Description
Currently, the docs state that boolean indexing is only possible with 1-dimensional arrays:
http://xarray.pydata.org/en/stable/indexing.html
However, I often have the case where I'd like to convert a subset of an xarray to a dataframe.
Usually, I would call e.g.:
data = xrds.stack(observations=["dim1", "dim2", "dim3"])
data = data.isel(~ data.missing)
df = data.to_dataframe()However, this approach is incredibly slow and memory-demanding, since it creates a MultiIndex of every possible coordinate in the array.
Describe the solution you'd like
A better approach would be to directly allow index selection with the boolean array:
data = xrds.isel(~ xrds.missing, dim="observations")
df = data.to_dataframe()This way, it is possible to
- Identify the resulting coordinates with
np.argwhere() - Directly use the underlying array for fancy indexing:
variable.data[mask]
Additional context
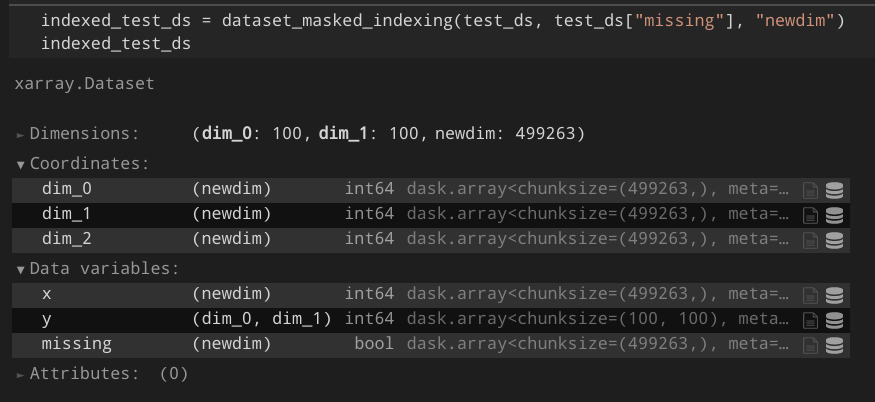
I created a proof-of-concept that works for my projects:
https://gist.github.com/Hoeze/c746ea1e5fef40d99997f765c48d3c0d
Some important lines are those:
def core_dim_locs_from_cond(cond, new_dim_name, core_dims=None) -> List[Tuple[str, xr.DataArray]]:
[...]
core_dim_locs = np.argwhere(cond.data)
if isinstance(core_dim_locs, dask.array.core.Array):
core_dim_locs = core_dim_locs.persist().compute_chunk_sizes()
def subset_variable(variable, core_dim_locs, new_dim_name, mask=None):
[...]
subset = dask.array.asanyarray(variable.data)[mask]
# force-set chunk size from known chunks
chunk_sizes = core_dim_locs[0][1].chunks[0]
subset._chunks = (chunk_sizes, *subset._chunks[1:])As a result, I would expect something like this: