|---|
| i | Ignore case | 대소문자 구별 없이 패턴 검색 |
| g | Global | 대상 문자열 내에서 패턴과 일치하는 모든 문자열을 전역 검색 |
| m | Multi line | 문자열의 행이 바뀌더라도 패턴 검색을 계속함 |
const target = "Is this all there is?";
// target 문자열에서 is 문자열을 대소문자를 구별하여 한 번만 검색한다.
target.match(/is/);
// -> ["is", index: 5, input: "Is this all there is?", groups: undefined]
// target 문자열에서 is 문자열을 대소문자를 구별하지 않고 한 번만 검색한다.
target.match(/is/i);
// -> ["Is", index: 0, input: "Is this all there is?", groups: undefined]
// target 문자열에서 is 문자열을 대소문자를 구별하여 전역 검색한다.
target.match(/is/g);
// -> ["is", "is"]
// target 문자열에서 is 문자열을 대소문자를 구별하지 않고 전역 검색한다.
target.match(/is/gi);
// -> ["Is", "is", "is"]- 정규 표현식의 패턴은 문자열의 일정한 규칙을 표현하기 위해 사용하며, 정규 표현식의 검색 방식을 설정하기 위해 사용함.
- 패턴은
/로 열고 닫으며 문자열의 따옴표는 생략한다. - 패턴은 특별한 의미를 가지는 메타문자 또는 기호로 표현 가능하다.
- 어떤 문자열 내 패턴과 일치하는 문자열이 존재할 때 '정규 표현식과 매치한다'고 표현한다.
- 정규 표현식의 패턴에 문자 또는 문자열을 지정하면 검색 대상 문자열에서 패턴으로 지정한 문자 또는 문자열을 검색한다.
.은 임의의 문자 한 개를 의미한다.
const target = "Is this all there is?";
// 임의의 3자리 문자열을 대소문자를 구별하여 전역 검색한다.
const regExp = /.../g;
target.match(regExp); // -> ["Is ", "thi", "s a", "ll ", "the", "re ", "is?"]=> .을 3개 연속하여 패턴을 생성했으므로 문자의 내용과 상관없이 3자리 문자열과 매치한다.
{m,n}은 앞선 패턴이 최소 m번, 최대 n번 반복되는 문자열을 의미한다. 콤마 뒤에 공백이 있으면 정상 동작하지 않음.
**예시 1. **
const target = "A AA B BB Aa Bb AAA";
// 'A'가 최소 1번, 최대 2번 반복되는 문자열을 전역 검색한다.
// 문자열 전체에서 매칭되는 모든 패턴을 배열로 반환하라는 뜻
const regExp = /A{1,2}/g;
// match()는 전체 문자열을 왼쪽부터 쭉 훑으면서 매칭되는 부분을 전부 추출
target.match(regExp); // -> ["A", "AA", "A", "AA", "A"]=> {n}은 앞선 패턴이 n번 반복되는 문자열을 의미한다. A가 1번 또는 2번 반복되는 부분을 찾음 => 'AAA'
- A{1,2}는 최대 2개까지만 잡아 → Greedy(탐욕적)하게 처음 2개 먼저 잡고
- 다음 한 개가 남으니까 또 검사해서 하나 더 잡음 → 'AAA'는 → 'AA' + 'A'로 나뉘어서 매칭됨
예시 2.
{n}은 앞선 패턴이 n번 반복되는 문자열을 의미한다. 즉 {n}은 {n, n}과 같다.
const target = "A AA B BB Aa Bb AAA";
// 'A'가 2번 반복되는 문자열을 전역 검색한다.
const regExp = /A{2}/g;
target.match(regExp); // -> ["AA", "AA"]예시 3.
{n,}은 앞선 패턴이 최소 n번 이상 반복되는 문자열을 의미한다.
const target = "A AA B BB Aa Bb AAA";
// 'A'가 최소 2번 이상 반복되는 문자열을 전역 검색한다.
const regExp = /A{2,}/g;
target.match(regExp); // -> ["AA", "AAA"]예시 4.
