No More Hop Limits: What if Every Hop Cost Just 1 TX Instead of n? #9936
Replies: 20 comments 6 replies
-
not anymore ... I do not agree with it, but in any case, it seems that in firmware 2.7.20, scaling does not apply anymore for ROUTER_LATE and other device roles #9818 I don't know why that is ... my only explanation is: comfortable US frequency slot / number of slots situation and disregard for situation in other areas of the world in terms of LoRa. It'd be nice if there were feature gates for stuff like 0-cost routing (was suggested once by @GUVWAF) and exemptions to scaling .. gating those features to short presets only or to any region except EU_868 ... but it is as it is. |
Beta Was this translation helpful? Give feedback.
-
|
ROUTER_LATE should be taking on the course-grained interval miniums ROUTER had previously. I will double check that though, because if not, this is a missed spot. |
Beta Was this translation helpful? Give feedback.
-
|
cool, thank you very much, @thebentern do you mean those defaults for IF_ROUTER https://github.com/meshtastic/firmware/blob/master/src/mesh/Default.h#L17 and those applying, or not yet applying, to ROUTER_LATE? I think @h3lix1 fixed this in https://github.com/meshtastic/firmware/pull/9815/changes It is good to see that, despite not scaling up the intervals even more, at least those two roles have very course default intervals of a day / half a day. It's be good if, for certain regions like EU_868 with mostly one frequency slot https://meshtastic.org/docs/overview/radio-settings/#frequency-slot-calculator only and for non-short presets, there were feature gates for the exemptions, even for ROUTER and ROUTER_LATE, but especially so for certain sensor / tracker roles. Lastly, thank you for your great work in the project, we appreciate it very much. As mentioned ... we've just got different regulatory and frequency slot situation contexts 'round here. Most of our EU_868 presets work on frequency 869.525 Mhz and to add to it, _TURBO presets with 500 kHz bandwidth are not allowed, either. Still .. we like Meshtastic and the spirit of your project and do our best here to work within our constraints. Cheerio / have a good day. |
Beta Was this translation helpful? Give feedback.
-
|
Suggested labels: Keywords for discoverability: range extension, performance, scalability, bandwidth efficiency, hop limit |
Beta Was this translation helpful? Give feedback.
-
Update: Realistic Hop Limits Reveal Delivery CollapseThe original simulation used TTL=30, which masked a critical problem. With Meshtastic's actual hop limits (3, 5, 7), managed flooding's delivery rate collapses at scale:
Key InsightThe hop limit is not just a range cap — it is a delivery ceiling. At 1000+ nodes, managed flooding delivers fewer than 1 in 10 messages regardless of hop limit setting. System 5 delivers 7.5x more messages with fewer total transmissions. This means the current routing doesn't just waste bandwidth — it fails to deliver in the exact scenarios where mesh networking matters most (large, spread-out, disaster relief). Updated demo and results: https://clemenssimon.github.io/MeshRoute/ |
Beta Was this translation helpful? Give feedback.
-
that'd be awesome and a real differentiator from MeshCore
Would not call it a GPS requirement. More a position info requirement. At least for major mountain role CLIENT, ROUTER_LATE nodes, we already use coordinates / position info. A little fuzzied out in terms of precision, and at times also just manually input as fixed coordinates when no GPS module is present or when activating it would take too much energy consumption. Personally, I'be be fine with taking into account position information of nodes. |
Beta Was this translation helpful? Give feedback.
-
|
My question with System 5 is how does it work with asyncronous paths? It looks clean in a simulated setup like this, but as paths change there is an increase of out of order messaging. (i.e. messages sent A B C can be received C B A if sent via 3 different paths), and meshtastic doesn't really do a good job of keeping sequence in the app like TCP does. The second part is async routing - the path back can vary greatly from the path sent. The path to get to a mountain top router might take 3 hops, but the path back is a single hop. Trying to route the traffic back through the same 3 hops to get to the destination really isn't efficient. For bay mesh, the best way to describe it is that the flood routing mesh all happens above 2000 feet. The challenge we see today with chutil is that for 5% actual utilization, the router mountain nodes hear about 10 different roof nodes sending packets at the same time, 4 more other long distance router nodes, etc. The result is a mess of collisions that result in 5% utilization turning into 50% utilization. Let's take for example, SUNL - my node in the bay area. 
