|
| 1 | +# 基于zksnark的可验证计算 |
| 2 | + |
| 3 | +## 背景 |
| 4 | + |
| 5 | +目前区块链瓶颈是达成共识的速度有限制的,如何扩容成为现在区块链技术的研究热点。 |
| 6 | +限制扩容的因素主要两个方面: |
| 7 | +1. 单节点的处理能力有限,而且每笔交易都需要各节点验证计算 |
| 8 | +2. 区块链数据增长速度过快。 |
| 9 | + |
| 10 | +本文针对第一个问题提出一种可验证计算(VC)智能合约的解决方案,主要思想是用户将复杂合约的计算外包给第三方,第三方具有强大的计算处理能力,他的计算成本低于用户自己直接计算的成本, 计算后,将结果和相应的计算正确证明上链验证,验证计算的速度成本都远低于直接计算,这样就可以扩展单节点的计算能力,而且不损失安全性。 |
| 11 | +可验证计算这个概念是1991年提出,业内也提出了很多算法模型,直接应用在区块链上却有很多限制,比如需要减少交互,降低证明长度,优化验证计算速度和内存消耗等等,zksnark是目前 |
| 12 | +应用在区块链上较成功的解决方案,zcash使用zksnark可以在隐去交易账户金额的情况下验证交易有效性,其主要是为了不泄露用户数据的情况下进行可验证计算,本文的VC合约是使用zksnark解决复杂合约计算如何外包给链下第三方计算,可以在链上方便验证计算,从而实现单节点处理能力的扩容。 |
| 13 | + |
| 14 | +## zksnark介绍 |
| 15 | +zk-SNARK是“zero knowledge Succinct Non-interactive ARgument of Knowledge”的缩写,这一长串名字的主体是“argument of knowledge”,即“知情证明”,也就是掌握某事内幕的证据。修饰主体名词的定语由三部分组成,分别代表了此技术要解决的三个问题,分别是: |
| 16 | + |
| 17 | +* zero knowledge:零知识,即在证明的过程中不透露任何内情; |
| 18 | +* succinct:简洁的,主要是指验证过程不涉及大量数据传输以及验证算法简单; |
| 19 | +* non-interactive:无交互。最初的版本是在证明者和验证者之间进行大量的交互才能完成证明,最新版本通过设置公共可信区域减少了大量交互 |
| 20 | + |
| 21 | +### zksnark是如何工作的 |
| 22 | +#### 将目标问题转化为二次计算方程(QAP) |
| 23 | +例如求解 x<sup>3</sup> + x +5 = 35 |
| 24 | +假设Alice知道x=3是解,但不想泄露给Bob,同时又要证明她知道这个方程式的解。 |
| 25 | + |
| 26 | +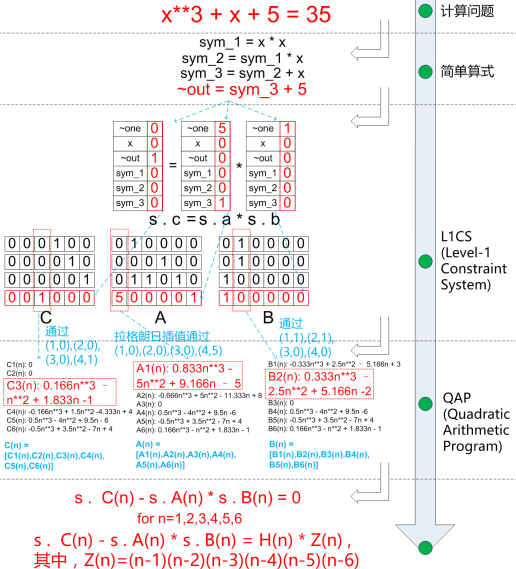 |
| 27 | + |
| 28 | +1. 将计算方程 拍平转化为各种简单算式(类似电路的逻辑门) |
| 29 | +2. 将简单算式转化为一级约束系统(R1CS):一个R1CS是一组三向量(a, b, c)构成的一个序列。假设R1CS的解是一个向量s,那么s必须满足这个等式s·a×s·b - s·c = 0,这里的·代表向量的点乘。a、b和c是其系数向量,依次完成所有简单算式的转化,将系数向量分别顺序排列,便得到A、B和C三个矩阵。 |
| 30 | +每个逻辑门对应一个gadget,gadget里面定义了相应的约束和产生证明witeness方法,我们也可以定制复杂逻辑门,例如mod,compare等运算,可以由多个约束组成。 |
