diff --git a/.gitignore b/.gitignore
index e8394c8..11dc326 100644
--- a/.gitignore
+++ b/.gitignore
@@ -173,4 +173,10 @@ cython_debug/
# PyPI configuration file
.pypirc
-.idea/
\ No newline at end of file
+.idea/
+
+# model artifacts
+rf-detr*
+output/*
+
+train_test.py
\ No newline at end of file
diff --git a/README.md b/README.md
index 6760f72..2631639 100644
--- a/README.md
+++ b/README.md
@@ -1,4 +1,4 @@
-# RF-DETR: SOTA Real-Time Object Detection Model
+# RF-DETR: SOTA Real-Time Detection and Segmentation Model
[](https://badge.fury.io/py/rfdetr)
[](https://pypistats.org/packages/rfdetr)
@@ -10,24 +10,31 @@
[](https://blog.roboflow.com/rf-detr)
[](https://discord.gg/GbfgXGJ8Bk)
-RF-DETR is a real-time, transformer-based object detection model developed by Roboflow and released under the Apache 2.0 license.
+RF-DETR is a real-time, transformer-based object detection and instance segmentation model architecture developed by Roboflow and released under the Apache 2.0 license.
-RF-DETR-N outperforms YOLO11-N by 10 mAP points on the [Microsoft COCO](https://cocodataset.org/#home) benchmark while running faster at inference. On [RF100-VL](https://github.com/roboflow/rf100-vl), RF-DETR achieves state-of-the-art results, with RF-DETR-M beating YOLO11-M by an average of 5 mAP points across aerial datasets including drone, satellite, and radar.
+RF-DETR is the first real-time model to exceed 60 AP on the [Microsoft COCO object detection benchmark](https://cocodataset.org/#home) alongside competitive performance at base sizes. It also achieves state-of-the-art performance on [RF100-VL](https://github.com/roboflow/rf100-vl), an object detection benchmark that measures model domain adaptability to real world problems. RF-DETR is fastest and most accurate for its size when compared current real-time objection models.
+
+On image segmentation, RF-DETR Seg (Preview) is 3x faster and more accurate than the largest YOLO when evaluated on the Microsoft COCO Segmentation benchmark, defining a new real-time state-of-the-art for the industry-standard benchmark in segmentation model evaluation.
[](https://youtu.be/-OvpdLAElFA)
## News
-- `2025/09/02`: RF-DETR fine-tuning YouTube tutorial released. Learn step-by-step how to fine-tune RF-DETR on your custom dataset.
-- `2025/07/23`: Released three new checkpoints for RF-DETR: Nano, Small, and Medium.
-- `2025/05/16`: Added `optimize_for_inference` method, improving native PyTorch inference speed by up to 2x depending on platform.
-- `2025/04/03`: Introduced early stopping, gradient checkpointing, metric saving, training resume, TensorBoard, and W&B logging.
-- `2025/03/20`: Released RF-DETR real-time object detection model. Code and checkpoints for RF-DETR-Large and RF-DETR-Base are available.
+- `2025/10/02`: We release RF-DETR-Seg (Preview), a preview of our instance segmentation head for RF-DETR.
+- `2025/07/23`: We release three new checkpoints for RF-DETR: Nano, Small, and Medium.
+ - RF-DETR Base is now deprecated. We recommend using RF-DETR Medium which offers subtantially better accuracy at comparable latency.
+- `2025/03/20`: We release RF-DETR real-time object detection model. **Code and checkpoint for RF-DETR-large and RF-DETR-base are available.**
+- `2025/04/03`: We release early stopping, gradient checkpointing, metrics saving, training resume, TensorBoard and W&B logging support.
+- `2025/05/16`: We release an 'optimize_for_inference' method which speeds up native PyTorch by up to 2x, depending on platform.
## Results
RF-DETR achieves state-of-the-art performance on both the Microsoft COCO and the RF100-VL benchmarks.
+The below tables shows how RF-DETR performs when validated on the Microsoft COCO benchmark for object detection and image segmentation.
+
+### Object Detection Benchmarks
+
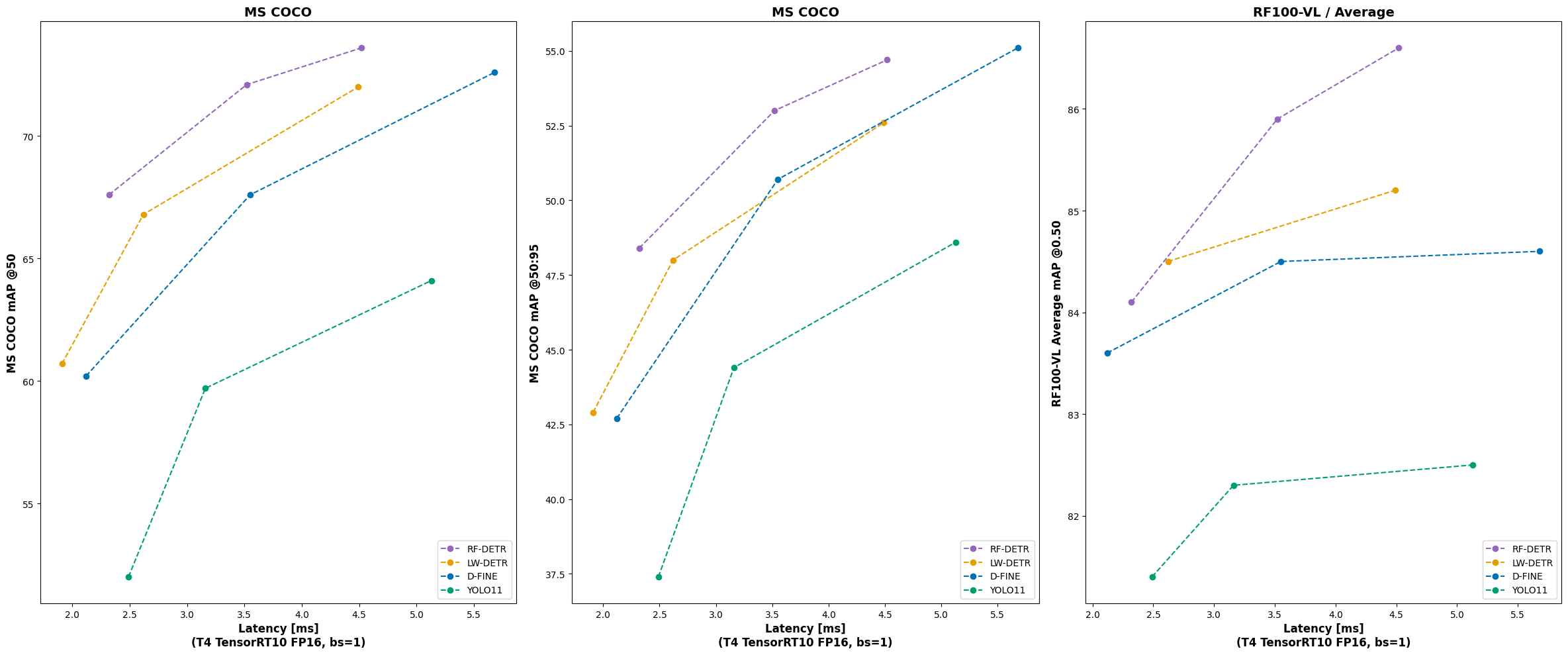
| Architecture | COCO AP50 | COCO AP50:95 | RF100VL AP50 | RF100VL AP50:95 | Latency (ms) | Params (M) | Resolution |
@@ -51,6 +58,28 @@ RF-DETR achieves state-of-the-art performance on both the Microsoft COCO and the
_We are actively working on RF-DETR Large and X-Large models using the same techniques we used to achieve the strong accuracy that RF-DETR Medium attains. This is why RF-DETR Large and X-Large is not yet reported on our pareto charts and why we haven't benchmarked other models at similar sizes. Check back in the next few weeks for the launch of new RF-DETR Large and X-Large models._
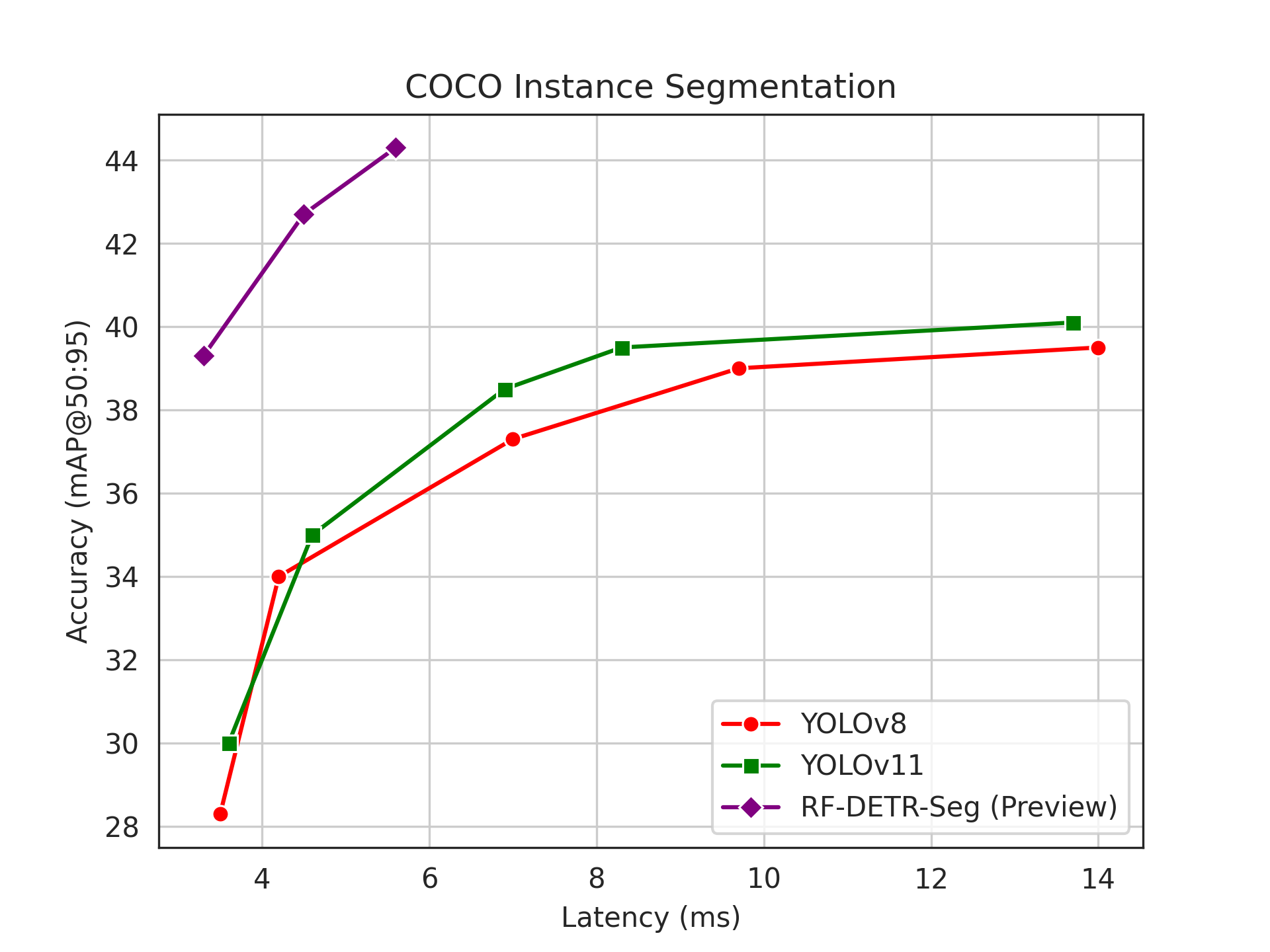
+### Instance Segmentation Benchmarks
+
+
+
+| Model Name | Reported Latency | Reported mAP | Measured Latency | Measured mAP |
+|-------------------------|------------------|--------------|------------------|--------------|
+| RF-DETR Seg-Preview@312 | | | 3.3 | 39.4 |
+| YOLO11n-Seg | 1.8 | 32.0 | 3.6 | 30.0 |
+| YOLOv8n-Seg | | 30.5 | 3.5 | 28.3 |
+| RF-DETR Seg-Preview@384 | | | 4.5 | 42.7 |
+| YOLO11s-Seg | 2.9 | 37.8 | 4.6 | 35.0 |
+| YOLOv8s-Seg | | 36.8 | 4.2 | 34.0 |
+| RF-DETR Seg-Preview@432 | | | 5.6 | 44.3 |
+| YOLO11m-Seg | 6.3 | 41.5 | 6.9 | 38.5 |
+| YOLOv8m-Seg | | 40.8 | 7.0 | 37.3 |
+| YOLO11l-Seg | 7.8 | 42.9 | 8.3 | 39.5 |
+| YOLOv8l-Seg | | 42.6 | 9.7 | 39.0 |
+| YOLO11x-Seg | 15.8 | 43.8 | 13.7 | 40.1 |
+| YOLOv8x-Seg | | 43.4 | 14.0 | 39.5 |
+
+For more information on measuring end-to-end latency for models, see our open source [Single Artifact Benchmarking tool](https://github.com/roboflow/single_artifact_benchmarking).