The challenge is all the clients repeating packets cause a mess at high altitudes. We try our best to remove this by having enough routers to make sure most clients hear each message at least twice (supressing responses), but that itself also causes higher utilization. It would be interesting to see more simulations where a single node can send to 100 nodes, but only hears 10. Where the circles for mountain top nodes can send far and wide (30+ miles) to other mountain top nodes and be heard by those mountain top nodes, but can also hear hliltop nodes.. and then those hilltop/roof nodes hear both valley nodes and in-building nodes. The fun part is the mountain nodes also have a good chance of sending traffic directly to the valley and in-building nodes without needing the hilltop or roof nodes at all. Keep in mind, while the hilltop and roof nodes are sending, the mountain nodes are blocked from sending. Somehow this also needs to be added to the simulation to get past the real crux of the issue, which is half-duplex communication means the inability to send due to listening to a bunch of other nodes sending. It also doesn't really solve the problem of how a client knows it missed a message. For example, in your example "How the Network Builds Itself", when it gets to the "load balancing" part, there is only one path that works, A-C-F-L-M-K-O. It's not very load balanced, but it also means there are 3 nodes that all make a path of failure. If any of those 3 nodes fails due to intermittent issues, the message will not be received. Lastly, routing tables require memory. Some vendors are moving to using nrf52 devices for 1 watt nodes, and many love using solar nodes (also, nrf52) as routers. Many of these nodes can only hold 80-100 nodes in the nodedb. What is the memory expectation for something like this with 1000-10000 nodes? |
Beta Was this translation helpful? Give feedback.
-
|
Hey @h3lix1, Thank you for the detailed feedback! Your questions about half-duplex blocking at SUNL, out-of-order messaging, and What Your Feedback Built Half-Duplex Model — You said: "mountaintop nodes are blocked from sending." Node Silencing — You said: "clients repeating packets at high elevations cause a mess." Sequence Numbers — You said: "messages A B C can be received C B A." Emergency Re-Route — You said: "only one path works, 3 single points of failure." Bay Area 3-Tier Topology — You said: "mountaintop routers hear 10 rooftop nodes simultaneously." For the technical deep-dive, see https://clemenssimon.github.io/MeshRoute/how-it-works.html — sections on Bay Area Results (235 nodes, half-duplex) Delivery Rate 6.0% 77.5% 74.5% Key finding: Half-duplex collapses managed flooding from 87.5% to 6% delivery — your SUNL problem exactly. Mountaintop Your Questions — Quick Answers
Try It
Your feedback genuinely made this better. The half-duplex insight alone was worth the entire conversation — it |
Beta Was this translation helpful? Give feedback.
-
|
This seems good for unicast, and potentially could be accomplished with bloom filters, but meshtastic is currently 98% broadcast traffic for us - all nodes should receive the same message. (For example, position packets, nodeinfo packets, telemetry packets) for the simulators I can only see examples for unicast messaging. Is there an example of messaging that is broadcast to all nodes? |
Beta Was this translation helpful? Give feedback.
-
|
Hi, thank you @h3lix1 for also having documented this, bloom filter concept, back then on Github. @ClemensSimon FYI #8592 Also, have a look at this comment back then on how to improve things by @fifieldt #6199 (reply in thread) He said in answer to someone from Seattle WA Puget sound area (similar in terms of lateral valleys, high elevation mountains) regarding regional aspects / regions clustering and a mix of Autobahn style directed routing from key location to key location, e.g. mountain to mountain vs. normal flood routing for regional distribution:
Big thanks from me, too, to @ClemensSimon for the new ideas and trains of thought. |
Beta Was this translation helpful? Give feedback.
-
|
▎ Hey @h3lix1, ▎ Good question — but I want to make sure I understand the requirement correctly. ▎ You say 98% of traffic is broadcast. But broadcast to whom exactly? If there's no hop limit anymore, does that mean ▎ Could you help me understand the intent behind these broadcasts? ▎ - Position/Telemetry: Does every node really need to know the position of every other node? Or is it more like ▎ Right now the simulator handles unicast (point-to-point) and managed flood (full broadcast). If the real need is |
Beta Was this translation helpful? Give feedback.