| 31 | +每个向量的长度等于这个系统中所有变量的个数,同时也包括代表1的变量~one,我们把它放在向量第一个索引位置;还包括代表输出的~out,以及中间变量(上面的sym_1, sym_2,sym_3)。这些向量通常比较稀疏,只在逻辑门相关的变量位置才有值,其他地方都为0。 |
| 32 | +上图中向量s即可映射为: |
| 33 | + *[~one, x, ~out, sym_1, sym_2,sym_3]* |
| 34 | +满足所有约束条件的向量s就是问题的解,也就是witness: |
| 35 | + *[1, 3, 35, 9, 27, 30]* |
| 36 | +3. 将R1CS转化为QAP |
| 37 | + 根据上面获得的A,B,C矩阵,通过拉格朗日插值的方式得到A,B,C的插值多项式表示A(n),B(n),C(n) 。 |
| 38 | +求得多项式向量A(n)、B(n)和C(n)后,计算问题便转换为求取解向量s, |
| 39 | +使得等式s . C(n) - s . A(n) ×s . B(n) = 0 在n=1,2,3,4,5,6时成立,等价于:s . C(n) - s . A(n) ×s . B(n) = H(n) ×Z(n),其中, Z(n) = (n-1)(n-2)(n-3)(n-4)(n-5)(n-6) |
| 40 | + |
| 41 | +#### 抽样实现简洁验证 |
| 42 | +上面完成一系列转化后,问题求解,就变成求解满足s . C(n) - s . A(n) × s . B(n) = H(n) * Z(n)的解。 |
| 43 | +Alice可以用她知道的解s,计算多项式P(n)和H(n) = P(n)/Z(n),然后将两个多项式P(n)、H(n)发给验证者Bob;后者通过检查P(n) ?= H(n) ×Z(n)是否成立来判断Alice是否真的知道解。 |
| 44 | +这种方式没有泄露s,但由于多项式的度往往比较大,导致传输和计算非常耗时,实际不可取,当然还有一个因数是没法确定P(n)是由s . C(n) - s . A(n) × s . B(n)组成。 |
| 45 | +因此除了不泄露解,还需要让验证的时候更简洁。zksnark采用抽样验证的方式简化验证,即Bob随机选择一个t,发送给Alice,计算出P(t),H(t)的值,将值传给Bob验证。 |
| 46 | +如下所示: |
| 47 | +1. Bob任意选择一个点n = t发给Alice,这个点称为抽样点 |
| 48 | +2. Alice计算P(t)和H(t); |
| 49 | +3. Alice把P(t)和H(t)发还给Bob; |
| 50 | +4. Bob检查P(t) ?= H(t)×Z(t) |
| 51 | + |
| 52 | +这种验证方式,Bob可以大概率确定Alice知道解,之所以大概率是Alice存在一种可能,知道另一个解,使得P(t) ?= H(t)×Z(t)成立,但这个概率是非常小的。 |
| 53 | +假设A,B,C的度为d,则p(n)的度为2d,两个不等价的多项式交点数量最多只有2d个,2d相较于有限域的元素个数n来说很小的情况下,Alice随意选择t使多项式P(x)被校验通过的概率只有2d/n。 |
| 54 | + |
| 55 | +#### 同态隐藏 |
| 56 | +由于暴露了t给Alice,Alice同样可以构造P'(t),H'(t)使得 H'(t) = P'(t)/Z(t)成立。 |
| 57 | +因此抽样点t不能让Prover(Alice)知道,同时还得让Prover能给出抽样点处的值,zksnark是通过同态隐藏的方式做到这一点的。 |
| 58 | +“同态隐藏”是输入x到输出X的某种映射(mapping)E的特性: |
| 59 | + |
| 60 | +>对于绝大多数的x,已知X=E(x),无法推导出x; |
| 61 | +如果x1≠x2,则E(x1)≠E(x2); |
| 62 | +E(ax1+bx2) = a * E(x1) + b * E(x2) |
| 63 | + |
| 64 | +Bob不再直接将抽样点告知Anna,而是提供了t的一系列指数t0、t1、t2、t3...tN的映射值E(1)、E(t1)、E(t2)、E(t3)...E(tN) |
| 65 | +如下所示: |
| 66 | +1. Bob计算E(1)、E(t1)、E(t2)、E(t3)...E(tN)发给Alice; |
| 67 | +2. Alice计算E(P(t))和E(H(t)); |
| 68 | +3. Alice把E(P(t))和E(H(t))发还给Bob; |
| 69 | +4. Bob检查E(P(t)) ?= E(H(t))×E(Z(t))(t的值,Bob知道,因此可以算出z(t)=a,从而算出E(aH(t))) |
| 70 | + |
| 71 | +#### KCA |
| 72 | +假设Prover不知道使"s . C(n) - s . A(n) ×s . B(n) = H(n) * Z(n)"成立的解s,但知道另一个问题的解s':"s' . C'(n) - s' . A'(n)× s' = H'(n) ×Z(n)"。 |
| 73 | +Prover便可用不同于原始问题的系数向量A'(n)、B'(n)和C'(n)来生成"P'(n) = s . C'(n) - s . A'(n) ×s . B'(n)",然后发给Verifier验证。 |
| 74 | +Verifier如何才能知道Prover计算P(n)使用的是不是规定的系数向量A(n)、B(n)和C(n)呢?这一过程便称为KCA(Knowledge of Coefficient Test and Assumption)。 |
| 75 | +原理如下: |
| 76 | +先定义: |
| 77 | +> α对是指满足"b=α×a的一对值(a,b),乘法是椭圆曲线乘法,具备两个特性: |
| 78 | +一是当α值很大的情况下,很难通过a和b倒推出α, |
| 79 | +二是加法和乘法满足可交换群的特性 |
| 80 | + |
| 81 | +我们利用α对的特性,构建一个称为KCA(Knowledge of Coefficient Test and Assumption)的过程: |
| 82 | +>1. B随机选择一个α生成α对(a,b),α自己保存,(a,b)发送给A |
| 83 | +2. A选择γ,生成(a′,b′)=(γ⋅a,γ⋅b),把(a′>,b′)回传给B。利用交换律,可以证明(a′,b′)也是一个α对,b′=γ⋅b=γα⋅a=α(γ⋅a)=α⋅a′ |
| 84 | +3. B校验(a′,b′),证实是α对,就可以断言A知道γ |
| 85 | + |
| 86 | +推广到多个d-KCA: |
| 87 | +>1. B发送一系列的α对给A |
| 88 | +2. A使用(a′,b′)=(c1⋅a1+c2⋅a2,c1⋅b1+c2⋅b2)生成新的α对 |
| 89 | +3. B验证通过,可以断言A知道c数组 |
| 90 | + |
| 91 | +回到开始的问题:Alice(Prover) 可以构造和A(n)、B(n)和C(n)无关的多项式P'(n)来满足等式,因此我们可以在上一节的例子中改进为,Bob只将E(A(t)),E(B(t)),E(C(t))的值发送给Alice,Alice只能基于这些值构建E(P(t))。 |
| 92 | + |
| 93 | +#### 双线性映射(bilinear map):乘法的同态隐藏 |
| 94 | +在上面的KCA验证中,需要验证E(αA(t))=αE(A(t))涉及到乘法运算,而α在构建可信参数的时候已经被丢弃,所以如果想做到乘法的同态隐藏了,那就需要用到双线性映射。 |