+
## Installation
To install RF-DETR, install the `rfdetr` package in a [**Python>=3.9**](https://www.python.org/) environment with `pip`:
@@ -102,6 +131,8 @@ annotated_image = sv.BoxAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annot
annotated_image = sv.LabelAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections, labels)
```
+To use segmentation, use the `rfdetr-seg-preview` model ID. This model will return segmentation masks from a RF-DETR-Seg (Preview) model trained on the Microsoft COCO dataset.
+
## Predict
You can also use the .predict method to perform inference during local development. The `.predict()` method accepts various input formats, including file paths, PIL images, NumPy arrays, and torch tensors. Please ensure inputs use RGB channel order. For `torch.Tensor` inputs specifically, they must have a shape of `(3, H, W)` with values normalized to the `[0..1)` range. If you don't plan to modify the image or batch size dynamically at runtime, you can also use `.optimize_for_inference()` to get up to 2x end-to-end speedup, depending on platform.
@@ -140,7 +171,7 @@ sv.plot_image(annotated_image)
You can fine-tune an RF-DETR Nano, Small, Medium, and Base model with a custom dataset using the `rfdetr` Python package.
-[Read our training tutorial to get started](https://rfdetr.roboflow.com/learn/train/)
+[Learn how to train an RF-DETR model.](https://rfdetr.roboflow.com/learn/train/)
## Documentation
diff --git a/docs/index.md b/docs/index.md
index b2e7cf4..dc05086 100644
--- a/docs/index.md
+++ b/docs/index.md
@@ -1,20 +1,23 @@
---
hide:
-- toc
- navigation
---
-# RF-DETR: SOTA Real-Time Object Detection Model
+# RF-DETR: SOTA Real-Time Detection and Segmentation Model
## Introduction
-RF-DETR is a real-time, transformer-based object detection model architecture developed by Roboflow and released under the Apache 2.0 license.
+RF-DETR is a real-time, transformer-based object detection and instance segmentation model architecture developed by Roboflow and released under the Apache 2.0 license.
-RF-DETR is the first real-time model to exceed 60 AP on the [Microsoft COCO benchmark](https://cocodataset.org/#home) alongside competitive performance at base sizes. It also achieves state-of-the-art performance on [RF100-VL](https://github.com/roboflow/rf100-vl), an object detection benchmark that measures model domain adaptability to real world problems. RF-DETR is fastest and most accurate for its size when compared current real-time objection models.
+RF-DETR is the first real-time model to exceed 60 AP on the [Microsoft COCO object detection benchmark](https://cocodataset.org/#home) alongside competitive performance at base sizes. It also achieves state-of-the-art performance on [RF100-VL](https://github.com/roboflow/rf100-vl), an object detection benchmark that measures model domain adaptability to real world problems. RF-DETR is fastest and most accurate for its size when compared current real-time objection models.
+
+On image segmentation, RF-DETR Seg (Preview) is 3x faster and more accurate than the largest YOLO when evaluated on the Microsoft COCO Segmentation benchmark, defining a new real-time state-of-the-art for the industry-standard benchmark in segmentation model evaluation.
RF-DETR is small enough to run on the edge using [Inference](https://github.com/roboflow/inference), making it an ideal model for deployments that need both strong accuracy and real-time performance.
-## Results
+## Benchmark Results
+
+### Object Detection
We validated the performance of RF-DETR on both Microsoft COCO and the RF100-VL benchmarks.
@@ -22,6 +25,12 @@ We validated the performance of RF-DETR on both Microsoft COCO and the RF100-VL
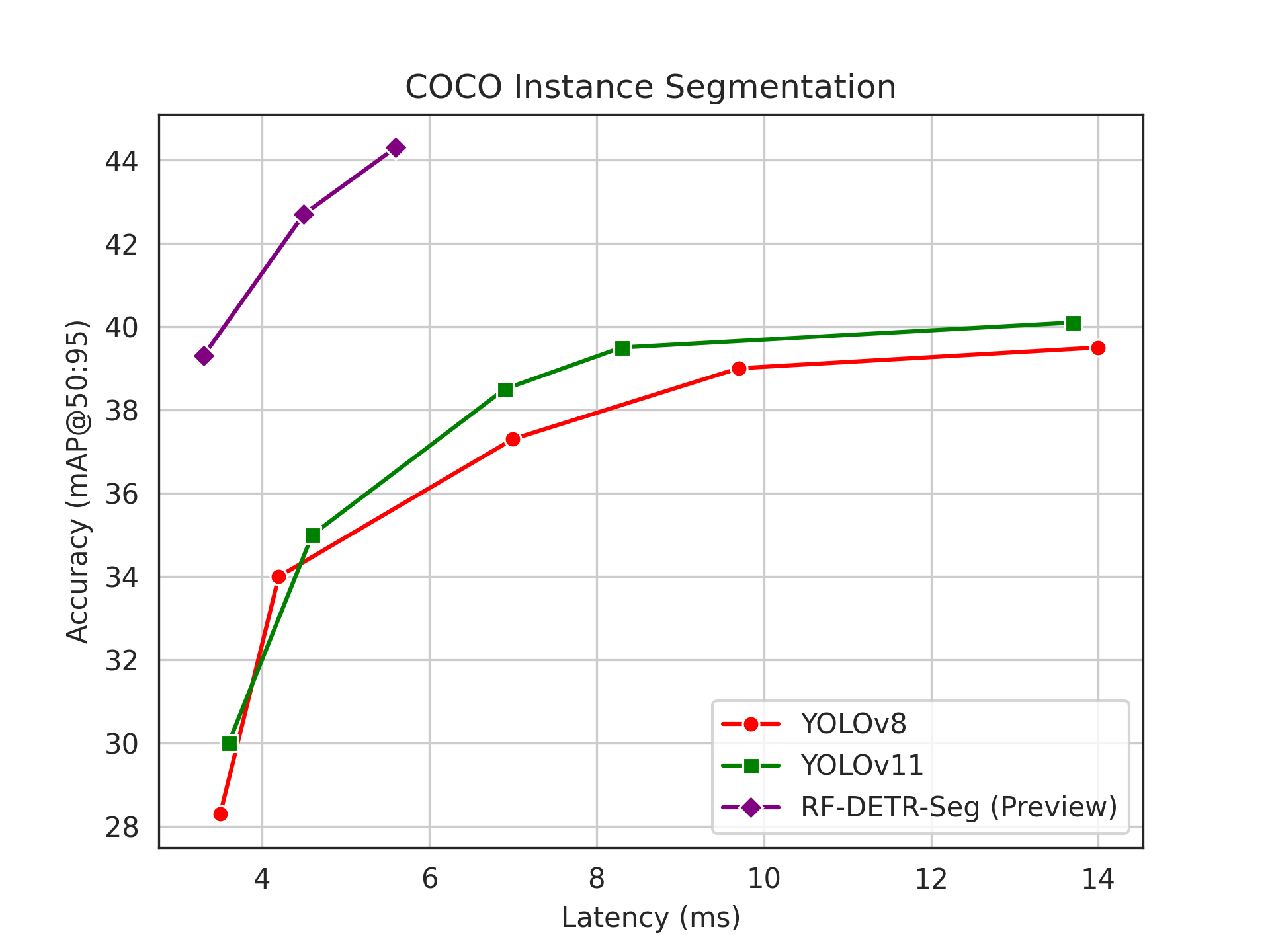
 +### Instance Segmentation
+
+We benchmarked RF-DETR on the Microsoft COCO dataset for segmentation. Our results are below.
+
+
+
## 💻 Install
You can install and use `rfdetr` in a
diff --git a/docs/learn/deploy.md b/docs/learn/deploy.md
index 8f618ca..9d7672d 100644
--- a/docs/learn/deploy.md
+++ b/docs/learn/deploy.md
@@ -6,17 +6,33 @@ Deploying to Roboflow allows you to create multi-step computer vision applicatio
To deploy your model to Roboflow, run:
-```python
-from rfdetr import RFDETRNano
-
-x = RFDETRNano(pretrain_weights="")
-x.deploy_to_roboflow(
- workspace="",
- project_id="",
- version=1,
- api_key=""
-)
-```
+=== "Object Detection"
+
+ ```python
+ from rfdetr import RFDETRNano
+
+ x = RFDETRNano(pretrain_weights="")
+ x.deploy_to_roboflow(
+ workspace="",
+ project_id="",
+ version=1,
+ api_key=""
+ )
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ from rfdetr import RFDETRSegPreview
+
+ x = RFDETRSegPreview(pretrain_weights="")
+ x.deploy_to_roboflow(
+ workspace="",
+ project_id="",
+ version=1,
+ api_key=""
+ )
+ ```
Above, set your Roboflow Workspace ID, the ID of the project to which you want to upload your model, and your Roboflow API key.
@@ -25,31 +41,62 @@ Above, set your Roboflow Workspace ID, the ID of the project to which you want t
You can then run your model with Roboflow Inference:
-```python
-import os
-import supervision as sv
-from inference import get_model
-from PIL import Image
-from io import BytesIO
-import requests
-url = "https://media.roboflow.com/dog.jpeg"
-image = Image.open(BytesIO(requests.get(url).content))
+=== "Object Detection"
-model = get_model("rfdetr-base") # replace with your Roboflow model ID
+ ```python
+ import os
+ import supervision as sv
+ from inference import get_model
+ from PIL import Image
+ from io import BytesIO
+ import requests
-predictions = model.infer(image, confidence=0.5)[0]
+ url = "https://media.roboflow.com/dog.jpeg"
+ image = Image.open(BytesIO(requests.get(url).content))
-detections = sv.Detections.from_inference(predictions)
+ model = get_model("rfdetr-base") # replace with your Roboflow model ID
-labels = [prediction.class_name for prediction in predictions.predictions]
+ predictions = model.infer(image, confidence=0.5)[0]
-annotated_image = image.copy()
-annotated_image = sv.BoxAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections)
-annotated_image = sv.LabelAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections, labels)
+ detections = sv.Detections.from_inference(predictions)
-sv.plot_image(annotated_image)
-```
+ labels = [prediction.class_name for prediction in predictions.predictions]
+
+ annotated_image = image.copy()
+ annotated_image = sv.BoxAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections)
+ annotated_image = sv.LabelAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections, labels)
+
+ sv.plot_image(annotated_image)
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ import os
+ import supervision as sv
+ from inference import get_model
+ from PIL import Image
+ from io import BytesIO
+ import requests
+
+ url = "https://media.roboflow.com/dog.jpeg"
+ image = Image.open(BytesIO(requests.get(url).content))
+
+ model = get_model("rfdetr-seg-preview") # replace with your Roboflow model ID
+
+ predictions = model.infer(image, confidence=0.5)[0]
+
+ detections = sv.Detections.from_inference(predictions)
+
+ labels = [prediction.class_name for prediction in predictions.predictions]
+
+ annotated_image = image.copy()
+ annotated_image = sv.MaskAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections)
+ annotated_image = sv.LabelAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections, labels)
+
+ sv.plot_image(annotated_image)
+ ```
Above, replace `rfdetr-base` with the your Roboflow model ID. You can find this ID from the "Models" list in your Roboflow dashboard:
diff --git a/docs/learn/run/detection.md b/docs/learn/run/detection.md
new file mode 100644
index 0000000..0e32164
--- /dev/null
+++ b/docs/learn/run/detection.md
@@ -0,0 +1,201 @@
+# Run an RF-DETR Object Detection Model
+
+You can run any of the four supported object detection RF-DETR base models (Nano, Small, Medium, Large) with [Inference](https://github.com/roboflow/inference), an open source computer vision inference server. The base models are trained on the [Microsoft COCO dataset](https://universe.roboflow.com/microsoft/coco).
+
+## Run a Model
+
+=== "Run on an Image"
+
+ To run RF-DETR on an image, use the following code:
+
+ ```python
+ import os
+ import supervision as sv
+ from inference import get_model
+ from PIL import Image
+ from io import BytesIO
+ import requests
+
+ url = "https://media.roboflow.com/dog.jpeg"
+ image = Image.open(BytesIO(requests.get(url).content))
+
+ model = get_model("rfdetr-base")
+
+ predictions = model.infer(image, confidence=0.5)[0]
+
+ detections = sv.Detections.from_inference(predictions)
+
+ labels = [prediction.class_name for prediction in predictions.predictions]
+
+ annotated_image = image.copy()
+ annotated_image = sv.BoxAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections)
+ annotated_image = sv.LabelAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections, labels)
+
+ sv.plot_image(annotated_image)
+ ```
+
+ Above, replace the image URL with any image you want to use with the model.
+
+ Here are the results from the code above:
+
+
+ { width=300 }
+ RF-DETR Base predictions
+
+
+
+=== "Run on a Video File"
+
+ To run RF-DETR on a video file, use the following code:
+
+ ```python
+ import supervision as sv
+ from rfdetr import RFDETRBase
+ from rfdetr.util.coco_classes import COCO_CLASSES
+
+ model = RFDETRBase()
+
+ def callback(frame, index):
+ detections = model.predict(frame[:, :, ::-1], threshold=0.5)
+
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_frame = frame.copy()
+ annotated_frame = sv.BoxAnnotator().annotate(annotated_frame, detections)
+ annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
+ return annotated_frame
+
+ sv.process_video(
+ source_path=,
+ target_path=,
+ callback=callback
+ )
+ ```
+
+ Above, set your `SOURCE_VIDEO_PATH` and `TARGET_VIDEO_PATH` to the directories of the video you want to process and where you want to save the results from inference, respectively.