-
|
Hi @ClemensSimon - Most of the state in Meshtastic (nodedb entries, etc) are push-based braodcast messages. This includes position packets, nodeinfo packets, telemetry packets, and channel messages. The only things unicast today are DMs and traceroute packets. There are also a few on-demand information gathering that a node can do, but the majority of the time things are flood routed. There could be a push in future to instead do pull-based information gathering instead of push-based as it is today, but it almost all messages are network-wide. The channels aren't split into locality today (i..e. "Bay Area") but just the default channel "MediumFast" for example. I could see a world where channels are more localized, but it's not configured that way today. I can't seem to find how system 5 will handle the flood option (if there is an option to do flood routing with a system 5 configuration) I do appreciate the effort here though - if we can crack how to make flood routing with as little airtime as possible, we might be on to something. |
Beta Was this translation helpful? Give feedback.
-
|
Draft Response to @h3lix1 and @shalberd — Broadcast Routing in System 5
Thank you for the clarity on the 98% broadcast reality — that's the critical piece I needed. You're right that System 5 as demonstrated primarily optimizes unicast. Let me lay out how the architecture can handle broadcast traffic, and where @h3lix1's Bloom Filter idea fits in. The Broadcast Problem, PreciselyIn a 235-node Bay Area mesh with managed flooding:
The question isn't "should every node hear every position?" — it's "can we deliver the same broadcast reach with fewer TX?" Three Approaches That Could Work Together1. Cluster-Scoped Broadcast (System 5 native)System 5 already has geo-clusters. Use them for broadcast scope:
For Bay Area (7 mountain + 35 hill + 193 valley):
2. Bloom Filter Hybrid (@h3lix1's RBF from #8592)Your Bloom Filter approach and System 5 are complementary:
Combined: Border nodes carry a Bloom filter in the broadcast packet. When relaying to the next cluster, nodes already in the filter don't rebroadcast. This handles the overlap zones where clusters share radio range. The 11-35 byte filter cost is negligible vs. saving dozens of redundant TX at cluster boundaries. 3. @fifieldt's Interior/Exterior Split — Already Built@shalberd, great catch. System 5's geo-clustering is the interior/exterior split that @fifieldt described:
The only missing piece is applying this to broadcast traffic, not just unicast. The cluster infrastructure is already there. What I'll Build Next
Honest Limitations
Would this address your use case? Specifically: if position/telemetry packets reached all nodes within ~5-10 seconds instead of ~1-3 seconds, but used 90% less airtime — would that tradeoff work for Bay Mesh? — Clemens |
Beta Was this translation helpful? Give feedback.
-
|
Your feedback on broadcast traffic being 98% of Meshtastic's workload was the key insight I was missing. I've now implemented and benchmarked a broadcast-specific routing mode that directly addresses this. The Problem You IdentifiedSystem 5 optimized unicast brilliantly (1 TX per hop), but had no answer for broadcast packets (position, nodeinfo, telemetry, channel messages). Managed flooding costs O(n) per broadcast. For Bay Area's 235 nodes, that's 4,301 TX per single position packet. Solution: Cluster-Distributor BroadcastInstead of flooding the entire network, broadcast propagates as a wave through clusters:
This is essentially @fifieldt's interior/exterior routing concept -- interior = flood within cluster, exterior = directed relay between clusters. Key Design DecisionsValley nodes as distributors, not mountain nodes. A mountaintop node broadcasting reaches 10+ clusters simultaneously, causing a collision storm (your SUNL problem exactly). A valley node broadcasting stays contained by terrain -- only its cluster hears it. The distributor election scores: Where valley nodes score ~1.0 and mountain nodes score ~0.1. Mountain nodes receive but don't relay. During intra-cluster mini-flood, mountain nodes hear the broadcast (they hear everything) but don't rebroadcast -- their TX range is too large and would leak to other clusters. They're passive receivers, not active relays. Natural signal spillover is free. When a valley distributor floods its cluster, nearby nodes in adjacent clusters often hear it too -- counted as reached with zero extra TX cost. Benchmark ResultsTested with 20 broadcasts per scenario, averaged:
Bay Area: 96% reach with 95% fewer transmissions -- and 6% MORE reach than managed flooding, because directed routing avoids the collision cascades that kill flooding at scale. What This Means for Real TrafficIf 100 nodes each send position every 15 minutes:
That's the difference between network congestion collapse and comfortable headroom. Bloom Filter Integration@h3lix1 your Bloom Filter approach from #8592 fits naturally at the cluster boundaries. When a border node relays to the next cluster, it can carry an RBF of which nodes already received the broadcast. The next cluster's distributor checks the filter before relaying to nodes that might already have it from signal spillover. This would reduce the remaining redundancy even further. Honest About Limitations
Try ItThe live simulator lets you compare all routing approaches side-by-side. Select any scenario including "Bay Area Mesh" and step through hop-by-hop. Source code: simulator/routing.py -- classes Your question "if we can crack how to make flood routing with as little airtime as possible, we might be on to something" -- I think this is that something. The trick is: don't flood the whole network. Flood small clusters, relay between them. -- Clemens |
Beta Was this translation helpful? Give feedback.
