| 模型名称 | lda_webpage |
|---|---|
| 类别 | 文本-主题模型 |
| 网络 | LDA |
| 数据集 | 百度自建网页领域数据集 |
| 是否支持Fine-tuning | 否 |
| 模型大小 | 31MB |
| 最新更新日期 | 2021-02-26 |
| 数据指标 | - |
-
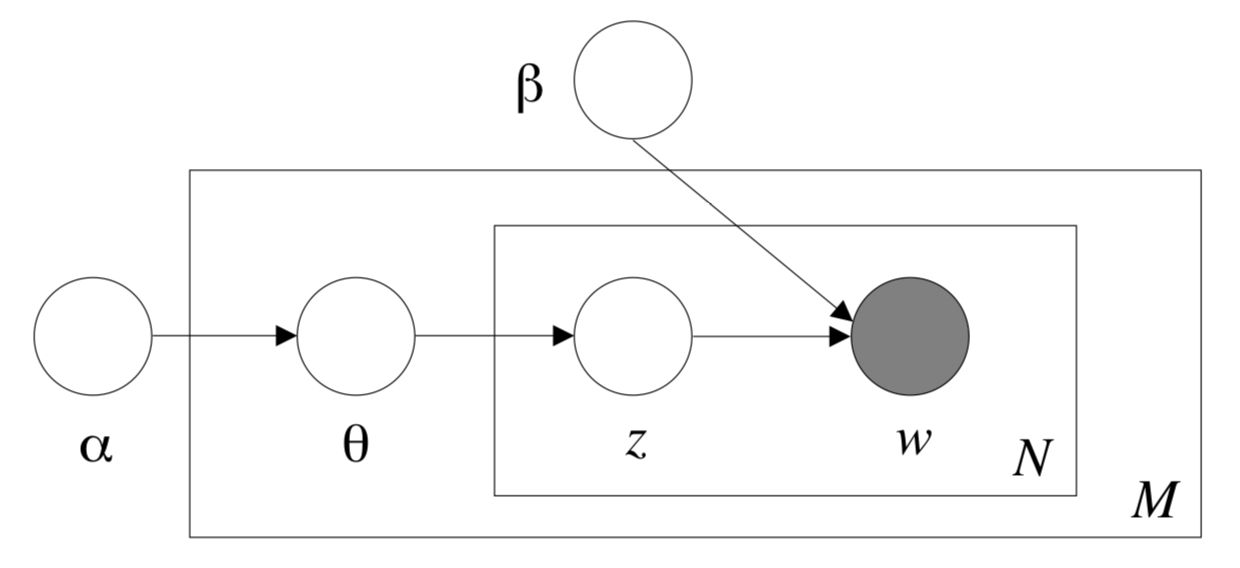
- 主题模型(Topic Model)是以无监督学习的方式对文档的隐含语义结构进行聚类的统计模型,其中LDA(Latent Dirichlet Allocation)算法是主题模型的一种。LDA根据对词的共现信息的分析,拟合出词-文档-主题的分布,从而将词、文本映射到一个语义空间中。
更多详情请参考LDA论文。
注:该Module由第三方开发者DesmonDay贡献。
-
-
paddlepaddle >= 1.8.2
-
paddlehub >= 1.8.0 | 如何安装PaddleHub
-
-
-
$ hub install lda_webpage
- 如您安装时遇到问题,可参考:零基础windows安装 | 零基础Linux安装 | 零基础MacOS安装
-
import paddlehub as hub
lda_webpage = hub.Module(name="lda_webpage")
jsd, hd = lda_webpage.cal_doc_distance(doc_text1="百度的网页上有着各种新闻的推荐,内容丰富多彩。", doc_text2="百度首页推荐着各种新闻,还提供了强大的搜索引擎功能。")
# jsd = 0.00249, hd = 0.0510
results = lda_webpage.cal_doc_keywords_similarity('百度首页推荐着各种新闻,还提供了强大的搜索引擎功能。')
# [{'word': '强大', 'similarity': 0.0838851256627093},
# {'word': '推荐', 'similarity': 0.06295345182499558},
# {'word': '新闻', 'similarity': 0.05894049247832139},
# {'word': '提供', 'similarity': 0.04179908620523299},
# {'word': '百度', 'similarity': 0.033778847361833536},
# {'word': '首页', 'similarity': 0.018429949496365026},
# {'word': '功能', 'similarity': 0.011409342579361237},
# {'word': '搜索引擎', 'similarity': 0.010392479335778413}]
out = lda_webpage.cal_query_doc_similarity(query='百度搜索引擎', document='百度是全球最大的中文搜索引擎、致力于让网民更便捷地获取信息,找到所求。百度超过千亿的中文网页数据库,可以瞬间找到相关的搜索结果。')
# out = 0.0283
results = lda_webpage.infer_doc_topic_distribution("百度文库非常的好用,我们不仅在里面找到需要的文档,同时可以通过续费畅读精品文档。")