+
+=== "Run on a Webcam Stream"
+
+ To run RF-DETR on a webcam input, use the following code:
+
+ ```python
+ import cv2
+ import supervision as sv
+ from rfdetr import RFDETRBase
+ from rfdetr.util.coco_classes import COCO_CLASSES
+
+ model = RFDETRBase()
+
+ cap = cv2.VideoCapture(0)
+ while True:
+ success, frame = cap.read()
+ if not success:
+ break
+
+ detections = model.predict(frame[:, :, ::-1], threshold=0.5)
+
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_frame = frame.copy()
+ annotated_frame = sv.BoxAnnotator().annotate(annotated_frame, detections)
+ annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
+
+ cv2.imshow("Webcam", annotated_frame)
+
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+=== "Run on an RTSP Stream"
+
+ To run RF-DETR on an RTSP stream, use the following code:
+
+ ```python
+ import cv2
+ import supervision as sv
+ from rfdetr import RFDETRBase
+ from rfdetr.util.coco_classes import COCO_CLASSES
+
+ model = RFDETRBase()
+
+ cap = cv2.VideoCapture()
+ while True:
+ success, frame = cap.read()
+ if not success:
+ break
+
+ detections = model.predict(frame[:, :, ::-1], threshold=0.5)
+
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_frame = frame.copy()
+ annotated_frame = sv.BoxAnnotator().annotate(annotated_frame, detections)
+ annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
+
+ cv2.imshow("RTSP Stream", annotated_frame)
+
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+You can change the RF-DETR model that the code snippet above uses. To do so, update `rfdetr-base` to any of the following values:
+
+- `rfdetr-nano`
+- `rfdetr-small`
+- `rfdetr-medium`
+- `rfdetr-large`
+
+## Batch Inference
+
+You can provide `.predict()` with either a single image or a list of images. When multiple images are supplied, they are processed together in a single forward pass, resulting in a corresponding list of detections.
+
+```python
+import io
+import requests
+import supervision as sv
+from PIL import Image
+from rfdetr import RFDETRBase
+from rfdetr.util.coco_classes import COCO_CLASSES
+
+model = RFDETRBase()
+
+urls = [
+ "https://media.roboflow.com/notebooks/examples/dog-2.jpeg",
+ "https://media.roboflow.com/notebooks/examples/dog-3.jpeg"
+]
+
+images = [Image.open(io.BytesIO(requests.get(url).content)) for url in urls]
+
+detections_list = model.predict(images, threshold=0.5)
+
+for image, detections in zip(images, detections_list):
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_image = image.copy()
+ annotated_image = sv.BoxAnnotator().annotate(annotated_image, detections)
+ annotated_image = sv.LabelAnnotator().annotate(annotated_image, detections, labels)
+
+ sv.plot_image(annotated_image)
+```
\ No newline at end of file
diff --git a/docs/learn/run/segmentation.md b/docs/learn/run/segmentation.md
new file mode 100644
index 0000000..7abef0f
--- /dev/null
+++ b/docs/learn/run/segmentation.md
@@ -0,0 +1,194 @@
+# Run an RF-DETR Instance Segmentation Model
+
+You can run models trained with the RF-DETR-Seg (Preview) architecture with [Inference](https://github.com/roboflow/inference), an open source computer vision inference server. The base models are trained on the [Microsoft COCO dataset](https://universe.roboflow.com/microsoft/coco).
+
+## Run a Model
+
+=== "Run on an Image"
+
+ To run RF-DETR on an image, use the following code:
+
+ ```python
+ import os
+ import supervision as sv
+ from inference import get_model
+ from PIL import Image
+ from io import BytesIO
+ import requests
+
+ url = "https://media.roboflow.com/dog.jpeg"
+ image = Image.open(BytesIO(requests.get(url).content))
+
+ model = get_model("rfdetr-seg-preview")
+
+ predictions = model.infer(image, confidence=0.5)[0]
+
+ detections = sv.Detections.from_inference(predictions)
+
+ labels = [prediction.class_name for prediction in predictions.predictions]
+
+ annotated_image = image.copy()
+ annotated_image = sv.MaskAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections)
+ annotated_image = sv.LabelAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections, labels)
+
+ sv.plot_image(annotated_image)
+ ```
+
+ Above, replace the image URL with any image you want to use with the model.
+
+ Here are the results from the code above:
+
+
+ { width=300 }
+ RF-DETR Base predictions
+
+
+
+=== "Run on a Video File"
+
+ To run RF-DETR on a video file, use the following code:
+
+ ```python
+ import supervision as sv
+ from rfdetr import RFDETRBase
+ from rfdetr.util.coco_classes import COCO_CLASSES
+
+ model = RFDETRBase()
+
+ def callback(frame, index):
+ detections = model.predict(frame[:, :, ::-1], threshold=0.5)
+
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_frame = frame.copy()
+ annotated_frame = sv.MaskAnnotator().annotate(annotated_frame, detections)
+ annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
+ return annotated_frame
+
+ sv.process_video(
+ source_path=,
+ target_path=,
+ callback=callback
+ )
+ ```
+
+ Above, set your `SOURCE_VIDEO_PATH` and `TARGET_VIDEO_PATH` to the directories of the video you want to process and where you want to save the results from inference, respectively.
+
+=== "Run on a Webcam Stream"
+
+ To run RF-DETR on a webcam input, use the following code:
+
+ ```python
+ import cv2
+ import supervision as sv
+ from rfdetr import RFDETRBase
+ from rfdetr.util.coco_classes import COCO_CLASSES
+
+ model = RFDETRBase()
+
+ cap = cv2.VideoCapture(0)
+ while True:
+ success, frame = cap.read()
+ if not success:
+ break
+
+ detections = model.predict(frame[:, :, ::-1], threshold=0.5)
+
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_frame = frame.copy()
+ annotated_frame = sv.MaskAnnotator().annotate(annotated_frame, detections)
+ annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
+
+ cv2.imshow("Webcam", annotated_frame)
+
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+=== "Run on an RTSP Stream"
+
+ To run RF-DETR on an RTSP stream, use the following code:
+
+ ```python
+ import cv2
+ import supervision as sv
+ from rfdetr import RFDETRBase
+ from rfdetr.util.coco_classes import COCO_CLASSES
+
+ model = RFDETRBase()
+
+ cap = cv2.VideoCapture()
+ while True:
+ success, frame = cap.read()
+ if not success:
+ break
+
+ detections = model.predict(frame[:, :, ::-1], threshold=0.5)
+
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_frame = frame.copy()
+ annotated_frame = sv.MaskAnnotator().annotate(annotated_frame, detections)
+ annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
+
+ cv2.imshow("RTSP Stream", annotated_frame)
+
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+## Batch Inference
+
+You can provide `.predict()` with either a single image or a list of images using the `rfdetr` package for use in batch inference applications. When multiple images are supplied, they are processed together in a single forward pass, resulting in a corresponding list of detections.
+
+```python
+import io
+import requests
+import supervision as sv
+from PIL import Image
+from rfdetr import RFDETRSegPreview
+from rfdetr.util.coco_classes import COCO_CLASSES
+
+model = RFDETRSegPreview()
+
+urls = [
+ "https://media.roboflow.com/notebooks/examples/dog-2.jpeg",
+ "https://media.roboflow.com/notebooks/examples/dog-3.jpeg"
+]
+
+images = [Image.open(io.BytesIO(requests.get(url).content)) for url in urls]
+
+detections_list = model.predict(images, threshold=0.5)
+
+for image, detections in zip(images, detections_list):
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_image = image.copy()
+ annotated_image = sv.MaskAnnotator().annotate(annotated_image, detections)
+ annotated_image = sv.LabelAnnotator().annotate(annotated_image, detections, labels)
+
+ sv.plot_image(annotated_image)
+```
\ No newline at end of file
diff --git a/docs/learn/train.md b/docs/learn/train/index.md
similarity index 76%
rename from docs/learn/train.md
rename to docs/learn/train/index.md
index 14fcb16..a0efc64 100644
--- a/docs/learn/train.md
+++ b/docs/learn/train/index.md
@@ -1,18 +1,12 @@
# Train an RF-DETR Model
-You can train an RF-DETR model on a custom dataset using the `rfdetr` Python package, or in the cloud using Roboflow.
+You can train RF-DETR object detection and segmentation models on a custom dataset using the `rfdetr` Python package, or in the cloud using Roboflow.
-Training on device is ideal if you want to manage your training pipeline and have a GPU available for training.
-
-Training in the Roboflow Cloud is ideal if you want managed training whose weights you can deploy on your own hardware and with a hosted API.
-
-For this guide, we will train a model using the `rfdetr` Python package.
-
-Once you have trained a model with this guide, see our [deploy an RF-DETR model guide](/learn/deploy/) to learn how to run inference with your model.
+This guide describes how to train both an object detection and segmentation RF-DETR model.
### Dataset structure
-RF-DETR expects the dataset to be in COCO format. Divide your dataset into three subdirectories: `train`, `valid`, and `test`. Each subdirectory should contain its own `_annotations.coco.json` file that holds the annotations for that particular split, along with the corresponding image files. Below is an example of the directory structure:
+RF-DETR expects the dataset to be in COCO format. Divide your dataset into three subdirectories: `train`, `valid`, and `test`. Each sub-directory should contain its own `_annotations.coco.json` file that holds the annotations for that particular split, along with the corresponding image files. Below is an example of the directory structure:
```
dataset/
@@ -35,24 +29,49 @@ dataset/
[Roboflow](https://roboflow.com/annotate) allows you to create object detection datasets from scratch or convert existing datasets from formats like YOLO, and then export them in COCO JSON format for training. You can also explore [Roboflow Universe](https://universe.roboflow.com/) to find pre-labeled datasets for a range of use cases.
-### Fine-tuning
+If you are training a segmentation model, your COCO JSON annotations should have a `segmentation` key with the polygon associated with each annotation.
-You can fine-tune RF-DETR from pre-trained COCO checkpoints. By default, the RF-DETR-B checkpoint will be used. To get started quickly, please refer to our fine-tuning Google Colab [notebook](https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/how-to-finetune-rf-detr-on-detection-dataset.ipynb).
+## Start Training
-```python
-from rfdetr import RFDETRBase
+You can fine-tune RF-DETR from pre-trained COCO checkpoints.
-model = RFDETRBase()
+For object detection, the RF-DETR-B checkpoint is used by default. To get started quickly with training an object detection model, please refer to our fine-tuning Google Colab [notebook](https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/how-to-finetune-rf-detr-on-detection-dataset.ipynb).
-model.train(
- dataset_dir=,
- epochs=10,
- batch_size=4,
- grad_accum_steps=4,
- lr=1e-4,
- output_dir=
-)
-```
+For image segmentation, the RF-DETR-Seg (Preview) checkpoint is used by default.
+
+=== "Object Detection"
+
+ ```python
+ from rfdetr import RFDETRBase
+
+ model = RFDETRBase()
+
+ model.train(
+ dataset_dir=,
+ epochs=100,
+ batch_size=4,
+ grad_accum_steps=4,
+ lr=1e-4,
+ output_dir=
+ )
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ from rfdetr import RFDETRSegPreview
+
+ model = RFDETRSegPreview()
+
+ model.train(
+ dataset_dir=,
+ epochs=100,
+ batch_size=4,
+ grad_accum_steps=4,
+ lr=1e-4,
+ output_dir=
+ )
+ ```
Different GPUs have different VRAM capacities, so adjust batch_size and grad_accum_steps to maintain a total batch size of 16. For example, on a powerful GPU like the A100, use `batch_size=16` and `grad_accum_steps=1`; on smaller GPUs like the T4, use `batch_size=4` and `grad_accum_steps=4`. This gradient accumulation strategy helps train effectively even with limited memory.
@@ -192,41 +211,83 @@ During training, multiple model checkpoints are saved to the output directory:
You can resume training from a previously saved checkpoint by passing the path to the `checkpoint.pth` file using the `resume` argument. This is useful when training is interrupted or you want to continue fine-tuning an already partially trained model. The training loop will automatically load the weights and optimizer state from the provided checkpoint file.
-```python
-from rfdetr import RFDETRBase
+=== "Object Detection"
-model = RFDETRBase()
+ ```python
+ from rfdetr import RFDETRBase
+
+ model = RFDETRBase()
+
+ model.train(
+ dataset_dir=,
+ epochs=100,
+ batch_size=4,
+ grad_accum_steps=4,
+ lr=1e-4,
+ output_dir=,
+ resume=
+ )
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ from rfdetr import RFDETRSegPreview
+
+ model = RFDETRSegPreview()
+
+ model.train(
+ dataset_dir=,
+ epochs=100,
+ batch_size=4,
+ grad_accum_steps=4,
+ lr=1e-4,
+ output_dir=,
+ resume=
+ )
+ ```
-model.train(
- dataset_dir=,
- epochs=10,
- batch_size=4,
- grad_accum_steps=4,
- lr=1e-4,
- output_dir=,
- resume=
-)
-```
### Early stopping
Early stopping monitors validation mAP and halts training if improvements remain below a threshold for a set number of epochs. This can reduce wasted computation once the model converges. Additional parameters—such as `early_stopping_patience`, `early_stopping_min_delta`, and `early_stopping_use_ema`—let you fine-tune the stopping behavior.