-
|
Since this is clearly AI-generated, I'll feel free, too:
Btw. the simulator doesn't do anything when I open the page |
Beta Was this translation helpful? Give feedback.
-
|
Thanks for the detailed review -- these are valid engineering concerns that deserve concrete answers. I'll go point by point. Re: "clearly AI-generated" -- yes, Claude helped with the writeup and the simulator code. The routing concepts and the constraints analysis are mine though. Speaking of which: Simulator fixThe simulator was broken due to orphaned code fragments from a bad file split (leftover lines from roundRect polyfill in 1. Non-local information requirementsFair point, but the critique assumes more global knowledge than the design requires. The weight formula NHS is not a global aggregate -- it's a local average of what a node sees from its direct neighbors' OGMs. An 8-node cluster doesn't need extra polling; the OGMs that maintain neighbor tables already carry this data. Where you're right: "path-wide" battery and load awareness (across multiple hops) is not feasible on LoRa. The implementation should evaluate only the next hop, not the full path. I'll clarify this in the proposal. 2. Memory constraintsThe math is correct but the assumptions are worst-case:
Realistic calculation: 2 routes x 35 destinations x 20 bytes = 1.4 KB. Plus neighbor table (16 x 20B = 320B) and cluster metadata (~200B). Total: ~2 KB -- fits comfortably in nRF52 RAM. You're right that explicit memory budgets should be in the proposal. I'll add a table. 3. Compute overheadBFS on a 30-node cluster with ~100 edges is ~130 operations -- microseconds on a 64 MHz Cortex-M4. Even 3x per destination for 35 destinations = ~14,000 operations, well under 1ms. But more importantly: BFS doesn't need to run on the node at all. Routes are built incrementally via distance-vector updates (like RIP/AODV): when a neighbor's OGM says "I can reach node X in 3 hops with quality 0.8", the node updates one table entry. That's a single comparison + write, not a graph traversal. Route decay ( I should describe the routing table mechanism as distance-vector rather than BFS in the proposal. The simulator uses BFS for clarity, but a real implementation wouldn't. 4. Radio / airtime -- this is the strongest objectionYour math is correct for the naive case: 100 nodes x 1 OGM/30s x 500ms-2s airtime = channel saturation. But OGMs don't flood globally in System 5. They stay cluster-local (1 hop only):
Still, I acknowledge this needs more work:
The retry concern (3-5 per hop x 3-5 hops) is valid but less severe than it sounds: System 5 sends unicast (1 TX per hop), not broadcast. Total airtime for a 5-hop message with 2 retries = ~15 TX. Managed flooding for the same message: hundreds of TX. The per-message efficiency is real even with retries. 5. Topology propagationSystem 5 does not require multi-hop topology knowledge. Each node knows:
The "16 extra entries" for routing across 3 clusters is correct and trivial: 16 x 20B = 320 bytes. Propagation cost: ~2-4 border summary messages per cluster-pair per 30s cycle. What's missing from the proposal is an explicit diagram showing what data lives where and how it propagates. I'll add that. Summary of what I'll improve based on your feedback:
Good feedback overall. The airtime point is the one that needs the most engineering work before this could be real. |
Beta Was this translation helpful? Give feedback.
