Description
- is my vision and proposal aligned with qwik?
- if so, would these feature implementable? (I can contribute code
- if still, how long would them land?
Is your feature request related to a problem?
I'm using qwik 0.19.2, qwik-city 0.4.0, latest version as of writing
qwik recently introduced server$(...), along with the already existing action$(...)
Iet's focus on server$(...) first, because I think that is where the future is headed :)
it currently has the following problems:
- (easily fixable) any exception in the code block crashes the entire server, instead of sending the exception back to client(of course the user can choose to inhibit the exception detail for security reasons
- it would convert
lettoconstwhen capturing scoped values, so it's actually not really a server-side function, it may be called a server-side class, all it's state is still serialized to and coming back from the client, no server-side state, just a syntactic sugar around XHR

- a even more dire problem, is that qwik seems been sending captured server values to client, which is extremely unsafe, and it seems been reading code pointer from client and executing them on server? which is even more unsafe -.- with sufficiently large codebase, this may even allow full remote control of the server(ROP like attacks
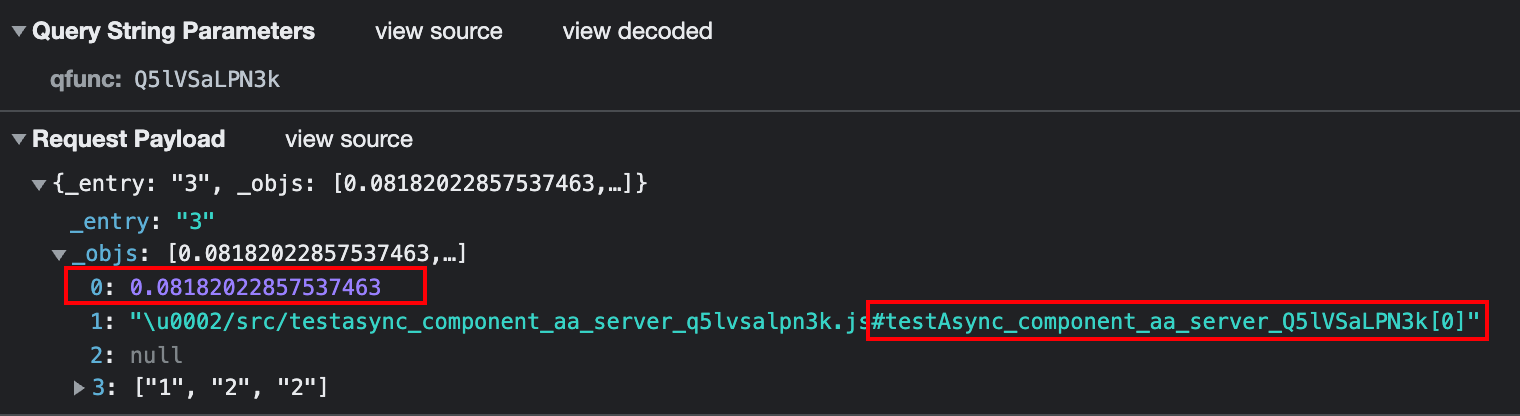
but as for now I didn't fully understand how this new server$(...) thing works internally, so I may be wrong. and I've seen somewhere else forget where, that (manucorporat) mentioned there are still some serialization problems, maybe that can be fixed(though I highly doubt that under the current architecture
- (a little far fetched) I think the current implementation of
server$(...)is still a endpoint like request/response http thing, if you really think about it, it's just syntactic sugar around jsonp. we didn't really bringserver-side resumabilityto the table, more on what I mean at the end of the article
why I'm not talking about action$(...)?
in my opinion, it has many fatal design flaws, even compared to server$(...)
from the source code, action$(...) seems to be registering itself to globalThis, this immediately raises several red flags for me:
- it only adds to the map but never removes them, so... memory leaks? (and under the current architecture that may be unfixable
- wow, it was registering itself to a map, so... single backend instance only? even if no LB or we configure the LB to do consistent routing -- which is a bad practice all by itself -- the backend server couldn't restart without losing state
- it's api surface was too complex, even seems entirely bound to
form. I think a more clean and atomic interface likeserver$(...)would be more appropriate, I don't know how many people still useformthese days
Describe the solution you'd like
I would show my gratitude to qwik first. I'm a system architect, so instead of feature I would also constantly thinking about scaleability, security and that kind of stuff. I've done enough frontend development that these days I normally won't write more frontend code, as that would add little to my knowledge base, but more of repetitive work and reinvention of the same wheel(no offence). but qwik really caught me! in years of my frontend chore, that was something new! that I was excited, that I think can be the future of frontend development
but qwik did more, it seems it can bring resumability to the server
I've used a lot ancient tech(asp.net runat=server, jsonp, php, someother server-side function etc.
so server$(...) is not new, but all those ancient tech -- maybe limited by their time -- never show me the possibility to really bring resumability to the server, they all seems just syntactic sugar around XHR. qwik -- along with it's compiler -- the ability to segregate code blocks and capture, serialize scoped values -- may finally be able to do:
server-side resumability
qwik currently suspends in SSG and resumes in browser, server-side resumability is like doing that in reverse. but it faces more challanges:
- browser can somewhat "trust" server data, because browser possesses no more secure data than the server(except for e2e security, but that is not really secure), and it's already running in a sandbox. the server however can't trust browser data or leak any data to them
- browser can be thought of a single threaded process(though in fact they may not necessarily be), but the server is inherently multi-process distributed systems
I propose the following solution

const capturedScopeValue=...,scopeValue=...
const coroutine=coroutine$(async(initialReqCtx)=>{
let localValue=thisCodeRunsInServer()
await yieldToBrowser(config)
console.log(localValue) // ok, logs in browser
console.log(capturedScopeValue) // ok, the data is serialized and sent to browser
// localValue++ // won't work, the value is captured, thus in server-only
// capturedScopeValue++ // won't work, the value is captured, thus in server-only
let browserValue;
await new Promise((resolve)=>button.once("click",()=>{browserValue=1;resolve()}))
await resumeInServer(config)
console.log(browserValue) // ok, logs in server
// browserValue++ // won't work, the value is captured, thus in browser-only
capturedScopeValue++ // works
scopeValue++ // works
localValue++ // works
},defaultConfigForYieldToBrowserAndResumeInServer)notice a few things in the code:
- not single-shot request response, but multi-trip conversational
scopeValuenever send to client,browserValueis the only one coming from browser,capturedScopeValue,scopeValue,localValueis captured and send to client, but not read back from client, theyresumein server- each context switch(server <-> browser) involves an
awaitand aconfig(if not provided,defaultConfigForYieldToBrowserAndResumeInServeris used, if that is not provided, a default implementation is used
the so called config customizes three aspect of server-side resumability, highlighted in red in the above diagram
externalizer1:(ctx,...variableInfo)decides how variables(state) are serialized. it can, for example, detectscopedValueis non-local(throughvariableInfo), and write it to redis, only returning its redis key. the key, instead of data, is then send to browser, thus leaking no information(the key can be mangled and recovered only throughinternalizer1, thus the browser gains no knowledge). it can also detect thatcapturedScopeValueis non-local, allowing it's value to be send to the browser, optionally transform the value in the process(filter some fields etc), while also saving it to redis. the default implementation does nothing special, just leave the value in process memory. forlocalValue, the default implementation sends the mangled identifiers to browser, on resume it uses the ones recovered from the mangled identifiers, not the browser sent one. the mangled identifiers also have internal checks to prevent identifier remangle or reuse attacksexternalizer2adds extra routing information to the resulting url, thus when browser sends back request, LB can see its routing value and route the request to the original backend instance(or any other instance the LB deems appropriate). the default implementation adds nothing to the urlversioningadds extra versioning information to the resulting url, thus when browser sends back request, a user-controlled(thoughconfig.versionCheck:(...)=>boolean) verifier is run, to decide if the code is runnable on the server. the default implementation adds script build time to the url and it must match exactly with the browser send back one to continueinternalizer1recovers variables(state) fromexternalizer1, thus complete the server-side resumability story full-circle. it can choose to recovercapturedScopeValueand/orscopeValuefrom process memory(they may have been changed by now) or from redis. the default implementation try to recover them from process memory. it should also considerlocalValueas if resumed in a different server process,localValuehave to be recovered too. the default implementation try to recover them first from injection made byinternalizer2, then from process memory, minimizes the security risk, and if server resumed in different process, error. notice the different behavior for local and non-local valuesinternalizer2can run in LB or qwik, (re)routes request based on url'sexternalizer2route value, optionally injects data to be recovered byinternalizer1
Describe alternatives you've considered
implement server-side resumability directly, use qwik only to pass identifier references(like cookies), or entirely without qwik(use XHR or websocket directly
Additional context
No response