-```python
-from rfdetr import RFDETRBase
+=== "Object Detection"
-model = RFDETRBase()
+ ```python
+ from rfdetr import RFDETRBase
+
+ model = RFDETRBase()
+
+ model.train(
+ dataset_dir=,
+ epochs=100,
+ batch_size=4
+ grad_accum_steps=4,
+ lr=1e-4,
+ output_dir=,
+ early_stopping=True
+ )
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ from rfdetr import RFDETRSegPreview
+
+ model = RFDETRSegPreview()
+
+ model.train(
+ dataset_dir=,
+ epochs=100,
+ batch_size=4
+ grad_accum_steps=4,
+ lr=1e-4,
+ output_dir=,
+ early_stopping=True
+ )
+ ```
-model.train(
- dataset_dir=,
- epochs=10,
- batch_size=4
- grad_accum_steps=4,
- lr=1e-4,
- output_dir=,
- early_stopping=True
-)
-```
### Multi-GPU training
@@ -262,7 +323,7 @@ Replace `8` in the `--nproc_per_node argument` with the number of GPUs you want
model.train(
dataset_dir=,
- epochs=10,
+ epochs=100,
batch_size=4,
grad_accum_steps=4,
lr=1e-4,
@@ -320,7 +381,7 @@ Replace `8` in the `--nproc_per_node argument` with the number of GPUs you want
model.train(
dataset_dir=,
- epochs=10,
+ epochs=100,
batch_size=4,
grad_accum_steps=4,
lr=1e-4,
@@ -337,13 +398,25 @@ Replace `8` in the `--nproc_per_node argument` with the number of GPUs you want
### Load and run fine-tuned model
-```python
-from rfdetr import RFDETRBase
+=== "Object Detection"
-model = RFDETRBase(pretrain_weights=)
+ ```python
+ from rfdetr import RFDETRBase
-detections = model.predict()
-```
+ model = RFDETRBase(pretrain_weights=)
+
+ detections = model.predict()
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ from rfdetr import RFDETRSegPreview
+
+ model = RFDETRSegPreview(pretrain_weights=)
+
+ detections = model.predict()
+ ```
## ONNX export
@@ -357,12 +430,24 @@ pip install rfdetr[onnxexport]
Then, run:
-```python
-from rfdetr import RFDETRBase
+=== "Object Detection"
-model = RFDETRBase(pretrain_weights=)
+ ```python
+ from rfdetr import RFDETRBase
-model.export()
-```
+ model = RFDETRBase(pretrain_weights=)
+
+ model.export()
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ from rfdetr import RFDETRSegPreview
+
+ model = RFDETRSegPreview(pretrain_weights=)
+
+ model.export()
+ ```
This command saves the ONNX model to the `output` directory.
\ No newline at end of file
diff --git a/docs/reference/seg_preview.md b/docs/reference/seg_preview.md
new file mode 100644
index 0000000..7cc335c
--- /dev/null
+++ b/docs/reference/seg_preview.md
@@ -0,0 +1,3 @@
+:::rfdetr.detr.RFDETRSegPreview
+ options:
+ inherited_members: true
diff --git a/mkdocs.yaml b/mkdocs.yaml
index e02ccff..29ef895 100644
--- a/mkdocs.yaml
+++ b/mkdocs.yaml
@@ -23,18 +23,22 @@ extra:
nav:
- Home: index.md
- Learn:
- - Run a Pre-Trained Model: learn/pretrained.md
- - Train an RF-DETR Model: learn/train.md
- - Deploy a Trained Model: learn/deploy.md
- - Benchmarks: learn/benchmarks.md
+ - Run a Model:
+ - Object Detection: learn/run/detection.md
+ - Segmentation: learn/run/segmentation.md
+ - Train a Model: learn/train/index.md
+ - Deploy a Trained Model: learn/deploy.md
+ - Benchmarks: learn/benchmarks.md
- Reference:
- RF-DETR: reference/rfdetr.md
- - Models:
+ - Object Detection Models:
- RF-DETR Nano: reference/nano.md
- RF-DETR Small: reference/small.md
- - RF-DETR Base: reference/base.md
+ - RF-DETR Base (Deprecated): reference/base.md
- RF-DETR Medium: reference/medium.md
- RF-DETR Large: reference/large.md
+ - Image Segmentation Models:
+ - RF-DETR Seg Preview: reference/seg_preview.md
- Changelog: https://github.com/roboflow/rf-detr/releases
theme:
diff --git a/pyproject.toml b/pyproject.toml
index f074930..090a8a3 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta"
[project]
name = "rfdetr"
-version = "1.2.1"
+version = "1.3.0"
description = "RF-DETR"
readme = "README.md"
authors = [
diff --git a/rfdetr/__init__.py b/rfdetr/__init__.py
index ef87e73..e66c3e4 100644
--- a/rfdetr/__init__.py
+++ b/rfdetr/__init__.py
@@ -9,4 +9,4 @@
if os.environ.get("PYTORCH_ENABLE_MPS_FALLBACK") is None:
os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
-from rfdetr.detr import RFDETRBase, RFDETRLarge, RFDETRNano, RFDETRSmall, RFDETRMedium
+from rfdetr.detr import RFDETRBase, RFDETRLarge, RFDETRNano, RFDETRSmall, RFDETRMedium, RFDETRSegPreview
diff --git a/rfdetr/config.py b/rfdetr/config.py
index 12f7fd7..8999cdf 100644
--- a/rfdetr/config.py
+++ b/rfdetr/config.py
@@ -33,6 +33,11 @@ class ModelConfig(BaseModel):
group_detr: int = 13
gradient_checkpointing: bool = False
positional_encoding_size: int
+ ia_bce_loss: bool = True
+ cls_loss_coef: float = 1.0
+ segmentation_head: bool = False
+ mask_downsample_ratio: int = 4
+
class RFDETRBaseConfig(ModelConfig):
"""
@@ -102,6 +107,19 @@ class RFDETRMediumConfig(RFDETRBaseConfig):
positional_encoding_size: int = 36
pretrain_weights: Optional[str] = "rf-detr-medium.pth"
+class RFDETRSegPreviewConfig(RFDETRBaseConfig):
+ segmentation_head: bool = True
+ out_feature_indexes: List[int] = [3, 6, 9, 12]
+ num_windows: int = 2
+ dec_layers: int = 4
+ patch_size: int = 12
+ resolution: int = 432
+ positional_encoding_size: int = 36
+ num_queries: int = 200
+ num_select: int = 200
+ pretrain_weights: Optional[str] = "rf-detr-seg-preview.pt"
+ num_classes: int = 90
+
class TrainConfig(BaseModel):
lr: float = 1e-4
lr_encoder: float = 1.5e-4
@@ -112,7 +130,7 @@ class TrainConfig(BaseModel):
ema_tau: int = 100
lr_drop: int = 100
checkpoint_interval: int = 10
- warmup_epochs: int = 0
+ warmup_epochs: float = 0.0
lr_vit_layer_decay: float = 0.8
lr_component_decay: float = 0.7
drop_path: float = 0.0
@@ -140,3 +158,12 @@ class TrainConfig(BaseModel):
run: Optional[str] = None
class_names: List[str] = None
run_test: bool = True
+ segmentation_head: bool = False
+
+
+class SegmentationTrainConfig(TrainConfig):
+ mask_point_sample_ratio: int = 16
+ mask_ce_loss_coef: float = 5.0
+ mask_dice_loss_coef: float = 5.0
+ cls_loss_coef: float = 5.0
+ segmentation_head: bool = True
diff --git a/rfdetr/datasets/coco.py b/rfdetr/datasets/coco.py
index ef47a4b..4e7a51a 100644
--- a/rfdetr/datasets/coco.py
+++ b/rfdetr/datasets/coco.py
@@ -23,6 +23,7 @@
import torch
import torch.utils.data
import torchvision
+import pycocotools.mask as coco_mask
import rfdetr.datasets.transforms as T
@@ -37,11 +38,37 @@ def compute_multi_scale_scales(resolution, expanded_scales=False, patch_size=16,
return proposed_scales
+def convert_coco_poly_to_mask(segmentations, height, width):
+ """Convert polygon segmentation to a binary mask tensor of shape [N, H, W].
+ Requires pycocotools.
+ """
+ masks = []
+ for polygons in segmentations:
+ if polygons is None or len(polygons) == 0:
+ # empty segmentation for this instance
+ masks.append(torch.zeros((height, width), dtype=torch.uint8))
+ continue
+ try:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ except:
+ rles = polygons
+ mask = coco_mask.decode(rles)
+ if mask.ndim < 3:
+ mask = mask[..., None]
+ mask = torch.as_tensor(mask, dtype=torch.uint8)
+ mask = mask.any(dim=2)
+ masks.append(mask)
+ if len(masks) == 0:
+ return torch.zeros((0, height, width), dtype=torch.uint8)
+ return torch.stack(masks, dim=0)
+
+
class CocoDetection(torchvision.datasets.CocoDetection):
- def __init__(self, img_folder, ann_file, transforms):
+ def __init__(self, img_folder, ann_file, transforms, include_masks=False):
super(CocoDetection, self).__init__(img_folder, ann_file)
self._transforms = transforms
- self.prepare = ConvertCoco()
+ self.include_masks = include_masks
+ self.prepare = ConvertCoco(include_masks=include_masks)
def __getitem__(self, idx):
img, target = super(CocoDetection, self).__getitem__(idx)
@@ -55,6 +82,9 @@ def __getitem__(self, idx):
class ConvertCoco(object):
+ def __init__(self, include_masks=False):
+ self.include_masks = include_masks
+
def __call__(self, image, target):
w, h = image.size
@@ -90,6 +120,20 @@ def __call__(self, image, target):
target["area"] = area[keep]
target["iscrowd"] = iscrowd[keep]
+ # add segmentation masks if requested, otherwise ensure consistent key when include_masks=True
+ if self.include_masks:
+ if len(anno) > 0 and 'segmentation' in anno[0]:
+ segmentations = [obj.get("segmentation", []) for obj in anno]
+ masks = convert_coco_poly_to_mask(segmentations, h, w)
+ if masks.numel() > 0:
+ target["masks"] = masks[keep]
+ else:
+ target["masks"] = torch.zeros((0, h, w), dtype=torch.uint8)
+ else:
+ target["masks"] = torch.zeros((0, h, w), dtype=torch.uint8)
+
+ target["masks"] = target["masks"].bool()
+
target["orig_size"] = torch.as_tensor([int(h), int(w)])
target["size"] = torch.as_tensor([int(h), int(w)])
@@ -255,6 +299,11 @@ def build_roboflow(image_set, args, resolution):
square_resize_div_64 = args.square_resize_div_64
except:
square_resize_div_64 = False
+
+ try:
+ include_masks = args.segmentation_head
+ except:
+ include_masks = False
if square_resize_div_64:
@@ -266,7 +315,7 @@ def build_roboflow(image_set, args, resolution):
skip_random_resize=not args.do_random_resize_via_padding,
patch_size=args.patch_size,
num_windows=args.num_windows
- ))
+ ), include_masks=include_masks)
else:
dataset = CocoDetection(img_folder, ann_file, transforms=make_coco_transforms(
image_set,
@@ -276,5 +325,5 @@ def build_roboflow(image_set, args, resolution):
skip_random_resize=not args.do_random_resize_via_padding,
patch_size=args.patch_size,
num_windows=args.num_windows
- ))
+ ), include_masks=include_masks)
return dataset
diff --git a/rfdetr/datasets/coco_eval.py b/rfdetr/datasets/coco_eval.py
index 5dd00a5..2c036c0 100644
--- a/rfdetr/datasets/coco_eval.py
+++ b/rfdetr/datasets/coco_eval.py
@@ -130,7 +130,7 @@ def prepare_for_coco_segmentation(self, predictions):
labels = prediction["labels"].tolist()
rles = [
- mask_util.encode(np.array(mask[0, :, :, np.newaxis], dtype=np.uint8, order="F"))[0]
+ mask_util.encode(np.array(mask.cpu()[0, :, :, np.newaxis], dtype=np.uint8, order="F"))[0]
for mask in masks
]
for rle in rles:
diff --git a/rfdetr/datasets/transforms.py b/rfdetr/datasets/transforms.py
index b5da93c..06d3161 100644
--- a/rfdetr/datasets/transforms.py
+++ b/rfdetr/datasets/transforms.py
@@ -253,6 +253,10 @@ def __call__(self, img, target=None):
target["size"] = torch.tensor([h, w])
+ if "masks" in target:
+ target['masks'] = interpolate(
+ target['masks'][:, None].float(), (h, w), mode="nearest")[:, 0] > 0.5
+
return rescaled_img, target
diff --git a/rfdetr/deploy/export.py b/rfdetr/deploy/export.py
index 9a50188..29d6c63 100644
--- a/rfdetr/deploy/export.py
+++ b/rfdetr/deploy/export.py
@@ -258,6 +258,12 @@ def main(args):
if args.backbone_only:
features = model(input_tensors)
print(f"PyTorch inference output shape: {features.shape}")
+ elif args.segmentation_head:
+ outputs = model(input_tensors)
+ dets = outputs['pred_boxes']
+ labels = outputs['pred_logits']
+ masks = outputs['pred_masks']
+ print(f"PyTorch inference output shapes - Boxes: {dets.shape}, Labels: {labels.shape}, Masks: {masks.shape}")
else:
outputs = model(input_tensors)
dets = outputs['pred_boxes']
@@ -273,4 +279,4 @@ def main(args):
output_file = onnx_simplify(output_file, input_names, input_tensors, args)
if args.tensorrt:
- output_file = trtexec(output_file, args)
+ output_file = trtexec(output_file, args)
\ No newline at end of file
diff --git a/rfdetr/detr.py b/rfdetr/detr.py
index 021bf69..1cb03a3 100644
--- a/rfdetr/detr.py
+++ b/rfdetr/detr.py
@@ -29,7 +29,9 @@
RFDETRNanoConfig,
RFDETRSmallConfig,
RFDETRMediumConfig,
+ RFDETRSegPreviewConfig,
TrainConfig,
+ SegmentationTrainConfig,
ModelConfig
)
from rfdetr.main import Model, download_pretrain_weights
@@ -122,19 +124,21 @@ def export(self, **kwargs):
self.model.export(**kwargs)
def train_from_config(self, config: TrainConfig, **kwargs):
- with open(
- os.path.join(config.dataset_dir, "train", "_annotations.coco.json"), "r"
- ) as f:
- anns = json.load(f)
- num_classes = len(anns["categories"])
- class_names = [c["name"] for c in anns["categories"] if c["supercategory"] != "none"]
- self.model.class_names = class_names
+ if config.dataset_file == "roboflow":
+ with open(
+ os.path.join(config.dataset_dir, "train", "_annotations.coco.json"), "r"
+ ) as f:
+ anns = json.load(f)
+ num_classes = len(anns["categories"])
+ class_names = [c["name"] for c in anns["categories"] if c["supercategory"] != "none"]
+ self.model.class_names = class_names
+ elif config.dataset_file == "coco":
+ class_names = COCO_CLASSES
+ num_classes = 90
+ else:
+ raise ValueError(f"Invalid dataset file: {config.dataset_file}")
if self.model_config.num_classes != num_classes:
- logger.warning(
- f"num_classes mismatch: model has {self.model_config.num_classes} classes, but your dataset has {num_classes} classes\n"
- f"reinitializing your detection head with {num_classes} classes."