| 95 | +上面介绍的同态隐藏是一对一的,即将一个输入映射到一个输出。而双线性映射是将分别来自两个域的两个元素映射到第三个域中的一个元素:e(X, Y) → Z,同时在两个输入上都具备线性: |
| 96 | +>*e(P+R, Q) = e(P, Q) + e(R, Q)* |
| 97 | +>*e(P, Q+S) = e(P, Q) + e(P, S)* |
| 98 | +
|
| 99 | +假设对于x的任意两种因数分解(a, b)和(c, d)(即x=ab=cd),存在两个加法同态映射E1和E2,以及一个双线性映射e,使得以下等式总是成立: |
| 100 | +>*e(E1(a), E2(b)) = e(E1(c), E2(d)) = X* |
| 101 | +
|
| 102 | +那么,x->X的映射也是加法同态映射。 |
| 103 | +由上我们得出了 乘法的同态隐藏公式: |
| 104 | +>*E(xy) = e(E1(x), E2(y))* |
| 105 | +
|
| 106 | +根据如上公式: |
| 107 | +为了验证π<sup>'</sup><sub>A</sub>?= απ<sub>A</sub>,我们可以转化为验证e(π<sub>A</sub>, E2(α)) ?= e(π<sup>'</sup><sub>A</sub>, E2(1))(B,C同理)。 |
| 108 | + |
| 109 | +#### 零交互 |
| 110 | +在上面的例子中,我们需要Bob发送大量的E(A(t)),E(B(t)),E(C(t))序列给Alice,这个数据量是非常巨大的,传输很耗时,也不够简洁,如何解决这一问题: |
| 111 | +zksnark把Bob发给Alice的一大坨数据E(A(t)),E(B(t)),E(C(t)) 变成所谓的“共同参考数据集”(CRS,Common Reference String),通过某种可信的方式产生,作为一种全体节点的共识,在所有交易的验证过程中使用,因而“质询-响应”的交互式验证方式变成了只需要Proof提交证据即可。 |
| 112 | + |
| 113 | +## VC合约 |
| 114 | +### VC架构图 |
| 115 | + |
| 116 | + |
| 117 | +* vc-contract template:用户根据vc提供的模板编写vc合约,可以输入任意计算模型,主要实现三个接口: |
| 118 | + 1. compute():计算请求 |
| 119 | + 2. real_compute() :生成计算结果和证明 |
| 120 | + 3. set_result():验证计算结果和证明 |
| 121 | +* vclang: 将用户编写的vc合约编译,生成wasm vm支持的执行文件,合约开发者无需关心具体的libsnark api使用方法,只需编写好自己的计算模型代码即可 |
| 122 | +* vcc-reslover: 在wasm虚拟机中预置支持访问libcsnark api的接口层,以c-go的方式调用libcsnark接口 |
| 123 | +* libcsnark: 封装libsnark api,将c++实现的libsnark 可以由c接口访问 |
| 124 | +* vc_pool: 负责vc的交易处理,分发vc计算任务,并将计算结果和证明上链 |
| 125 | + |
| 126 | +### VC合约编译 |
| 127 | +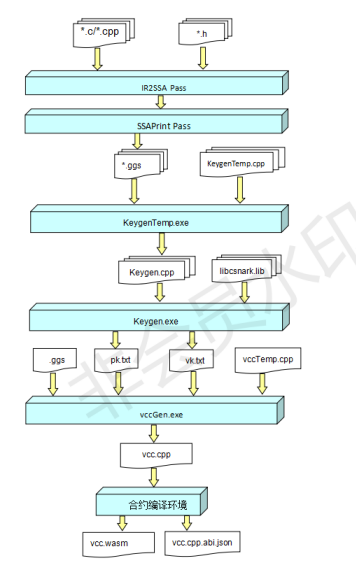 |
| 128 | + |