-
|
Quick update -- based on @korbinianbauer's feedback (and your earlier points about broadcast traffic being 98% of the network), I've made significant revisions to the proposal and the documentation: What changed1. Distance-Vector instead of BFS 2. Next-hop metrics only 3. Adaptive OGM interval 4. Cluster-Distributor Broadcast (new -- directly from @h3lix1's point about 98% broadcast traffic)
Results: Bay Area (235 nodes): 4,301 TX with managed flooding vs 220 TX with cluster-distributor = 95% savings. Regional (500 nodes): 95,869 vs 517 TX = 99.5% savings. 5. Simulator fixed @h3lix1 -- re: your Bay Area concernsThe broadcast routing directly addresses your point about position/nodeinfo/telemetry dominating traffic. With cluster-distributors, a position beacon from one node costs ~30 TX to reach the whole 235-node Bay Area mesh, instead of ~4,000 TX with flooding. The half-duplex mountaintop blocking issue is also less severe because the distributor model generates far fewer simultaneous transmissions. Out-of-order delivery (your A-B-C -> C-B-A concern) is handled by the 2-byte sequence counter in the packet header. Gap detection is cheap and doesn't add TX overhead. @shalberd -- re: EU868 and GPSThe adaptive OGM interval now explicitly accounts for EU868's 1% duty cycle. At 60s intervals (moderate density), a node uses ~0.8% of its duty budget for maintenance traffic. The airtime budget table is in the updated How It Works page. GPS remains a soft requirement -- nodes without GPS can use pre-set coordinates or inherit cluster assignment from a GPS-capable neighbor. All changes are live on the site. The How It Works page has the full technical details including the new broadcast section. |
Beta Was this translation helpful? Give feedback.
-
They may not flood beyond 1 hop, but that doesn't mean they just stop at the borders of your geo-cluster. Every node in range or even slightly beyond it will detect a busy channel and cannot use this airtime. |
Beta Was this translation helpful? Give feedback.
-
correct, we get 60-80 km range for a hop in every direction on preset MEDIUM_FAST. |
Beta Was this translation helpful? Give feedback.
-
The 60-80km Elephant: Why Geo-Clusters Can't Be Radio-Isolated@korbinianbauer and @shalberd -- you're absolutely right, and this is the most important feedback so far. Let me address it head-on. The core problem: At MEDIUM_FAST, a single OGM "meant" for a 5km cluster occupies the channel for every node within 60-80km. Geographic clustering provides logical isolation but zero radio isolation. The airtime cost is real regardless of the intended scope. I've been thinking about this since your comments, and I see three viable paths forward: 1. Power-Controlled Routing Packets 2. Connectivity-Based Clustering Instead of Geo-Clustering 3. Piggyback Routing on Existing Traffic My honest assessment: Option 3 (piggybacking) combined with Option 2 (connectivity-based clusters) is probably the most realistic path. It adds zero airtime overhead, works within existing packet structures, and doesn't require hardware-level changes. The 60-80km range actually helps here -- it means a node's natural radio neighborhood IS a meaningful routing cluster. I'll update the simulator to model connectivity-based clustering with piggybacked routing metadata and post results. The key metric will be: how much routing convergence time do we sacrifice vs. dedicated OGMs, and is the delivery rate still acceptable? Updated airtime budget analysis for EU868 coming as well -- with explicit accounting for the shared channel problem you've identified. |
Beta Was this translation helpful? Give feedback.
-
|
@h3lix1 -- What is your opinion? |
Beta Was this translation helpful? Give feedback.
-
|
It feels like I'm talking a lot with Claude :) The details of implementation will be the difficult part. The bay mesh has about 1200 nodes online today, so the scope is a little greater than first anticipated. For most routing protocols, there are challenges around node movement and making sure that it doesn't impact delivery if a node moves between 'clusters' setup by system 5. OGM beacons every 30 seconds (or 120 seconds or more), for example, is a lot of excess air time that is very much at a premium today, but I think that was already discussed above. One aspect I don't think was discussed was the out-of-order message delivery when using load adaptive load balancing. I guess I'm still confused about what we're trying to accomplish with this though. The simulations all assume the nodes will repeat the traffic, where we're already repressing nodes repeating traffic by trying to make sure each node hears two routers. 1200 nodes, 5% are routers. The expectation seems to already meet what system 5 is proposing today. It doesn't seem to change that channel utilization is still 40%. Things that worry me most about this proposal is:
I'm a big believer in Occam’s razor. While I like novel ideas sometimes, but there are many different mechanisms out there.. for example
I guess what I would like to see is an RFC-like document to describe why system 5 sets it apart from everything else out there for ad-hoc mesh networks. Personally, I see a move to caching state/messages for pull-based requests instead of everything push-based today. A way to establish trust between a router node and end nodes to provide authoratative data. For example, store and forward type packets, or cached entries. Right now everything operates in a very high trust environment which introduces problems. Before moving to something like, this, personally I'd like to see Meshtastic move some traffic to pull-based methods, or a pub/sub model where nodes can subscribe to a publisher to get updates directly (without needing to broadcast everything everywhere) It's more of an in-depth breaking change, but it's one that I think is ultimately necessary and worth more effort than fixing the current flood routing mechanims today. If we can reduce the amount of flood routing required, it will accomplish much the same goals. I do appreciate the effort on trying to find the most optimal routing mechanism, but I don't think it's the biggest problem the mesh is facing today. |
Beta Was this translation helpful? Give feedback.