+는 앞선 패턴이 최소 한번 이상 반복되는 문자열을 의미한다. 즉, +는 {1,}과 같다.
const target = "A AA B BB Aa Bb AAA";
// 'A'가 최소 한 번 이상 반복되는 문자열('A, 'AA', 'AAA', ...)을 전역 검색한다.
const regExp = /A+/g;
target.match(regExp); // -> ["A", "AA", "A", "AAA"]예시 5.
?은 앞선 패턴이 최대 한 번(0번 포함)이상 반복되는 문자열을 의미한다. 즉 ?는 {0,1}과 같다.
const target = "color colour";
// 'colo' 다음 'u'가 최대 한 번(0번 포함) 이상 반복되고 'r'이 이어지는
// 문자열 'color', 'colour'를 전역 검색한다.
const regExp = /colou?r/g;
target.match(regExp); // -> ["color", "colour"]|은or의미를 갖는다. 다음 예제의 /A|B/는 A 또는 B를 의미한다.
const target = "A AA B BB Aa Bb";
// 'A' 또는 'B'를 전역 검색한다.
let regExp = /A|B/g;
target.match(regExp); // -> [ 'A', 'A', 'A', 'B', 'B', 'B', 'A', 'B' ]- 다음 예제는 or로 한 번 이상 반복하는 것인데 [] 내의 문자는 or로 동작한다. 그 뒤에 + 를 사용하면 패턴을 한 번 이상 반복한다.
const target = "A AA B BB Aa Bb";
// 'A' 또는 'B'가 한 번 이상 반복되는 문자열을 전역 검색한다.
// 'A', 'AA', 'AAA', ... 또는 'B', 'BB', 'BBB', ...
// const regExp = /A+|B+/g;
const regExp = /[AB]+/g;
target.match(regExp); // -> ["A", "AA", "B", "BB", "A", "B"]- 범위를 지정하려면 []내에
-를 사용한다.
const target = "A AA BB ZZ Aa Bb";
// 'A' ~ 'Z'가 한 번 이상 반복되는 문자열을 전역 검색한다.
regExp = /[A-Z]+/g;
target.match(regExp); // [ 'A', 'AA', 'BB', 'ZZ', 'A', 'B' ]- 대소문자를 구별하지 않고 알파벳을 검색하는 방법은 다음과 같다.
const target = "AA BB Aa Bb 12";
// 'A' ~ 'Z' 또는 'a' ~ 'z'가 한 번 이상 반복되는 문자열을 전역 검색한다.
regExp = /[A-Za-z]+/g;
target.match(regExp); // [ 'AA', 'BB', 'Aa', 'Bb' ]- 숫자를 검색하는 방법은 다음과 같다.
const target = "AA BB 12,345";
// '0' ~ '9'가 한 번 이상 반복되는 문자열을 전역 검색한다.
let regExp = /[0-9]+/g;
target.match(regExp); // ['12', '345']- 위 예제의 경우 쉼표 때문에 매칭 결과가 분리되므로 쉼표를 패턴에 포함 시킨다.
const target = "AA BB 12,345";
regExp = /[0-9,]+/g;
target.match(regExp); // ['12,345']\d는 숫자를 의미한다.
let regExp = /[\d,]+/g;
target.match(regExp); // ['12,345']
// \D는 숫자가 아닌 문자를 의미한다.
// 숫자가 아닌 문자 또는 ','가 한 번 이상 반복되는 문자열을 전역 검색한다.
regExp = /[\D,]+/g;
target.match(regExp); // [ 'AA BB ', ',' ]\w는 알파벳, 숫자, 언더스코어를 의미한다. 즉, \w는 [A-Za-z0-9_]와 같다.
const target = "Aa Bb 12,345 _$%&";
// 알파벳, 숫자, 언더스코어, ','가 한 번 이상 반복되는 문자열을 전역 검색한다.
let regExp = /[\w,]+/g;
target.match(regExp); // [ 'Aa', 'Bb', '12,345', '_' ]
// 알파벳, 숫자, 언더스코어가 아닌 문자 또는 ','가 한 번 이상 반복되는 문자열을 전역 검색한다.