| 129 | +1. 将用户程序编译生成的IR序列,转化为SSA,最终转化为libcsnark支持的gadget表示ggs |
| 130 | +2. 将ggs,和keygenTemp.cpp,结合生成keygen |
| 131 | +3. vclang通过keygen生成pk,vk(CRS构建),这个过程会进行大量的椭圆曲线乘法运算,产生pk,vk之后序列化至合约模板中,pk是用来生成证明的可信参数,vk是验证用到的可信参数 |
| 132 | +4. vclang再将pk,vk序列化至vccTemp.cpp中生成vcc.cpp |
| 133 | +5. vclang编译生成vcc.cpp生成vcc.wasm |
| 134 | + |
| 135 | +### VC合约是如何工作的 |
| 136 | +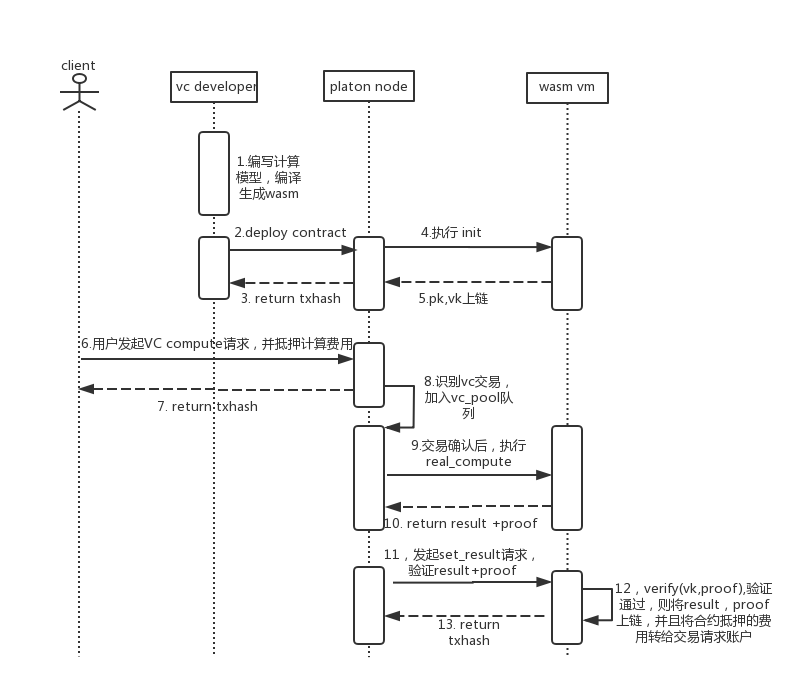 |
| 137 | + |
| 138 | +**主要过程说明:** |
| 139 | +1. 合约编译之后,已经生成了pk,vk, 部署至platon网络之后,pk,vk存储至链上,无法被篡改,可方便节点访问 |
| 140 | +2. 当vc compute 交易执行时,会创建一个vc task,taskid由tx的nonce组成,并以taskid为key,存储输入参数x. |
| 141 | +3. compute交易写入区块之后,会触发 vc_pool解析交易event,从而决定是否将task加入vc_pool的队列中 |
| 142 | +4. 等待20个区块确认之后,就可以开始执行real_compute,由于是链下计算,不会产生交易费用。real_compute的过程是首先根据执行此前编译生成的gadget序列运算产生s(witness),一旦计算出s,就可以根据pk,计算出证明π<sub>A</sub>,π<sub>B</sub>,π<sub>C</sub>等系列,即是proof |
| 143 | +5. set_result(proof,result)是将计算结果和证明上链,该过程主要是verify(vk,proof,input),一旦验证通过,则交易发起者可获取计算酬劳。zksnark的verify的时间相对产生proof的阶段比较短,但也是和输入参数长度相关,所以需要注意限制输入参数长度,防止该笔交易的gas费用过高,增加验证者成本 |
| 144 | + |
| 145 | + |
| 146 | +### 合约的激励模型 |
| 147 | +有计算外包需要的用户,需要先抵押合适费用至合约账户,platon各节点可自行竞争计算任务,一旦计算成功,生成结果和证明,就发起set_result交易请求,需要计算节点先支付该笔交易的矿工费,节点收到请求,执行set_result,一旦验证通过交易中携带的proof和result参数,则认为交易请求者成功计算出结果,会将合约账户抵押的费用转账至请求者账户中,失败则不会给以激励。 |
| 148 | + |
| 149 | +## 方案分析 |
| 150 | +### 性能分析 |
| 151 | + |
| 152 | +| 运算阶段 | 运算 | 用户 | 计算节点 | |
| 153 | +| ------------ | ------------ | ------------ | ------------ | |
| 154 | +| keygen构建 | 指数| O(m+n) | 0 | |
| 155 | +| real_compute| 指数| 0 | O(m) | |
| 156 | +| set_result| 双线性配对运算 ,指数| O(1),O(n) | 0 | |
| 157 | + |
| 158 | +m为A,B,C多项式的度,n为输入参数长度 |