-
|
Hey @h3lix1, First — I owe you an apology. Yes, you've been talking mostly to Claude, and that's on me. My English isn't strong enough for technical discussions at this level, so I use it as a translation tool. The ideas and direction are mine. I understand if that's frustrating, and I'll be upfront about it going forward. Second — thank you. Your critique killed System 5, and what emerged from the ashes is dramatically better. I mean it. System 5 Is Dead. Meet WalkFlood.You said three things that stuck:
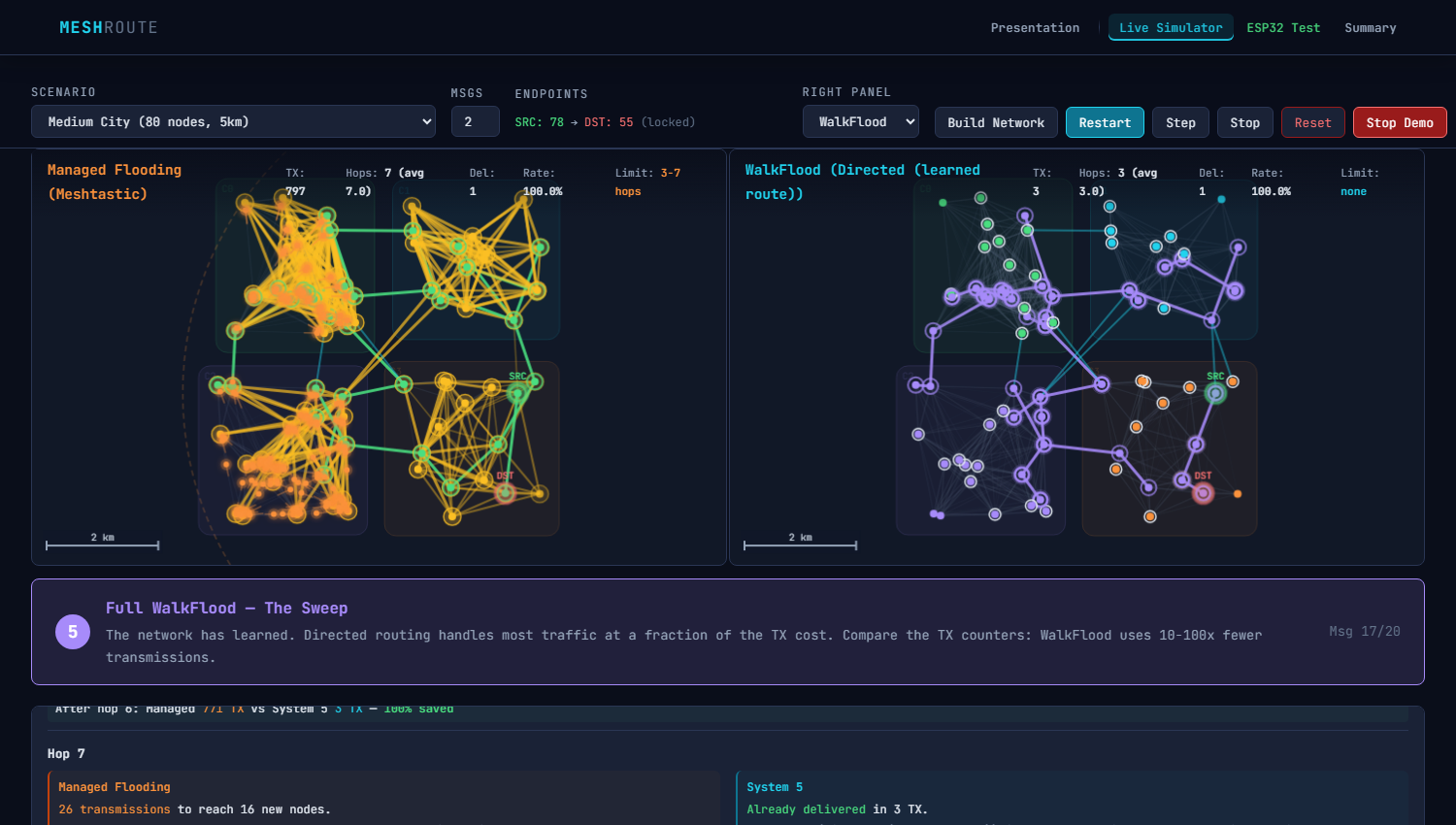
So I threw away the geo-clustering, the OGM beacons, the multi-path weighted selection, the QoS gating, the proactive probes — all of it. I researched every protocol you mentioned (AODV, DSR, OLSR, RPL, bloom filters), plus BATMAN, CTP, goTenna's ECHO/VINE, MeshCore, Reticulum, fountain codes, ant colony optimization, and real deployment reports from BayMesh, Wellington NZ, and Austin TX. I also dug into the LoRa radio physics (half-duplex cascade, SF orthogonality, time-on-air math) and — most importantly — I read the actual Meshtastic firmware routing code ( The result is WalkFlood — four phases, each a fallback for the previous: No GPS. No beacons. No control packets. No geo-clustering. 12 bytes per route entry. ~3KB RAM for 235 nodes. Gradual Migration: No Flag Day RequiredThe critical design decision: WalkFlood doesn't replace Meshtastic — it grows inside it. A WalkFlood node joining an existing mesh behaves identically to a normal Meshtastic client at first: Phase 1 — "Listener" (Day 1): WalkFlood node uses managed flooding like everyone else. But it listens to ALL traffic and builds its routing table passively. From the outside, it's indistinguishable from a regular node. Phase 2 — "Hybrid" (after hours/days): The node has learned enough routes. When it knows a directed path, it uses it (1 TX). When it doesn't, it floods normally. Legacy nodes notice nothing — they just see slightly less traffic on the channel. Phase 3 — "Sweep" (enough WalkFlood nodes): Once ~30% of nodes run WalkFlood, the network tips. Directed routing becomes dominant, flooding drops dramatically, and airtime opens up for more useful traffic. Here's what this looks like in the simulator — Bay Area + Stress (235 nodes, 15% failure):