regExp = /[\W,]+/g;
target.match(regExp); // [ ' ', ' ', ',', ' ', '$%&' ][...] 내의 ^ 은 not의 의미를 갖는다.
const target = "AA BB 12 Aa Bb";
// 숫자를 제외한 문자열을 전역 검색한다.
const regExp = /[^\d]+/g;
target.match(regExp); // [ 'AA BB ', ' Aa Bb' ][...]밖의 ^ 은 문자열의 시작을 의미한다.
const target = "https://naver.com";
// 'https'로 시작되는지 검사한다.
const regExp = /^https/g;
regExp.test(target); // true$ 는 문자열의 마지막을 의미한다.
const target = "https://naver.com";
// 'com'로 시작되는지 검사한다.
const regExp = /com$/g;
regExp.test(target); // true- [...] 바깥의
^은 문자열의 시작을 의미하고,?은 앞선 패턴이 최대 한 번(0번 포함)이상 반복되는지를 의미한다. - 검색 대상 문자열에 앞선 패턴(예시로는 's')이 있어도 없어도 매치된다.
const url = "http://example.com";
// 'http://' 또는 'https://'로 시작하는지 검사한다.
/^https?:\/\//.test(url); // true$ 는 문자열의 마지막을 의미한다.
검색 대상 문자열이 'html'로 끝나는지 검사
const fileName = "index.html";
/html$/.test(fileName); // true\d는 숫자를 의미하고 + 는 앞선 패턴이 최소 한 번 이상 반복되는 문자열을 의미한다.
즉, 처음과 끝이 숫자이고 최소 한 번 이상 반복되는 문자열과 매치한다.
const target = "12345";
//숫자로만 이루어진 문자열인지 검사한다.
/^\d+$/.test(target); // true\s는 여러 가지 공백 문자(스페이스, 탭 등)를 의미한다.
[\t\r\n\v\f]와 같은 의미이다.
const target = " Hi!";
//하나 이상의 공백으로 시작하는지 검사한다.
/^[\s]+/.test(target); // trueconst id = "abc123";
//알파벳 대소문자 또는 숫자로 시작하고 끝나며 4~10자리인지 검사한다.
/^[A-Za-z0-9]{4,10}$/.test(id); // trueconst email = "abc123@gmail.com";
/^[-0-9A-Za-z!#$%&'*+/=?^_`{|}~.]+@[-0-9A-Za-z!#$%&'*+/=?^_`{|}~]+[.]{1}[0-9A-Za-z]/.test(
email
); // trueconst cellPhone = "010-1234-5678";
/^\d{3}-\d{3,4}-\d{4}$.test(cellPhone); / / true;검색 대상 문자열에 특수 문자가 포함되어 있는지 검사한다. 특수문자는 A-Za-z0-9 이외의 문자다.
const target = "abc#123";
/[^A-Za-z0-9]/gi.test(target); // true다음 방식으로 대체해 사용할수도 있다. 이 방식은 특수 문자를 선택적으로 검사할 수 있다는 장점이 있다.
/[\{\}\[\]\/?.,;:|\)*~`!^\-_+<>@\#$%&\\\=\(\'\"]/gi.test(target); // true특수 문자를 제거할 때는 String.prototype.replace 메서드를 사용한다.
target.replace(/[^A-Za-z0-9]/gi, ""); // abc123### +) 정규표현식을 실무에서 어떻게 활용 가능한가? - 예: 사용자 입력 검증 (이메일, 전화번호, 비밀번호 등) - 텍스트 전처리 시 불필요한 HTML 태그 제거, 로그 분석 등
- https://regexper.com/
- 정규표현식의 표현 방법을 설명할 때 활용했던 도식 이미지를 제공해준 유틸리티 사이트이다. 별다른 설치 없이 누구나 이 사이트에서 직접 정규식을 만들어보고 자신의 목적에 맞게 구현되는지 도식과 함께 테스트 해볼 수 있다.