|
1 | | -# 将事件驱动的微服务与请求响应API集成 |
| 1 | +# 将事件驱动的微服务与请求响应API集成 |
| 2 | + |
| 3 | +## 0 前言 |
| 4 | + |
| 5 | +事件驱动微服务架构在当今非常流行,广泛采用的原因之一是它们促进了松耦合。 |
| 6 | + |
| 7 | +但使用基于请求/响应的通信也有很好的理由。如系统现代化过程中,有些系统已迁移到事件驱动架构,而有些系统还没。或你可能使用通过HTTP提供REST API服务的第三方SaaS解决方案。在这些情况下,将事件驱动的微服务与请求/响应API集成并不罕见。这种集成引入了新的挑战,因为带来紧耦合问题。 |
| 8 | + |
| 9 | +本系列分享在将事件驱动微服务与请求/响应API集成过程中学到的经验: |
| 10 | + |
| 11 | +- 实现幂等的事件处理(本文) |
| 12 | +- 解耦事件检索与事件处理(part2) |
| 13 | +- 使用断路器暂停事件检索(part3) |
| 14 | +- 限制事件处理的速率(part4) |
| 15 | + |
| 16 | +## 1 挑战:将事件驱动的微服务与请求/响应API集成 |
| 17 | + |
| 18 | +要理解为啥要实现幂等的事件处理,先关注事件驱动的微服务与请求/响应API的集成。 |
| 19 | + |
| 20 | +事件驱动通信是一种间接的通信方式,微服务通过生成和消费事件并通过类似AWS SQS这种中间件进行交换来相互通信。事件驱动的微服务通常实现一个事件循环,不断从中间件中检索事件并处理它们(有时称 [轮询消费者](https://www.enterpriseintegrationpatterns.com/patterns/messaging/PollingConsumer.html))。 |
| 21 | + |
| 22 | +## 2 代码示例 |
| 23 | + |
| 24 | + |
| 25 | + |
| 26 | +```java |
| 27 | +// 简化的事件循环 |
| 28 | + |
| 29 | +void eventLoop() { |
| 30 | + // 无限循环 |
| 31 | + while(true) { |
| 32 | + // 获取事件 |
| 33 | + List<Events> events = retrieveEvents(); |
| 34 | + for (Event event : events) { |
| 35 | + // 处理事件 |
| 36 | + processEvent(event); |
| 37 | + } |
| 38 | + } |
| 39 | +} |
| 40 | +``` |
| 41 | + |
| 42 | +将事件驱动的微服务与基于请求/响应的API集成,实际上意味着在事件处理过程中从事件循环中发送请求到API。当请求发送到API后,事件的处理会被阻塞,直到收到响应。然后,事件循环才会继续处理剩余的业务逻辑。 |
| 43 | + |
| 44 | +如下代码示例说明这点: |
| 45 | + |
| 46 | +```java |
| 47 | +// 集成请求/响应API的简化事件处理 |
| 48 | + |
| 49 | +void processEvent(Event event) { |
