数组实现的顺序表,在内存中是顺序存储的,属于顺序存储结构
它有一些特点
- 动态扩容:在达到最大容积之前,它会根据元素的数量来进行动态拓展或者收缩
- 非线程安全:非并发安全容器,即多线程条件下的读写并不安全
- 可变:列表元素可以增加、删除以及修改
由于使用索引访问数组时间复杂度是O(1),故基本上所有的操作都会先去获取元素的索引下标。
顺序表对元素的访问主要有两种方式:按值和按照索引
因为顺序表使用数组作为存储结构,其在内存中是连续存储的。因此,根据索引访问元素是常数时间,即O(1).
访问索引下标为3的元素,其起始地址为 a和起始下标为 1,单个元素的地址长度为 p。则该元素在内存中的地址为a+(3-1)*p。
这个问题可以归根于对元素的查找,对于线性表这种结构,按值访问,其实是先查询元素所在的索引,在按照索引访问。常规的实现方式是遍历对比,其时间复杂度为 O(N).
也有一些特例,对于有序列表,其时间复杂度可以采用二分法等进行优化到 O(logN).
常规的实现方式如下:
int index_of_array(Element e, ArrayList *array, compare_func cmp)
{
for (int i = 0; i < array->length; ++i)
{
if (cmp(e, array->elements[i]) == 0)
{
return i;
}
}
return -1;
}列表元素的增加,都会更新列表的长度,当长度放大到某个阈值时,列表的容积也会相应的放大,以便更加高效的利用内存空间。
扩容因子,即当容积不足时,容积拓展的速率。默认是x1.5
array->length +(array->length>>1) 当然,一般也不是无限拓展的,因为当一个表元素很多的时候,它的查找和插入、删除效率就会降低。因此一般会给一个最大扩充数量。比如 1<<64 最大整数值。
初始容积是10,下面给出插入0-11元素的过程:
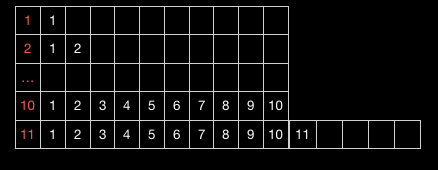
再插入第11个元素时,由于容积不足,故将其扩充到原来的1.5倍。
void array_list_extend(ArrayList *array, unsigned int new_cap)
{
if (new_cap <= array->capacity)
{
return;
}
Element *data;
data = realloc(array->elements, new_cap * sizeof(Element));
if (data == NULL)
{
return;
}
else
{
array->elements = data;
array->capacity = new_cap;
}
}元素在指定位置进行插入操作,插入时,该索引之后的数据要全部后移一位,同时注意这里可能存在扩容操作。适合倒序遍历,然后元素之间相互交换。
/**
* insert the element in array;
* */
void push_index(Element e, unsigned int index, ArrayList *array)
{
if (array->length == array->capacity)
{
array_list_extend(array, array->length +(array->length>>1) );
}
/* Move back the entries following the range to be removed */
memmove(array->elements[index + 1], array->elements[index], (array->length - index) * sizeof(Element));
array->elements[index] = e;
++array->length;
}注意,默认插入是在列表的结尾,这样可以提高效率。
删分为两种操作,删除指定索引的元素以及删除指定值的元素。其实第二种,可以看作是先查出指定值的索引下标,在进行删除。
删除操作的主要逻辑是,将指定索引下标之后的数据向前移位,并把最后一个元素置空。
进一步抽象为删除连续下标的一些列值
void delete_many(unsigned int index, unsigned int offset, ArrayList *array)
{
if (index < 0 || (offset + index) > array->length)
return;
/* Move back the entries following the range to be removed */
memmove(array->elements[index], array->elements[index + offset], (array->length - (index + offset)) * sizeof(Element));
array->length -= offset;
}Ps: 其实有时候为了提高内存使用效率,可以在删除之后增加一个缩放容积的操作。
| Method | 时间复杂度 | 说明 | |
|---|---|---|---|
index_of_array |
O(N) | 查询元素 | |
delete_one |
O(N) | 删除指定索引的元素 | |
push_index |
O(N) | 向指定位置插入 | |
find |
O(1) | 返回指定下标的元素 | |
| ... | ... | ... |
顺序映像,是指借助元素在存储器相对位置来表示各数据元素之间的逻辑关系。
一个简单的例子,假如元素的存储长度为1个存储单元。且第一个元素的存储地址为0300,则第二个存储地址为0301。第那个元素的存储地址为(n-1)*1+(0300).
其实,这里如此描述并不合理。想要更加科学的描述这里面的请看微机原理或者计算机组成原理相关的概念。
简化成一个公式就是:
其中:
Loc代表为元素的存储地址,l代表单个元素的存储单元长度,a_i代表第i个存储单元
Loc(a_i) = Loc(a_0)+(i-1)*l