- )
self.model.reinitialize_detection_head(num_classes)
train_config = config.dict()
@@ -179,7 +183,8 @@ def train_from_config(self, config: TrainConfig, **kwargs):
model=self.model,
patience=config.early_stopping_patience,
min_delta=config.early_stopping_min_delta,
- use_ema=config.early_stopping_use_ema
+ use_ema=config.early_stopping_use_ema,
+ segmentation_head=config.segmentation_head
)
self.callbacks["on_fit_epoch_end"].append(early_stopping_callback.update)
@@ -313,10 +318,11 @@ def predict(
if isinstance(predictions, tuple):
predictions = {
"pred_logits": predictions[1],
- "pred_boxes": predictions[0]
+ "pred_boxes": predictions[0],
+ "pred_masks": predictions[2]
}
target_sizes = torch.tensor(orig_sizes, device=self.model.device)
- results = self.model.postprocessors["bbox"](predictions, target_sizes=target_sizes)
+ results = self.model.postprocess(predictions, target_sizes=target_sizes)
detections_list = []
for result in results:
@@ -329,11 +335,23 @@ def predict(
labels = labels[keep]
boxes = boxes[keep]
- detections = sv.Detections(
- xyxy=boxes.float().cpu().numpy(),
- confidence=scores.float().cpu().numpy(),
- class_id=labels.cpu().numpy(),
- )
+ if "masks" in result:
+ masks = result["masks"]
+ masks = masks[keep]
+
+ detections = sv.Detections(
+ xyxy=boxes.float().cpu().numpy(),
+ confidence=scores.float().cpu().numpy(),
+ class_id=labels.cpu().numpy(),
+ mask=masks.squeeze(1).cpu().numpy(),
+ )
+ else:
+ detections = sv.Detections(
+ xyxy=boxes.float().cpu().numpy(),
+ confidence=scores.float().cpu().numpy(),
+ class_id=labels.cpu().numpy(),
+ )
+
detections_list.append(detections)
return detections_list if len(detections_list) > 1 else detections_list[0]
@@ -447,4 +465,12 @@ def get_model_config(self, **kwargs):
return RFDETRMediumConfig(**kwargs)
def get_train_config(self, **kwargs):
- return TrainConfig(**kwargs)
\ No newline at end of file
+ return TrainConfig(**kwargs)
+
+class RFDETRSegPreview(RFDETR):
+ size = "rfdetr-seg-preview"
+ def get_model_config(self, **kwargs):
+ return RFDETRSegPreviewConfig(**kwargs)
+
+ def get_train_config(self, **kwargs):
+ return SegmentationTrainConfig(**kwargs)
diff --git a/rfdetr/engine.py b/rfdetr/engine.py
index 31e68ca..cb589df 100644
--- a/rfdetr/engine.py
+++ b/rfdetr/engine.py
@@ -249,7 +249,7 @@ def coco_extended_metrics(coco_eval):
"recall" : macro_recall
}
-def evaluate(model, criterion, postprocessors, data_loader, base_ds, device, args=None):
+def evaluate(model, criterion, postprocess, data_loader, base_ds, device, args=None):
model.eval()
if args.fp16_eval:
model.half()
@@ -261,7 +261,7 @@ def evaluate(model, criterion, postprocessors, data_loader, base_ds, device, arg
)
header = "Test:"
- iou_types = tuple(k for k in ("segm", "bbox") if k in postprocessors.keys())
+ iou_types = ("bbox",) if not args.segmentation_head else ("bbox", "segm")
coco_evaluator = CocoEvaluator(base_ds, iou_types)
for samples, targets in metric_logger.log_every(data_loader, 10, header):
@@ -310,10 +310,10 @@ def evaluate(model, criterion, postprocessors, data_loader, base_ds, device, arg
metric_logger.update(class_error=loss_dict_reduced["class_error"])
orig_target_sizes = torch.stack([t["orig_size"] for t in targets], dim=0)
- results = postprocessors["bbox"](outputs, orig_target_sizes)
+ results_all = postprocess(outputs, orig_target_sizes)
res = {
target["image_id"].item(): output
- for target, output in zip(targets, results)
+ for target, output in zip(targets, results_all)
}
if coco_evaluator is not None:
coco_evaluator.update(res)
@@ -332,9 +332,10 @@ def evaluate(model, criterion, postprocessors, data_loader, base_ds, device, arg
if coco_evaluator is not None:
results_json = coco_extended_metrics(coco_evaluator.coco_eval["bbox"])
stats["results_json"] = results_json
- if "bbox" in postprocessors.keys():
+ if "bbox" in iou_types:
stats["coco_eval_bbox"] = coco_evaluator.coco_eval["bbox"].stats.tolist()
- if "segm" in postprocessors.keys():
+ if "segm" in iou_types:
+ results_json = coco_extended_metrics(coco_evaluator.coco_eval["segm"])
stats["coco_eval_masks"] = coco_evaluator.coco_eval["segm"].stats.tolist()
return stats, coco_evaluator
\ No newline at end of file
diff --git a/rfdetr/main.py b/rfdetr/main.py
index 14fe89c..f52a238 100644
--- a/rfdetr/main.py
+++ b/rfdetr/main.py
@@ -39,7 +39,7 @@
import rfdetr.util.misc as utils
from rfdetr.datasets import build_dataset, get_coco_api_from_dataset
from rfdetr.engine import evaluate, train_one_epoch
-from rfdetr.models import build_model, build_criterion_and_postprocessors
+from rfdetr.models import build_model, build_criterion_and_postprocessors, PostProcess
from rfdetr.util.benchmark import benchmark
from rfdetr.util.drop_scheduler import drop_scheduler
from rfdetr.util.files import download_file
@@ -54,12 +54,14 @@
HOSTED_MODELS = {
"rf-detr-base.pth": "https://storage.googleapis.com/rfdetr/rf-detr-base-coco.pth",
+ "rf-detr-base-o365.pth": "https://storage.googleapis.com/rfdetr/top-secret-1234/lwdetr_dinov2_small_o365_checkpoint.pth",
# below is a less converged model that may be better for finetuning but worse for inference
"rf-detr-base-2.pth": "https://storage.googleapis.com/rfdetr/rf-detr-base-2.pth",
"rf-detr-large.pth": "https://storage.googleapis.com/rfdetr/rf-detr-large.pth",
"rf-detr-nano.pth": "https://storage.googleapis.com/rfdetr/nano_coco/checkpoint_best_regular.pth",
"rf-detr-small.pth": "https://storage.googleapis.com/rfdetr/small_coco/checkpoint_best_regular.pth",
"rf-detr-medium.pth": "https://storage.googleapis.com/rfdetr/medium_coco/checkpoint_best_regular.pth",
+ "rf-detr-seg-preview.pt": "https://storage.googleapis.com/rfdetr/rf-detr-seg-preview.pt",
}
def download_pretrain_weights(pretrain_weights: str, redownload=False):
@@ -98,10 +100,6 @@ def __init__(self, **kwargs):
checkpoint_num_classes = checkpoint['model']['class_embed.bias'].shape[0]
if checkpoint_num_classes != args.num_classes + 1:
- logger.warning(
- f"num_classes mismatch: pretrain weights has {checkpoint_num_classes - 1} classes, but your model has {args.num_classes} classes\n"
- f"reinitializing detection head with {checkpoint_num_classes - 1} classes"
- )
self.reinitialize_detection_head(checkpoint_num_classes)
# add support to exclude_keys
# e.g., when load object365 pretrain, do not load `class_embed.[weight, bias]`
@@ -110,7 +108,7 @@ def __init__(self, **kwargs):
for exclude_key in args.pretrain_exclude_keys:
checkpoint['model'].pop(exclude_key)
if args.pretrain_keys_modify_to_load is not None:
- from util.obj365_to_coco_model import get_coco_pretrain_from_obj365
+ from rfdetr.util.obj365_to_coco_model import get_coco_pretrain_from_obj365
assert isinstance(args.pretrain_keys_modify_to_load, list)
for modify_key_to_load in args.pretrain_keys_modify_to_load:
try:
@@ -145,7 +143,7 @@ def __init__(self, **kwargs):
)
self.model.backbone[0].encoder = get_peft_model(self.model.backbone[0].encoder, lora_config)
self.model = self.model.to(self.device)
- self.criterion, self.postprocessors = build_criterion_and_postprocessors(args)
+ self.postprocess = PostProcess(num_select=args.num_select)
self.stop_early = False
def reinitialize_detection_head(self, num_classes):
@@ -179,7 +177,7 @@ def train(self, callbacks: DefaultDict[str, List[Callable]], **kwargs):
np.random.seed(seed)
random.seed(seed)
- criterion, postprocessors = build_criterion_and_postprocessors(args)
+ criterion, postprocess = build_criterion_and_postprocessors(args)
model = self.model
model.to(device)
@@ -202,7 +200,7 @@ def train(self, callbacks: DefaultDict[str, List[Callable]], **kwargs):
dataset_train = build_dataset(image_set='train', args=args, resolution=args.resolution)
dataset_val = build_dataset(image_set='val', args=args, resolution=args.resolution)
- dataset_test = build_dataset(image_set='test', args=args, resolution=args.resolution)
+ dataset_test = build_dataset(image_set='test' if args.dataset_file == "roboflow" else "val", args=args, resolution=args.resolution)
# for cosine annealing, calculate total training steps and warmup steps
total_batch_size_for_lr = args.batch_size * utils.get_world_size() * args.grad_accum_steps
@@ -303,9 +301,12 @@ def lr_lambda(current_step: int):
if args.eval:
test_stats, coco_evaluator = evaluate(
- model, criterion, postprocessors, data_loader_val, base_ds, device, args)
+ model, criterion, postprocess, data_loader_val, base_ds, device, args)
if args.output_dir:
- utils.save_on_master(coco_evaluator.coco_eval["bbox"].eval, output_dir / "eval.pth")
+ if not args.segmentation_head:
+ utils.save_on_master(coco_evaluator.coco_eval["bbox"].eval, output_dir / "eval.pth")
+ else:
+ utils.save_on_master(coco_evaluator.coco_eval["segm"].eval, output_dir / "eval.pth")
return
# for drop
@@ -323,7 +324,6 @@ def lr_lambda(current_step: int):
args.drop_path, args.epochs, num_training_steps_per_epoch,
args.cutoff_epoch, args.drop_mode, args.drop_schedule)
print("Min DP = %.7f, Max DP = %.7f" % (min(schedules['dp']), max(schedules['dp'])))
-
print("Start training")
start_time = time.time()
best_map_holder = BestMetricHolder(use_ema=args.use_ema)
@@ -370,13 +370,20 @@ def lr_lambda(current_step: int):
with torch.inference_mode():
test_stats, coco_evaluator = evaluate(
- model, criterion, postprocessors, data_loader_val, base_ds, device, args=args
+ model, criterion, postprocess, data_loader_val, base_ds, device, args=args
)
- map_regular = test_stats["coco_eval_bbox"][0]
+ if not args.segmentation_head:
+ map_regular = test_stats["coco_eval_bbox"][0]
+ else:
+ map_regular = test_stats["coco_eval_masks"][0]
_isbest = best_map_holder.update(map_regular, epoch, is_ema=False)
if _isbest:
best_map_5095 = max(best_map_5095, map_regular)
- best_map_50 = max(best_map_50, test_stats["coco_eval_bbox"][1])
+ if not args.segmentation_head:
+ map50 = test_stats["coco_eval_bbox"][1]
+ else:
+ map50 = test_stats["coco_eval_masks"][1]
+ best_map_50 = max(best_map_50, map50)
checkpoint_path = output_dir / 'checkpoint_best_regular.pth'
if not args.dont_save_weights:
utils.save_on_master({
@@ -392,14 +399,21 @@ def lr_lambda(current_step: int):
'n_parameters': n_parameters}
if args.use_ema:
ema_test_stats, _ = evaluate(
- self.ema_m.module, criterion, postprocessors, data_loader_val, base_ds, device, args=args
+ self.ema_m.module, criterion, postprocess, data_loader_val, base_ds, device, args=args
)
log_stats.update({f'ema_test_{k}': v for k,v in ema_test_stats.items()})
- map_ema = ema_test_stats["coco_eval_bbox"][0]
+ if not args.segmentation_head:
+ map_ema = ema_test_stats["coco_eval_bbox"][0]
+ else:
+ map_ema = ema_test_stats["coco_eval_masks"][0]
best_map_ema_5095 = max(best_map_ema_5095, map_ema)
_isbest = best_map_holder.update(map_ema, epoch, is_ema=True)