| 50 | + /* ... */ |
| 51 | + // 根据事件创建一个请求对象 |
| 52 | + Request request = createRequest(event); |
| 53 | + // 发送请求并等待响应 |
| 54 | + Response response = sendRequestAndWaitForResponse(request); |
| 55 | + // 处理事件和响应的进一步业务逻辑 |
| 56 | + moreBusinessLogic(event, response); |
| 57 | + /* ... */ |
| 58 | +} |
| 59 | +``` |
| 60 | + |
| 61 | +## 3 图解 |
| 62 | + |
| 63 | +描述了中间件、事件驱动的微服务和请求/响应API之间的详细交互: |
| 64 | + |
| 65 | +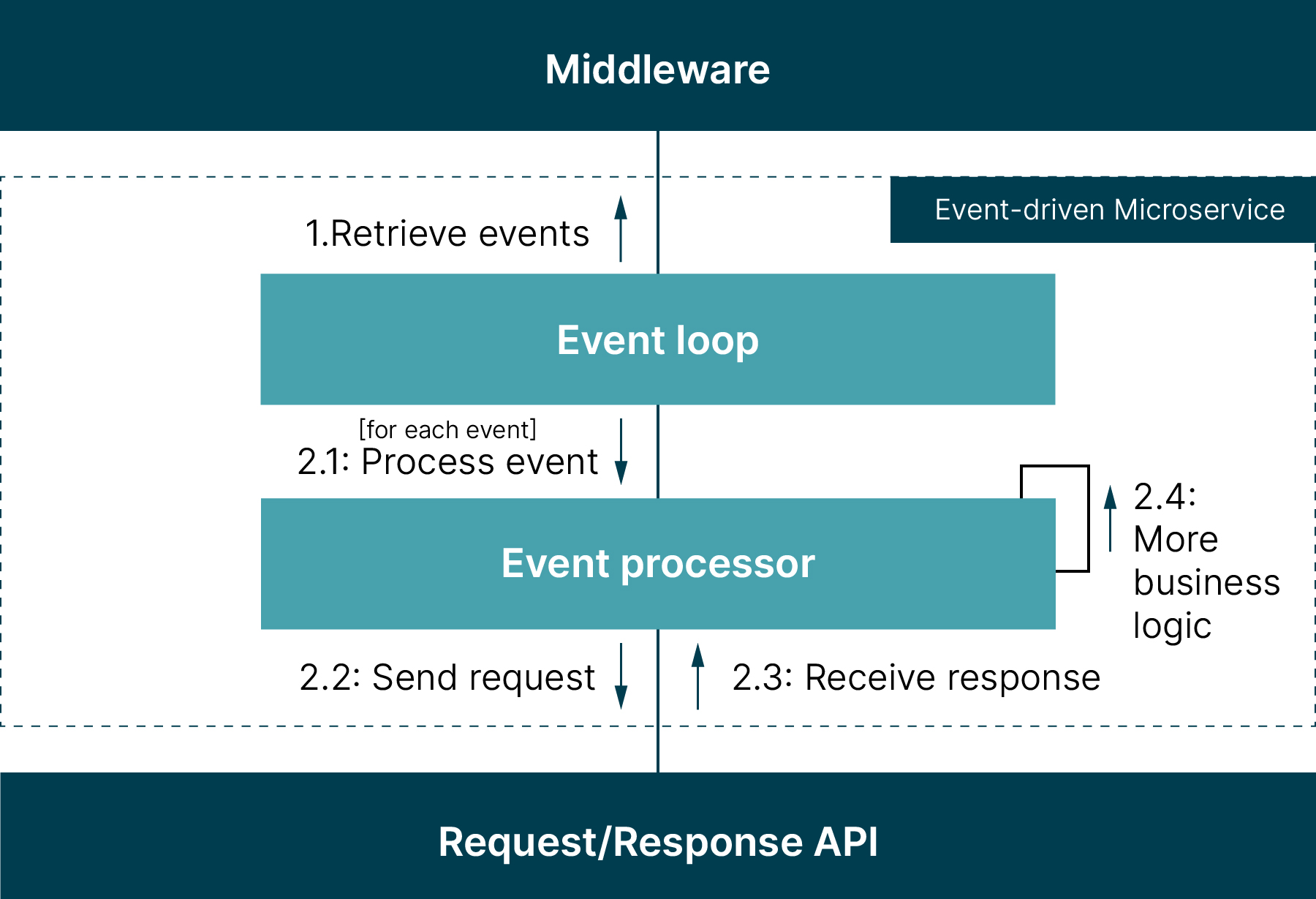 |
| 66 | + |
| 67 | +集成挑战在于两种不同的通信风格: |
| 68 | + |
| 69 | +- 事件驱动通信是异步的 |
| 70 | +- 而基于请求/响应的通信是同步的 |
| 71 | + |
| 72 | +事件驱动的微服务从中间件中检索事件,并以一种与生成事件的微服务解耦的方式处理这些事件。它还独立于生成微服务发出新事件的速度。这意味着,即使消费微服务暂时不可用,生成微服务也可以继续发出事件,而中间件则缓冲这些事件,以便稍后检索。 |
| 73 | + |
| 74 | +相反,基于请求/响应的通信是两个微服务之间的直接通信。如果上游微服务向下游微服务的请求/响应API发送请求,它会阻塞自己的处理,直到收到下游微服务的响应。这种紧耦合意味着两个微服务都需要可用。下游微服务的处理还会受到上游微服务发送请求速度的影响。 |
| 75 | + |
| 76 | +## 4 经验:实现幂等的事件处理 |
| 77 | + |
| 78 | +在处理事件驱动的微服务时,重试不可避免;某些事件会被多次消费。这是因为中间件通常提供某种程度的传递保证,如 [至少一次](https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/standard-queues.html) 传递(以AWS SQS为例),以及在处理失败或耗时过长时使用的重试功能(如 [可见性超时](https://docs.aws.amazon.com/AWSSimpleQueueService/latest/SQSDeveloperGuide/sqs-visibility-timeout.html))。 |
| 79 | + |
| 80 | +这就是为啥事件处理过程中需要考虑重试并使处理幂等化。即当一个事件被多次处理时,其结果应与处理一次时相同。通过实现 [幂等接收者](https://martinfowler.com/articles/patterns-of-distributed-systems/idempotent-receiver.html) 模式,可以忽略已成功处理的重复事件;这可以通过为事件赋予唯一标识符([幂等性键](https://stripe.com/docs/api/idempotent_requests))并在事件处理过程中存储和检查这些标识符来实现。 |
| 81 | + |
| 82 | +但根据经验,仅检测和忽略已成功处理的重复事件还不够。请求/响应API也应该幂等,以便能处理重复的请求。想象某请求由于网络不稳定而丢失或上游微服务没收到响应。如果API不是幂等,当再次发出请求时,重复请求可能会失败或产生错误的结果。 |
| 83 | + |
| 84 | +因此,最好解决方案是使请求/响应API幂等化。某些API操作(如GET或PUT)易实现幂等,而其他操作(如POST)则需要幂等性键和像幂等接收者这样的实现模式。如果你无法影响API的设计使其幂等化,至少在事件处理过程中需要考虑到这一点,以避免因使用非幂等API而导致的失败和错误结果。不过,是否考虑这点在很大程度上取决于API的设计。 |
| 85 | + |
| 86 | +### 示例 |
| 87 | + |
| 88 | +代码显示了一个响应重复请求时返回错误的集成请求/响应API。在这种情况下,重要的是识别重复错误和其他类型的错误。 |
| 89 | + |
| 90 | +考虑一个POST操作,它在处理重复请求时会返回422 UNPROCESSABLE_ENTITY错误,指出资源已经存在。错误响应中通常会包含进一步的信息,例如资源标识符,允许我们获取现有资源并继续业务逻辑。 |
| 91 | + |
| 92 | +```java |
| 93 | +// 在新资源创建失败时获取资源 |
| 94 | + |
| 95 | +void processEvent(Event event) { |
| 96 | + |
| 97 | + Response response; |
| 98 | + |
| 99 | + try { |
| 100 | + |
| 101 | + response = sendRequestAndWaitForResponse(create_Post_Request(event)); |
| 102 | + |
| 103 | + } catch(UnprocessableEntityException ex) { |
| 104 | + |
| 105 | + var resourceIdentifier = extractResourceIdentifier(ex.errorDetails()); |
| 106 | + |
| 107 | + response = sendRequestAndWaitForResponse(create_Get_Request(resourceIdentifier); |
| 108 | + |
| 109 | + } |
| 110 | + |
| 111 | + moreBusinessLogic(event, response); |
| 112 | + |
| 113 | + /* ... */ |
| 114 | + |
| 115 | +} |
| 116 | +``` |
| 117 | + |
| 118 | +## 5 结论 |
| 119 | + |
| 120 | +上述讨论表明,幂等的请求/响应API更容易集成。然而,非幂等的请求/响应API也可以以幂等的方式集成。如何集成非幂等API最终取决于上下文和API的设计。 |
| 121 | + |
| 122 | +无论API设计如何,重要的是通过提供合理的恢复选项来应对重复事件和重复请求。重试是不可避免的,事件处理包括请求/响应API应当是幂等的。 |
0 commit comments