# [{'topic id': 3458, 'distribution': 0.5277777777777778},
# {'topic id': 1927, 'distribution': 0.17777777777777778},
# {'topic id': 1497, 'distribution': 0.05},
# {'topic id': 1901, 'distribution': 0.03333333333333333}...]
keywords = lda_webpage.show_topic_keywords(3458)
# {'price': 0.10977647395316775,
# '文档': 0.06445075002937038,
# '财富值': 0.04012675135746289,
# '文库': 0.03953267826572788,
# 'len': 0.038856163693739426,
# 'tag': 0.03868762622172197,
# 'current': 0.03728225157463761,
# 'cut': 0.03448665775467454,
# '尺寸': 0.03250387028891812,
# '财富': 0.02902896727051734}https://github.com/baidu/Familia
-
-
cal_doc_distance(doc_text1, doc_text2)
-
用于计算两个输入文档之间的距离,包括Jensen-Shannon divergence(JS散度)、Hellinger Distance(海林格距离)。
-
参数
- doc_text1(str): 输入的第一个文档。
- doc_text2(str): 输入的第二个文档。
-
返回
- jsd(float): 两个文档之间的JS散度(Jensen-Shannon divergence)。
- hd(float): 两个文档之间的海林格距离(Hellinger Distance)。
-
-
cal_doc_keywords_similarity(document, top_k=10)
-
用于查找输入文档的前k个关键词及对应的与原文档的相似度。
-
参数
- document(str): 输入文档。
- top_k(int): 查找输入文档的前k个关键词。
-
返回
- results(list): 包含每个关键词以及对应的与原文档的相似度。其中,list的基本元素为dict,dict的key为关键词,value为对应的与原文档的相似度。
-
-
cal_query_doc_similarity(query, document)
-
用于计算短文档与长文档之间的相似度。
-
参数
-
query(str): 输入的短文档。
-
document(str): 输入的长文档。
-
返回
-
lda_sim(float): 返回短文档与长文档之间的相似度。
-
-
infer_doc_topic_distribution(document)
-
用于推理出文档的主题分布。
-
参数
- document(str): 输入文档。
-
返回
- results(list): 包含主题分布下各个主题ID和对应的概率分布。其中,list的基本元素为dict,dict的key为主题ID,value为各个主题ID对应的概率。
-
-
-
show_topic_keywords(topic_id, k=10)
-
用于展示出每个主题下对应的关键词,可配合推理主题分布的API使用。
-
参数
- topic_id(int): 主题ID。
- k(int): 需要知道对应主题的前k个关键词。
-
返回
- results(dict): 返回对应文档的前k个关键词,以及各个关键词在文档中的出现概率。
-
-
-
-
1.0.0
初始发布
-
1.0.1
修复因为return的bug导致的NoneType错误
-
1.0.2
修复由于Windows
gbk编码导致的问题