if _isbest:
- best_map_ema_50 = max(best_map_ema_50, ema_test_stats["coco_eval_bbox"][1])
+ if not args.segmentation_head:
+ map_ema_50 = ema_test_stats["coco_eval_bbox"][1]
+ else:
+ map_ema_50 = ema_test_stats["coco_eval_masks"][1]
+ best_map_ema_50 = max(best_map_ema_50, map_ema_50)
checkpoint_path = output_dir / 'checkpoint_best_ema.pth'
if not args.dont_save_weights:
utils.save_on_master({
@@ -437,8 +451,13 @@ def lr_lambda(current_step: int):
if epoch % 50 == 0:
filenames.append(f'{epoch:03}.pth')
for name in filenames:
- torch.save(coco_evaluator.coco_eval["bbox"].eval,
+ if not args.segmentation_head:
+ torch.save(coco_evaluator.coco_eval["bbox"].eval,
+ output_dir / "eval" / name)
+ else:
+ torch.save(coco_evaluator.coco_eval["segm"].eval,
output_dir / "eval" / name)
+
for callback in callbacks["on_fit_epoch_end"]:
callback(log_stats)
@@ -478,14 +497,13 @@ def lr_lambda(current_step: int):
self.model = self.ema_m.module
self.model.eval()
-
if args.run_test:
best_state_dict = torch.load(output_dir / 'checkpoint_best_total.pth', map_location='cpu', weights_only=False)['model']
model.load_state_dict(best_state_dict)
model.eval()
test_stats, _ = evaluate(
- model, criterion, postprocessors, data_loader_test, base_ds_test, device, args=args
+ model, criterion, postprocess, data_loader_test, base_ds_test, device, args=args
)
print(f"Test results: {test_stats}")
with open(output_dir / "results.json", "r") as f:
@@ -529,6 +547,12 @@ def export(self, output_dir="output", infer_dir=None, simplify=False, backbone_
if backbone_only:
features = model(input_tensors)
print(f"PyTorch inference output shape: {features.shape}")
+ elif self.args.segmentation_head:
+ outputs = model(input_tensors)
+ dets = outputs['pred_boxes']
+ labels = outputs['pred_logits']
+ masks = outputs['pred_masks']
+ print(f"PyTorch inference output shapes - Boxes: {dets.shape}, Labels: {labels.shape}, Masks: {masks.shape}")
else:
outputs = model(input_tensors)
dets = outputs['pred_boxes']
diff --git a/rfdetr/models/__init__.py b/rfdetr/models/__init__.py
index ba018eb..cfa4aa1 100644
--- a/rfdetr/models/__init__.py
+++ b/rfdetr/models/__init__.py
@@ -13,4 +13,4 @@
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
# ------------------------------------------------------------------------
-from .lwdetr import build_model, build_criterion_and_postprocessors
+from .lwdetr import build_model, build_criterion_and_postprocessors, PostProcess
diff --git a/rfdetr/models/backbone/dinov2_with_windowed_attn.py b/rfdetr/models/backbone/dinov2_with_windowed_attn.py
index b315c46..b3827a0 100644
--- a/rfdetr/models/backbone/dinov2_with_windowed_attn.py
+++ b/rfdetr/models/backbone/dinov2_with_windowed_attn.py
@@ -312,8 +312,8 @@ def forward(self, pixel_values: torch.Tensor, bool_masked_pos: Optional[torch.Te
num_w_patches_per_window = num_w_patches // self.config.num_windows
num_h_patches_per_window = num_h_patches // self.config.num_windows
num_windows = self.config.num_windows
- windowed_pixel_tokens = pixel_tokens_with_pos_embed.view(batch_size, num_windows, num_h_patches_per_window, num_windows, num_h_patches_per_window, -1)
- windowed_pixel_tokens = windowed_pixel_tokens.permute(0, 1, 3, 2, 4, 5)
+ windowed_pixel_tokens = pixel_tokens_with_pos_embed.reshape(batch_size * num_windows, num_h_patches_per_window, num_windows, num_h_patches_per_window, -1)
+ windowed_pixel_tokens = windowed_pixel_tokens.permute(0, 2, 1, 3, 4)
windowed_pixel_tokens = windowed_pixel_tokens.reshape(batch_size * num_windows ** 2, num_h_patches_per_window * num_w_patches_per_window, -1)
windowed_cls_token_with_pos_embed = cls_token_with_pos_embed.repeat(num_windows ** 2, 1, 1)
embeddings = torch.cat((windowed_cls_token_with_pos_embed, windowed_pixel_tokens), dim=1)
@@ -1100,8 +1100,8 @@ def forward(
num_h_patches_per_window = num_h_patches // self.config.num_windows
num_w_patches_per_window = num_w_patches // self.config.num_windows
hidden_state = hidden_state.reshape(B // num_windows_squared, num_windows_squared * HW, C)
- hidden_state = hidden_state.view(B // num_windows_squared, self.config.num_windows, self.config.num_windows, num_h_patches_per_window, num_w_patches_per_window, C)
- hidden_state = hidden_state.permute(0, 1, 3, 2, 4, 5)
+ hidden_state = hidden_state.reshape((B // num_windows_squared) * self.config.num_windows, self.config.num_windows, num_h_patches_per_window, num_w_patches_per_window, C)
+ hidden_state = hidden_state.permute(0, 2, 1, 3, 4)
hidden_state = hidden_state.reshape(batch_size, num_h_patches, num_w_patches, -1)
hidden_state = hidden_state.permute(0, 3, 1, 2).contiguous()
diff --git a/rfdetr/models/backbone/projector.py b/rfdetr/models/backbone/projector.py
index 3817557..cd9be4f 100644
--- a/rfdetr/models/backbone/projector.py
+++ b/rfdetr/models/backbone/projector.py
@@ -41,12 +41,9 @@ def forward(self, x):
LayerNorm forward
TODO: this is a hack to avoid overflow when using fp16
"""
- #if x.dtype == torch.half:
- # x = x / (x.max() + self.eps)
- u = x.mean(1, keepdim=True)
- s = (x - u).pow(2).mean(1, keepdim=True)
- x = (x - u) / torch.sqrt(s + self.eps)
- x = self.weight[:, None, None] * x + self.bias[:, None, None]
+ x = x.permute(0, 2, 3, 1)
+ x = F.layer_norm(x, (x.size(3),), self.weight, self.bias, self.eps)
+ x = x.permute(0, 3, 1, 2)
return x
@@ -103,7 +100,7 @@ def __init__(self, in_planes, out_planes, kernel=3, stride=1, groups=1, dilation
def forward(self, x):
""" forward """
- out = self.act(self.bn(self.conv(x)))
+ out = self.act(self.bn(self.conv(x.contiguous())))
return out
diff --git a/rfdetr/models/lwdetr.py b/rfdetr/models/lwdetr.py
index b871b72..9c1f058 100644
--- a/rfdetr/models/lwdetr.py
+++ b/rfdetr/models/lwdetr.py
@@ -34,12 +34,14 @@
from rfdetr.models.backbone import build_backbone
from rfdetr.models.matcher import build_matcher
from rfdetr.models.transformer import build_transformer
+from rfdetr.models.segmentation_head import SegmentationHead, get_uncertain_point_coords_with_randomness, point_sample
class LWDETR(nn.Module):
""" This is the Group DETR v3 module that performs object detection """
def __init__(self,
backbone,
transformer,
+ segmentation_head,
num_classes,
num_queries,
aux_loss=False,
@@ -64,7 +66,8 @@ def __init__(self,
hidden_dim = transformer.d_model
self.class_embed = nn.Linear(hidden_dim, num_classes)
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
-
+ self.segmentation_head = segmentation_head
+
query_dim=4
self.refpoint_embed = nn.Embedding(num_queries * group_detr, query_dim)
self.query_feat = nn.Embedding(num_queries * group_detr, hidden_dim)
@@ -126,7 +129,7 @@ def export(self):
m.export()
def forward(self, samples: NestedTensor, targets=None):
- """ The forward expects a NestedTensor, which consists of:
+ """ The forward expects a NestedTensor, which consists of:
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
@@ -176,9 +179,14 @@ def forward(self, samples: NestedTensor, targets=None):
outputs_class = self.class_embed(hs)
+ if self.segmentation_head is not None:
+ outputs_masks = self.segmentation_head(features[0].tensors, hs, samples.tensors.shape[-2:])
+
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
+ if self.segmentation_head is not None:
+ out['pred_masks'] = outputs_masks[-1]
if self.aux_loss:
- out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
+ out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord, outputs_masks if self.segmentation_head is not None else None)
if self.two_stage:
group_detr = self.group_detr if self.training else 1
@@ -187,12 +195,22 @@ def forward(self, samples: NestedTensor, targets=None):
for g_idx in range(group_detr):
cls_enc_gidx = self.transformer.enc_out_class_embed[g_idx](hs_enc_list[g_idx])
cls_enc.append(cls_enc_gidx)
+
cls_enc = torch.cat(cls_enc, dim=1)
+
+ if self.segmentation_head is not None:
+ masks_enc = self.segmentation_head(features[0].tensors, [hs_enc,], samples.tensors.shape[-2:], skip_blocks=True)
+ masks_enc = torch.cat(masks_enc, dim=1)
+
if hs is not None:
out['enc_outputs'] = {'pred_logits': cls_enc, 'pred_boxes': ref_enc}
+ if self.segmentation_head is not None:
+ out['enc_outputs']['pred_masks'] = masks_enc
else:
out = {'pred_logits': cls_enc, 'pred_boxes': ref_enc}
-
+ if self.segmentation_head is not None:
+ out['pred_masks'] = masks_enc
+
return out
def forward_export(self, tensors):
@@ -204,6 +222,8 @@ def forward_export(self, tensors):
hs, ref_unsigmoid, hs_enc, ref_enc = self.transformer(
srcs, None, poss, refpoint_embed_weight, query_feat_weight)
+ outputs_masks = None
+
if hs is not None:
if self.bbox_reparam:
outputs_coord_delta = self.bbox_embed(hs)
@@ -215,20 +235,28 @@ def forward_export(self, tensors):
else:
outputs_coord = (self.bbox_embed(hs) + ref_unsigmoid).sigmoid()
outputs_class = self.class_embed(hs)
+ if self.segmentation_head is not None:
+ outputs_masks = self.segmentation_head(srcs[0], [hs,], tensors.shape[-2:])[0]
else:
assert self.two_stage, "if not using decoder, two_stage must be True"
outputs_class = self.transformer.enc_out_class_embed[0](hs_enc)
outputs_coord = ref_enc
-
- return outputs_coord, outputs_class
+ if self.segmentation_head is not None:
+ outputs_masks = self.segmentation_head(srcs[0], [hs_enc,], tensors.shape[-2:], skip_blocks=True)[0]
+
+ return outputs_coord, outputs_class, outputs_masks
@torch.jit.unused
- def _set_aux_loss(self, outputs_class, outputs_coord):
+ def _set_aux_loss(self, outputs_class, outputs_coord, outputs_masks):
# this is a workaround to make torchscript happy, as torchscript
# doesn't support dictionary with non-homogeneous values, such
# as a dict having both a Tensor and a list.
- return [{'pred_logits': a, 'pred_boxes': b}
- for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
+ if outputs_masks is not None:
+ return [{'pred_logits': a, 'pred_boxes': b, 'pred_masks': c}
+ for a, b, c in zip(outputs_class[:-1], outputs_coord[:-1], outputs_masks[:-1])]
+ else:
+ return [{'pred_logits': a, 'pred_boxes': b}
+ for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
def update_drop_path(self, drop_path_rate, vit_encoder_num_layers):
""" """
@@ -254,16 +282,17 @@ class SetCriterion(nn.Module):
2) we supervise each pair of matched ground-truth / prediction (supervise class and box)
"""
def __init__(self,
- num_classes,
- matcher,
- weight_dict,
- focal_alpha,
- losses,
- group_detr=1,
- sum_group_losses=False,
- use_varifocal_loss=False,
- use_position_supervised_loss=False,
- ia_bce_loss=False,):
+ num_classes,
+ matcher,
+ weight_dict,
+ focal_alpha,
+ losses,
+ group_detr=1,
+ sum_group_losses=False,
+ use_varifocal_loss=False,
+ use_position_supervised_loss=False,
+ ia_bce_loss=False,
+ mask_point_sample_ratio: int = 16,):
""" Create the criterion.
Parameters:
num_classes: number of object categories, omitting the special no-object category
@@ -284,6 +313,7 @@ def __init__(self,
self.use_varifocal_loss = use_varifocal_loss
self.use_position_supervised_loss = use_position_supervised_loss
self.ia_bce_loss = ia_bce_loss
+ self.mask_point_sample_ratio = mask_point_sample_ratio
def loss_labels(self, outputs, targets, indices, num_boxes, log=True):
"""Classification loss (Binary focal loss)
@@ -412,7 +442,65 @@ def loss_boxes(self, outputs, targets, indices, num_boxes):
box_ops.box_cxcywh_to_xyxy(target_boxes)))
losses['loss_giou'] = loss_giou.sum() / num_boxes
return losses
+
+ def loss_masks(self, outputs, targets, indices, num_boxes):
+ """Compute BCE-with-logits and Dice losses for segmentation masks on matched pairs.
+ Expects outputs to contain 'pred_masks' of shape [B, Q, H, W] and targets with key 'masks'.
+ """
+ assert 'pred_masks' in outputs, "pred_masks missing in model outputs"
+ pred_masks = outputs['pred_masks'] # [B, Q, H, W]
+ # gather matched prediction masks
+ idx = self._get_src_permutation_idx(indices)
+ src_masks = pred_masks[idx] # [N, H, W]
+ # handle no matches
+ if src_masks.numel() == 0:
+ return {
+ 'loss_mask_ce': src_masks.sum(),
+ 'loss_mask_dice': src_masks.sum(),
+ }
+ # gather matched target masks
+ target_masks = torch.cat([t['masks'][j] for t, (_, j) in zip(targets, indices)], dim=0) # [N, Ht, Wt]
+
+ # No need to upsample predictions as we are using normalized coordinates :)
+ # N x 1 x H x W
+ src_masks = src_masks.unsqueeze(1)
+ target_masks = target_masks.unsqueeze(1).float()
+
+ num_points = max(src_masks.shape[-2], src_masks.shape[-2] * src_masks.shape[-1] // self.mask_point_sample_ratio)
+
+ with torch.no_grad():
+ # sample point_coords
+ point_coords = get_uncertain_point_coords_with_randomness(
+ src_masks,
+ lambda logits: calculate_uncertainty(logits),
+ num_points,
+ 3,
+ 0.75,
+ )
+ # get gt labels
+ point_labels = point_sample(
+ target_masks,
+ point_coords,
+ align_corners=False,
+ mode="nearest",
+ ).squeeze(1)
+
+ point_logits = point_sample(
+ src_masks,
+ point_coords,
+ align_corners=False,
+ ).squeeze(1)
+
+ losses = {
+ "loss_mask_ce": sigmoid_ce_loss_jit(point_logits, point_labels, num_boxes),
+ "loss_mask_dice": dice_loss_jit(point_logits, point_labels, num_boxes),
+ }
+ del src_masks
+ del target_masks
+ return losses
+
+
def _get_src_permutation_idx(self, indices):
# permute predictions following indices
batch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(indices)])
@@ -430,6 +518,7 @@ def get_loss(self, loss, outputs, targets, indices, num_boxes, **kwargs):
'labels': self.loss_labels,
'cardinality': self.loss_cardinality,
'boxes': self.loss_boxes,
+ 'masks': self.loss_masks,
}
assert loss in loss_map, f'do you really want to compute {loss} loss?'
return loss_map[loss](outputs, targets, indices, num_boxes, **kwargs)
@@ -540,6 +629,75 @@ def position_supervised_loss(inputs, targets, num_boxes, alpha: float = 0.25, ga
return loss.mean(1).sum() / num_boxes
+def dice_loss(
+ inputs: torch.Tensor,
+ targets: torch.Tensor,
+ num_masks: float,
+ ):
+ """
+ Compute the DICE loss, similar to generalized IOU for masks
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs
+ (0 for the negative class and 1 for the positive class).
+ """
+ inputs = inputs.sigmoid()
+ inputs = inputs.flatten(1)
+ numerator = 2 * (inputs * targets).sum(-1)
+ denominator = inputs.sum(-1) + targets.sum(-1)
+ loss = 1 - (numerator + 1) / (denominator + 1)
+ return loss.sum() / num_masks
+
+
+dice_loss_jit = torch.jit.script(
+ dice_loss
+) # type: torch.jit.ScriptModule
+
+
+def sigmoid_ce_loss(
+ inputs: torch.Tensor,
+ targets: torch.Tensor,
+ num_masks: float,
+ ):
+ """
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs
+ (0 for the negative class and 1 for the positive class).
+ Returns:
+ Loss tensor
+ """
+ loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
+
+ return loss.mean(1).sum() / num_masks
+
+
+sigmoid_ce_loss_jit = torch.jit.script(
+ sigmoid_ce_loss
+) # type: torch.jit.ScriptModule
+
+
+def calculate_uncertainty(logits):
+ """
+ We estimate uncerainty as L1 distance between 0.0 and the logit prediction in 'logits' for the
+ foreground class in `classes`.
+ Args:
+ logits (Tensor): A tensor of shape (R, 1, ...) for class-specific or
+ class-agnostic, where R is the total number of predicted masks in all images and C is
+ the number of foreground classes. The values are logits.
+ Returns:
+ scores (Tensor): A tensor of shape (R, 1, ...) that contains uncertainty scores with
+ the most uncertain locations having the highest uncertainty score.
+ """
+ assert logits.shape[1] == 1
+ gt_class_logits = logits.clone()
+ return -(torch.abs(gt_class_logits))
+
+
class PostProcess(nn.Module):
""" This module converts the model's output into the format expected by the coco api"""
def __init__(self, num_select=300) -> None:
@@ -556,6 +714,7 @@ def forward(self, outputs, target_sizes):
For visualization, this should be the image size after data augment, but before padding
"""
out_logits, out_bbox = outputs['pred_logits'], outputs['pred_boxes']
+ out_masks = outputs.get('pred_masks', None)
assert len(out_logits) == len(target_sizes)
assert target_sizes.shape[1] == 2
@@ -573,7 +732,19 @@ def forward(self, outputs, target_sizes):
scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
boxes = boxes * scale_fct[:, None, :]
- results = [{'scores': s, 'labels': l, 'boxes': b} for s, l, b in zip(scores, labels, boxes)]
+ # Optionally gather masks corresponding to the same top-K queries and resize to original size
+ results = []
+ if out_masks is not None:
+ for i in range(out_masks.shape[0]):
+ res_i = {'scores': scores[i], 'labels': labels[i], 'boxes': boxes[i]}
+ k_idx = topk_boxes[i]
+ masks_i = torch.gather(out_masks[i], 0, k_idx.unsqueeze(-1).unsqueeze(-1).repeat(1, out_masks.shape[-2], out_masks.shape[-1])) # [K, Hm, Wm]
+ h, w = target_sizes[i].tolist()
+ masks_i = F.interpolate(masks_i.unsqueeze(1), size=(int(h), int(w)), mode='bilinear', align_corners=False) # [K,1,H,W]
+ res_i['masks'] = masks_i > 0.0
+ results.append(res_i)
+ else:
+ results = [{'scores': s, 'labels': l, 'boxes': b} for s, l, b in zip(scores, labels, boxes)]
return results
@@ -638,9 +809,12 @@ def build_model(args):
args.num_feature_levels = len(args.projector_scale)
transformer = build_transformer(args)
+ segmentation_head = SegmentationHead(args.hidden_dim, args.dec_layers, downsample_ratio=args.mask_downsample_ratio) if args.segmentation_head else None
+
model = LWDETR(
backbone,
transformer,
+ segmentation_head,
num_classes=num_classes,
num_queries=args.num_queries,
aux_loss=args.aux_loss,
@@ -656,6 +830,9 @@ def build_criterion_and_postprocessors(args):
matcher = build_matcher(args)
weight_dict = {'loss_ce': args.cls_loss_coef, 'loss_bbox': args.bbox_loss_coef}
weight_dict['loss_giou'] = args.giou_loss_coef
+ if args.segmentation_head:
+ weight_dict['loss_mask_ce'] = args.mask_ce_loss_coef
+ weight_dict['loss_mask_dice'] = args.mask_dice_loss_coef
# TODO this is a hack
if args.aux_loss:
aux_weight_dict = {}
@@ -666,18 +843,29 @@ def build_criterion_and_postprocessors(args):
weight_dict.update(aux_weight_dict)
losses = ['labels', 'boxes', 'cardinality']
+ if args.segmentation_head:
+ losses.append('masks')
try:
sum_group_losses = args.sum_group_losses
except:
sum_group_losses = False
- criterion = SetCriterion(args.num_classes + 1, matcher=matcher, weight_dict=weight_dict,
- focal_alpha=args.focal_alpha, losses=losses,
- group_detr=args.group_detr, sum_group_losses=sum_group_losses,
- use_varifocal_loss = args.use_varifocal_loss,
- use_position_supervised_loss=args.use_position_supervised_loss,
- ia_bce_loss=args.ia_bce_loss)
+ if args.segmentation_head:
+ criterion = SetCriterion(args.num_classes + 1, matcher=matcher, weight_dict=weight_dict,
+ focal_alpha=args.focal_alpha, losses=losses,
+ group_detr=args.group_detr, sum_group_losses=sum_group_losses,
+ use_varifocal_loss = args.use_varifocal_loss,
+ use_position_supervised_loss=args.use_position_supervised_loss,
+ ia_bce_loss=args.ia_bce_loss,
+ mask_point_sample_ratio=args.mask_point_sample_ratio)
+ else:
+ criterion = SetCriterion(args.num_classes + 1, matcher=matcher, weight_dict=weight_dict,
+ focal_alpha=args.focal_alpha, losses=losses,
+ group_detr=args.group_detr, sum_group_losses=sum_group_losses,
+ use_varifocal_loss = args.use_varifocal_loss,
+ use_position_supervised_loss=args.use_position_supervised_loss,
+ ia_bce_loss=args.ia_bce_loss)
criterion.to(device)
- postprocessors = {'bbox': PostProcess(num_select=args.num_select)}
+ postprocess = PostProcess(num_select=args.num_select)
- return criterion, postprocessors
+ return criterion, postprocess
diff --git a/rfdetr/models/matcher.py b/rfdetr/models/matcher.py
index 1e9afb7..fe8f019 100644
--- a/rfdetr/models/matcher.py
+++ b/rfdetr/models/matcher.py
@@ -23,8 +23,11 @@
import torch
from scipy.optimize import linear_sum_assignment
from torch import nn
+import torch.nn.functional as F
+
+from rfdetr.util.box_ops import box_cxcywh_to_xyxy, generalized_box_iou, batch_sigmoid_ce_loss, batch_dice_loss
+from rfdetr.models.segmentation_head import point_sample
-from rfdetr.util.box_ops import box_cxcywh_to_xyxy, generalized_box_iou
class HungarianMatcher(nn.Module):
"""This class computes an assignment between the targets and the predictions of the network
@@ -34,7 +37,7 @@ class HungarianMatcher(nn.Module):
"""
def __init__(self, cost_class: float = 1, cost_bbox: float = 1, cost_giou: float = 1, focal_alpha: float = 0.25, use_pos_only: bool = False,
- use_position_modulated_cost: bool = False):
+ use_position_modulated_cost: bool = False, mask_point_sample_ratio: int = 16, cost_mask_ce: float = 1, cost_mask_dice: float = 1):
"""Creates the matcher
Params:
cost_class: This is the relative weight of the classification error in the matching cost
@@ -47,6 +50,9 @@ def __init__(self, cost_class: float = 1, cost_bbox: float = 1, cost_giou: float
self.cost_giou = cost_giou
assert cost_class != 0 or cost_bbox != 0 or cost_giou != 0, "all costs cant be 0"
self.focal_alpha = focal_alpha
+ self.mask_point_sample_ratio = mask_point_sample_ratio
+ self.cost_mask_ce = cost_mask_ce
+ self.cost_mask_dice = cost_mask_dice
@torch.no_grad()
def forward(self, outputs, targets, group_detr=1):
@@ -59,6 +65,7 @@ def forward(self, outputs, targets, group_detr=1):
"labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of ground-truth
objects in the target) containing the class labels
"boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates
+ "masks": Tensor of dim [num_target_boxes, H, W] containing the target mask coordinates
group_detr: Number of groups used for matching.