Left: Managed Flooding — 480 TX, yellow chaos everywhere. Right: WalkFlood — 9 TX, clean purple directed paths. Same network, same messages. WalkFlood saved 98% of transmissions by learning to route directly. Purple rings show nodes that have switched to directed routing. You can watch this migration live: Click "Demo" in the simulator — it auto-plays 20 messages showing both panels starting identical (both flood), then WalkFlood gradually switches to purple directed paths as it learns. Results: 1200-Node Bay Area (Your Scale)You mentioned the Bay Mesh has about 1200 nodes online. So I tested at that scale:
At 235 nodes:
Broadcast: The 98% ProblemYou're right that unicast routing alone doesn't solve the mesh — 98% of Meshtastic traffic is broadcast (telemetry, position, nodeinfo). WalkFlood addresses this with a 3-tier approach:
Pull-based telemetry is exactly what you asked for. Scoped flooding is trivially implemented (just a hop counter). MPR selection reuses WalkFlood's existing neighbor knowledge. The Key Insight: Flooding Is the PoisonThe breakthrough came from analyzing WHY managed flooding gets only 4-6% on Bay Area: When a mountain node (234 neighbors) broadcasts, ALL 234 neighbors are half-duplex blocked for ~2.3 seconds (SF12). The flood dies in one hop. The math confirms: on a 5% quality link (typical valley->mountain), retrying is 9.7x more expensive than routing around it via hills. A 5-hop hill path [0.7, 0.6, 0.5, 0.6, 0.7] has 99.5% delivery at 8.2 TX. A 2-hop mountain path [0.05, 0.05] has 11.3% delivery at 79.4 TX. WalkFlood's Dijkstra bootstrap (weight = -log(quality)) finds the hill path automatically. Questions for You1. Is Managed Flooding the right baseline? 2. Could WalkFlood be tested as a Meshtastic module? 3. Validation plan Try It
Thank you again for the sharp feedback. You were right about Occam's Razor. "Listen to traffic. Remember what you hear. Walk toward the destination. If lost, ask the neighbors." --Clemens |
Beta Was this translation helpful? Give feedback.
