1948. Delete Duplicate Folders in System #1948
-
|
Topics: Due to a bug, there are many duplicate folders in a file system. You are given a 2D array
Two folders (not necessarily on the same level) are identical if they contain the same non-empty set of identical subfolders and underlying subfolder structure. The folders do not need to be at the root level to be identical. If two or more folders are identical, then mark the folders as well as all their subfolders.
Once all the identical folders and their subfolders have been marked, the file system will delete all of them. The file system only runs the deletion once, so any folders that become identical after the initial deletion are not deleted. Return the 2D array Example 1:
Example 2:
Example 3:
Constraints:
Hint:
|
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 2 replies
-
|
We need to identify and delete duplicate folders in a file system. Two folders are considered identical if they contain the same non-empty set of identical subfolders and the same underlying subfolder structure. The solution involves building a trie to represent the folder structure, using a post-order DFS to compute a unique hash for each folder's subtree, marking duplicate folders, and then collecting the remaining folders after deletion. Approach
Let's implement this solution in PHP: 1948. Delete Duplicate Folders in System <?php
class Node {
public $children = [];
public $hash = '';
public $deleted = false;
}
/**
* @param String[][] $paths
* @return String[][]
*/
function deleteDuplicateFolder($paths) {
$root = new Node();
foreach ($paths as $path) {
$node = $root;
foreach ($path as $folder) {
if (!isset($node->children[$folder])) {
$node->children[$folder] = new Node();
}
$node = $node->children[$folder];
}
}
$hashCount = [];
$dfs = function($node) use (&$dfs, &$hashCount) {
if (empty($node->children)) {
return "()";
}
$keys = array_keys($node->children);
sort($keys);
$rep = '';
foreach ($keys as $key) {
$childRep = $dfs($node->children[$key]);
$rep .= $key . $childRep;
}
$rep = '(' . $rep . ')';
$node->hash = $rep;
if (!isset($hashCount[$rep])) {
$hashCount[$rep] = 1;
} else {
$hashCount[$rep]++;
}
return $rep;
};
foreach ($root->children as $child) {
$dfs($child, $hashCount);
}
$markNodes = function($node) use (&$markNodes, $hashCount) {
if (!empty($node->children)) {
if ($hashCount[$node->hash] >= 2) {
$node->deleted = true;
}
}
foreach ($node->children as $child) {
$markNodes($child, $hashCount);
}
};
foreach ($root->children as $child) {
$markNodes($child, $hashCount);
}
$result = [];
$stack = new SplStack();
$stack->push([$root, []]);
while (!$stack->isEmpty()) {
list($node, $path) = $stack->pop();
foreach ($node->children as $name => $child) {
if ($child->deleted) {
continue;
}
$newPath = $path;
$newPath[] = $name;
$result[] = $newPath;
$stack->push([$child, $newPath]);
}
}
return $result;
}
// Test cases
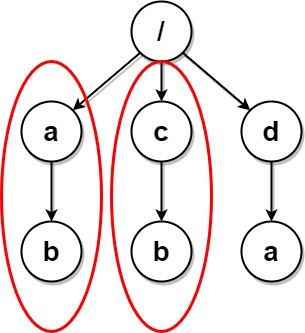
$paths1 = [["a"],["c"],["d"],["a","b"],["c","b"],["d","a"]];
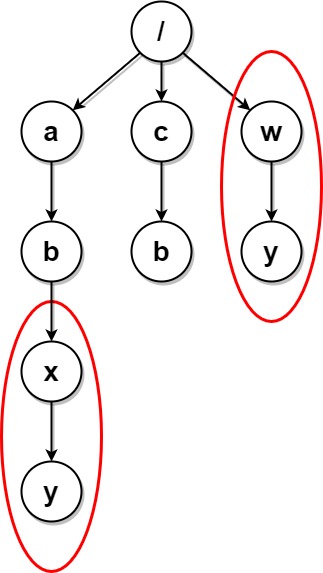
$paths2 = [["a"],["c"],["a","b"],["c","b"],["a","b","x"],["a","b","x","y"],["w"],["w","y"]];
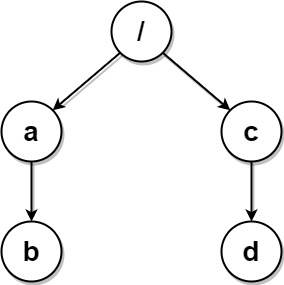
$paths3 = [["a","b"],["c","d"],["c"],["a"]];
print_r(deleteDuplicateFolder($paths1));
print_r(deleteDuplicateFolder($paths2));
print_r(deleteDuplicateFolder($paths3));
?>Explanation:
This approach efficiently identifies and deletes duplicate folders while preserving the remaining folder structure, meeting the problem requirements. The complexity is linear with respect to the number of nodes and edges in the trie. |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for solving the problem of "Delete Duplicate Folders in System" |
Beta Was this translation helpful? Give feedback.
-
|
Thanks |
Beta Was this translation helpful? Give feedback.
We need to identify and delete duplicate folders in a file system. Two folders are considered identical if they contain the same non-empty set of identical subfolders and the same underlying subfolder structure. The solution involves building a trie to represent the folder structure, using a post-order DFS to compute a unique hash for each folder's subtree, marking duplicate folders, and then collecting the remaining folders after deletion.
Approach