| 159 | +1. keygen构建:将抽样值进行同态隐藏生成可信参数,由于m往往较大,而且是指数运算,时间也比较长,但该过程是在合约编译阶段进行,所以不会影响合约运行阶段性能 |
| 160 | +2. real_compute :需要做O(m)次的指数运算生成witness和proof,该过程可以分发至链下第三方进行快速运算 |
| 161 | +3. set_result :verify根据输入生成proof的组成部分,需要o(n)次指数运算,然后使用固定次数双线性配对运算做验证,该过程是在链上完成,因此需要优化其执行时间,确保在一个可接受的计算成本范围 |
| 162 | + |
| 163 | +#### 性能对比: |
| 164 | +| | time(Setup) | key len(Setup) | time(Proving) | memory(Proving) | time(Verifying) | proof len(Verifying) | |
| 165 | +| ------------ | ------------ | ------------ | ------------ | ------------ | ------------ | ------------ | |
| 166 | +| zk-SNARK | ~28min | ~18GB | ~18min | ~216GB | <10ms | 230B | |
| 167 | +| zk-SNARK(Zcash-Sprout)| ~27hr(6 player) | ~900MB | ~37s | ~1.5GB | <10ms | ~300B | |
| 168 | +| zk-SNARK(Zcash-Sapling) | months-MPC | <800MB | ~7s | ~40MB | <10ms | ~200B| |
| 169 | +| zk-STARK | <0.0.1s | 16B | 6min | 131GB | ~0.1s | ~1.2MB | |
| 170 | +| Bulletproof | | | 2min | ~1MB | ~3s | ~1.5KB | |
| 171 | +| ZKBoo() | | |~33ms |~MBs | ~38ms | ~200KB | |
| 172 | +| Ligero() | | | ~140ms | ~MBs | ~60ms | ~34KB | |
| 173 | +#### 优化措施: |
| 174 | +//TODO |
| 175 | +全局优化: |
| 176 | +1. 主要是优化椭圆曲线加密的运算速度,zcash-Sapling即采用了一种Jubjub椭圆曲线,大大提高了乘法运算速度 |
| 177 | +2. 提高wasm vm的执行速度 |
| 178 | + |
| 179 | +验证阶段优化: |
| 180 | +1. 预处理双曲线配对运算,预置中间值,无需重复计算 |
| 181 | +2. 对输入参数长度优化 |
| 182 | + |
| 183 | +### 安全分析 |
| 184 | +主要在第一阶段可信参数的构建阶段,该过程会生成椭圆曲线加密所需的α值,抽样点t,这些参数一旦被黑客获取,则可以随意构造proof,骗取计算费用 。因此必须保证可信参数生成的随机性,且不能泄露。 |
| 185 | + |
| 186 | +## 总结 |
| 187 | +基于zksnark,提出了一种区块链lay2扩容方案,合约编写者将计算方程式编写为VC合约,部署至区块链,计算需求方发送计算请求,并输入参数,各节点收到VC任务后,竞争执行链下计算,将计算结果发布区块链,任意节点都可以验证计算结果的正确性,而且验证的计算量远小于直接计算方程。 |
0 commit comments