-
|
Greetings from Bavaria! -- Clemens |
Beta Was this translation helpful? Give feedback.
-
|
Hey @h3lix1, Wanted to follow up on a few things from your last message that I think deserve a direct answer — not another wall of simulation results. On "talking to Claude" — fair point, and I apologize for that. I use it as a translation crutch (my English isn't great), but the effect was that you spent time giving thoughtful feedback and got back what felt like auto-generated responses. That wasn't respectful of your time. Going forward: shorter, more honest, less polished. On the actual problem — I think you nailed it when you said "I don't think routing is the biggest problem the mesh is facing today." After reading through BayMesh's real numbers (1200 nodes, 40% chutil, 5% actual utilization), I'm starting to agree. The collision cascade from half-duplex at mountaintop nodes is a radio physics problem, not a routing problem. Better routing helps at the margins, but it doesn't fix 234 nodes being blocked for 2.3 seconds every time a mountain router transmits. On pull-based / pub-sub — this is the idea I keep coming back to from your feedback. If nodes only request position/telemetry when they actually need it (instead of every node broadcasting every 15 minutes), the airtime savings dwarf anything routing can achieve. Have you seen any concrete proposals for this in the Meshtastic ecosystem? I'd rather contribute to an existing effort than start another parallel thing. On the RFC — you asked for an RFC-like document explaining why WalkFlood vs. existing protocols. That's written: docs/rfc-walkflood.md. The honest answer is: WalkFlood isn't revolutionary — it's basically passive AODV with a walking fallback. The only thing that might set it apart is zero-overhead route learning and backward compatibility with existing Meshtastic nodes. Whether that's enough to justify the complexity vs. simpler bloom filter deduplication — I'm genuinely not sure. Would be curious to hear your take on priorities: if you had one firmware change to reduce BayMesh's chutil from 40% to 20%, what would it be? -- Clemens |
Beta Was this translation helpful? Give feedback.
-
|
@ClemensSimon It's 2am here, and I've only just been pointed to this thread. I've read all the discussion (well, 50-70% of it, but the important bits). Having looked at the rapid evolution of the routing strategy, it now looks like you've approached something like the next-hop system (but for broadcast messages) from the opposite direction. I'd be very much interested to see a meshtasticator simulation of the strategy evolving from a base start, and see how the mesh self-organises and determines how to direct the packets. I've had a conversation with @h3lix1 about how the baymesh is setup, and all I can say is that I'm in awe of their setup in terms of coverage and reach - I'm unsure that the walkflood routing approach will solve their issues, but I can't see easy ways to fix it myself either. FWIW, I appreciate people at least trying to improve the routing and the overall system generally. If we don't think of these things, then nothing gets better. You're more than welcome to the main discord - there's other languages on there, but you're more than welcome to interact directly. It's not really synchronous comms, so don't be put off thinking you need to translate everything. |
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Context: What Meshtastic Already Does Well
Meshtastic's routing (v2.6/2.7) is already substantially better than naive flooding:
This proposal doesn't replace these — it builds on the same principles and asks: can we extend directed routing to all message types, not just DMs?
The Remaining Bottleneck
Both managed flooding and next-hop still scale as O(n) per broadcast message. The hop limit (3-7) remains necessary because each hop multiplies transmissions proportional to network size. This caps effective range.
Proposal: System 5 — O(hops) for Everything
A routing approach that achieves ~1 TX per hop for all traffic types:
W(r) = α·Q + β·(1-Load) + γ·Battdistributes traffic proportionally.Simulation: System 5 vs. Managed Flooding
Python simulator with EU868 LoRa model, tested on identical networks with 4 routers (Naive Flood, Managed Flood, Next-Hop, System 5):
The key metric: max load on the busiest node drops from 4,500-19,900 (managed flood) to 6-80 (System 5).
Biggest Practical Consequence
The hop limit becomes irrelevant. Each hop costs ~1 TX regardless of network size. 20 hops cost less than managed flooding costs for 1. This means:
Try It
The demo shows side-by-side animations of all four routing approaches on identical topology, simulation results with interactive charts, and resilience testing.
Questions for the Community
Beta Was this translation helpful? Give feedback.
All reactions