Returns:
A list of size batch_size, containing tuples of (index_i, index_j) where:
@@ -70,13 +77,20 @@ def forward(self, outputs, targets, group_detr=1):
bs, num_queries = outputs["pred_logits"].shape[:2]
# We flatten to compute the cost matrices in a batch
- out_prob = outputs["pred_logits"].flatten(0, 1).sigmoid() # [batch_size * num_queries, num_classes]
+ flat_pred_logits = outputs["pred_logits"].flatten(0, 1)
+ out_prob = flat_pred_logits.sigmoid() # [batch_size * num_queries, num_classes]
out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
# Also concat the target labels and boxes
tgt_ids = torch.cat([v["labels"] for v in targets])
tgt_bbox = torch.cat([v["boxes"] for v in targets])
+ masks_present = "masks" in targets[0]
+
+ if masks_present:
+ tgt_masks = torch.cat([v["masks"] for v in targets])
+ out_masks = outputs["pred_masks"].flatten(0, 1)
+
# Compute the giou cost betwen boxes
giou = generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox))
cost_giou = -giou
@@ -85,16 +99,49 @@ def forward(self, outputs, targets, group_detr=1):
alpha = 0.25
gamma = 2.0
- neg_cost_class = (1 - alpha) * (out_prob ** gamma) * (-(1 - out_prob + 1e-8).log())
- pos_cost_class = alpha * ((1 - out_prob) ** gamma) * (-(out_prob + 1e-8).log())
+ # neg_cost_class = (1 - alpha) * (out_prob ** gamma) * (-(1 - out_prob + 1e-8).log())
+ # pos_cost_class = alpha * ((1 - out_prob) ** gamma) * (-(out_prob + 1e-8).log())
+ # we refactor these with logsigmoid for numerical stability
+ neg_cost_class = (1 - alpha) * (out_prob ** gamma) * (-F.logsigmoid(-flat_pred_logits))
+ pos_cost_class = alpha * ((1 - out_prob) ** gamma) * (-F.logsigmoid(flat_pred_logits))
cost_class = pos_cost_class[:, tgt_ids] - neg_cost_class[:, tgt_ids]
# Compute the L1 cost between boxes
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1)
+ if masks_present:
+ # Resize predicted masks to target mask size if needed
+ # if out_masks.shape[-2:] != tgt_masks.shape[-2:]:
+ # # out_masks = F.interpolate(out_masks.unsqueeze(1), size=tgt_masks.shape[-2:], mode="bilinear", align_corners=False).squeeze(1)
+ # tgt_masks = F.interpolate(tgt_masks.unsqueeze(1).float(), size=out_masks.shape[-2:], mode="bilinear", align_corners=False).squeeze(1)
+
+ # # Flatten masks
+ # pred_masks_logits = out_masks.flatten(1) # [P, HW]
+ # tgt_masks_flat = tgt_masks.flatten(1).float() # [T, HW]
+
+ num_points = out_masks.shape[-2] * out_masks.shape[-1] // self.mask_point_sample_ratio
+
+ tgt_masks = tgt_masks.to(out_masks.dtype)
+
+ point_coords = torch.rand(1, num_points, 2, device=out_masks.device)
+ pred_masks_logits = point_sample(out_masks.unsqueeze(1), point_coords.repeat(out_masks.shape[0], 1, 1), align_corners=False).squeeze(1)
+ tgt_masks_flat = point_sample(tgt_masks.unsqueeze(1), point_coords.repeat(tgt_masks.shape[0], 1, 1), align_corners=False, mode="nearest").squeeze(1)
+
+ # Binary cross-entropy with logits cost (mean over pixels), computed pairwise efficiently
+ cost_mask_ce = batch_sigmoid_ce_loss(pred_masks_logits, tgt_masks_flat)
+
+ # Dice loss cost (1 - dice coefficient)
+ cost_mask_dice = batch_dice_loss(pred_masks_logits, tgt_masks_flat)
+
# Final cost matrix
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
- C = C.view(bs, num_queries, -1).cpu()
+ if masks_present:
+ C = C + self.cost_mask_ce * cost_mask_ce + self.cost_mask_dice * cost_mask_dice
+ C = C.view(bs, num_queries, -1).float().cpu() # convert to float because bfloat16 doesn't play nicely with CPU
+
+ # we assume any good match will not cause NaN or Inf, so we replace them with a large value
+ max_cost = C.max() if C.numel() > 0 else 0
+ C[C.isinf() | C.isnan()] = max_cost * 2
sizes = [len(v["boxes"]) for v in targets]
indices = []
@@ -114,8 +161,19 @@ def forward(self, outputs, targets, group_detr=1):
def build_matcher(args):
- return HungarianMatcher(
- cost_class=args.set_cost_class,
- cost_bbox=args.set_cost_bbox,
- cost_giou=args.set_cost_giou,
- focal_alpha=args.focal_alpha,)
\ No newline at end of file
+ if args.segmentation_head:
+ return HungarianMatcher(
+ cost_class=args.set_cost_class,
+ cost_bbox=args.set_cost_bbox,
+ cost_giou=args.set_cost_giou,
+ focal_alpha=args.focal_alpha,
+ cost_mask_ce=args.mask_ce_loss_coef,
+ cost_mask_dice=args.mask_dice_loss_coef,
+ mask_point_sample_ratio=args.mask_point_sample_ratio,)
+ else:
+ return HungarianMatcher(
+ cost_class=args.set_cost_class,
+ cost_bbox=args.set_cost_bbox,
+ cost_giou=args.set_cost_giou,
+ focal_alpha=args.focal_alpha,
+ )
\ No newline at end of file
diff --git a/rfdetr/models/segmentation_head.py b/rfdetr/models/segmentation_head.py
new file mode 100644
index 0000000..20e9164
--- /dev/null
+++ b/rfdetr/models/segmentation_head.py
@@ -0,0 +1,202 @@
+# ------------------------------------------------------------------------
+# RF-DETR
+# Copyright (c) 2025 Roboflow. All Rights Reserved.
+# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
+# ------------------------------------------------------------------------
+
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from typing import Callable
+
+
+class DepthwiseConvBlock(nn.Module):
+ r""" Simplified ConvNeXt block without the MLP subnet
+ """
+ def __init__(self, dim, layer_scale_init_value=0):
+ super().__init__()
+ self.dwconv = nn.Conv2d(dim, dim, kernel_size=3, padding=1, groups=dim) # depthwise conv
+ self.norm = nn.LayerNorm(dim, eps=1e-6)
+ self.pwconv1 = nn.Linear(dim, dim) # pointwise/1x1 convs, implemented with linear layers
+ self.act = nn.GELU()
+ self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
+ requires_grad=True) if layer_scale_init_value > 0 else None
+
+ def forward(self, x):
+ input = x
+ x = self.dwconv(x)
+ x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
+ x = self.norm(x)
+ x = self.pwconv1(x)
+ x = self.act(x)
+ if self.gamma is not None:
+ x = self.gamma * x
+ x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
+
+ return x + input
+
+
+class MLPBlock(nn.Module):
+ def __init__(self, dim, layer_scale_init_value=0):
+ super().__init__()
+ self.norm_in = nn.LayerNorm(dim)
+ self.layers = nn.ModuleList([
+ nn.Linear(dim, dim*4),
+ nn.GELU(),
+ nn.Linear(dim*4, dim),
+ ])
+ self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
+ requires_grad=True) if layer_scale_init_value > 0 else None
+
+ def forward(self, x):
+ input = x
+ x = self.norm_in(x)
+ for layer in self.layers:
+ x = layer(x)
+ if self.gamma is not None:
+ x = self.gamma * x
+ return x + input
+
+
+class SegmentationHead(nn.Module):
+ def __init__(self, in_dim, num_blocks: int, bottleneck_ratio: int=1, downsample_ratio: int=4):
+ super().__init__()
+
+ self.downsample_ratio = downsample_ratio
+ self.interaction_dim = in_dim // bottleneck_ratio if bottleneck_ratio is not None else in_dim
+ self.blocks = nn.ModuleList([DepthwiseConvBlock(in_dim) for _ in range(num_blocks)])
+ self.spatial_features_proj = nn.Identity() if bottleneck_ratio is None else nn.Conv2d(in_dim, self.interaction_dim, kernel_size=1)
+
+ self.query_features_block = MLPBlock(in_dim)
+ self.query_features_proj = nn.Identity() if bottleneck_ratio is None else nn.Linear(in_dim, self.interaction_dim)
+
+ self.bias = nn.Parameter(torch.zeros(1), requires_grad=True)
+
+ self._export = False
+
+ def export(self):
+ self._export = True
+ self._forward_origin = self.forward
+ self.forward = self.forward_export
+ for name, m in self.named_modules():
+ if hasattr(m, "export") and isinstance(m.export, Callable) and hasattr(m, "_export") and not m._export:
+ m.export()
+
+ def forward(self, spatial_features: torch.Tensor, query_features: list[torch.Tensor], image_size: tuple[int, int], skip_blocks: bool=False) -> list[torch.Tensor]:
+ # spatial features: (B, C, H, W)
+ # query features: [(B, N, C)] for each decoder layer
+ # output: (B, N, H*r, W*r)
+ target_size = (image_size[0] // self.downsample_ratio, image_size[1] // self.downsample_ratio)
+ spatial_features = F.interpolate(spatial_features, size=target_size, mode='bilinear', align_corners=False)
+
+ mask_logits = []
+ if not skip_blocks:
+ for block, qf in zip(self.blocks, query_features):
+ spatial_features = block(spatial_features)
+ spatial_features_proj = self.spatial_features_proj(spatial_features)
+ qf = self.query_features_proj(self.query_features_block(qf))
+ mask_logits.append(torch.einsum('bchw,bnc->bnhw', spatial_features_proj, qf) + self.bias)
+ else:
+ assert len(query_features) == 1, "skip_blocks is only supported for length 1 query features"
+ qf = self.query_features_proj(self.query_features_block(query_features[0]))
+ mask_logits.append(torch.einsum('bchw,bnc->bnhw', spatial_features, qf) + self.bias)
+
+ return mask_logits
+
+ def forward_export(self, spatial_features: torch.Tensor, query_features: list[torch.Tensor], image_size: tuple[int, int], skip_blocks: bool=False) -> list[torch.Tensor]:
+ assert len(query_features) == 1, "at export time, segmentation head expects exactly one query feature"
+
+ target_size = (image_size[0] // self.downsample_ratio, image_size[1] // self.downsample_ratio)
+ spatial_features = F.interpolate(spatial_features, size=target_size, mode='bilinear', align_corners=False)
+
+ if not skip_blocks:
+ for block in self.blocks:
+ spatial_features = block(spatial_features)
+
+ spatial_features_proj = self.spatial_features_proj(spatial_features)
+
+ qf = self.query_features_proj(self.query_features_block(query_features[0]))
+ return [torch.einsum('bchw,bnc->bnhw', spatial_features_proj, qf) + self.bias]
+
+
+def point_sample(input, point_coords, **kwargs):
+ """
+ A wrapper around :function:`torch.nn.functional.grid_sample` to support 3D point_coords tensors.
+ Unlike :function:`torch.nn.functional.grid_sample` it assumes `point_coords` to lie inside
+ [0, 1] x [0, 1] square.
+
+ Args:
+ input (Tensor): A tensor of shape (N, C, H, W) that contains features map on a H x W grid.
+ point_coords (Tensor): A tensor of shape (N, P, 2) or (N, Hgrid, Wgrid, 2) that contains
+ [0, 1] x [0, 1] normalized point coordinates.
+
+ Returns:
+ output (Tensor): A tensor of shape (N, C, P) or (N, C, Hgrid, Wgrid) that contains
+ features for points in `point_coords`. The features are obtained via bilinear
+ interplation from `input` the same way as :function:`torch.nn.functional.grid_sample`.
+ """
+ add_dim = False
+ if point_coords.dim() == 3:
+ add_dim = True
+ point_coords = point_coords.unsqueeze(2)
+ output = F.grid_sample(input, 2.0 * point_coords - 1.0, **kwargs)
+ if add_dim:
+ output = output.squeeze(3)
+ return output
+
+
+def get_uncertain_point_coords_with_randomness(
+ coarse_logits, uncertainty_func, num_points, oversample_ratio=3, importance_sample_ratio=0.75
+):
+ """
+ Sample points in [0, 1] x [0, 1] coordinate space based on their uncertainty. The unceratinties
+ are calculated for each point using 'uncertainty_func' function that takes point's logit
+ prediction as input.
+ See PointRend paper for details.
+
+ Args:
+ coarse_logits (Tensor): A tensor of shape (N, C, Hmask, Wmask) or (N, 1, Hmask, Wmask) for
+ class-specific or class-agnostic prediction.
+ uncertainty_func: A function that takes a Tensor of shape (N, C, P) or (N, 1, P) that
+ contains logit predictions for P points and returns their uncertainties as a Tensor of
+ shape (N, 1, P).
+ num_points (int): The number of points P to sample.
+ oversample_ratio (int): Oversampling parameter.
+ importance_sample_ratio (float): Ratio of points that are sampled via importnace sampling.
+
+ Returns:
+ point_coords (Tensor): A tensor of shape (N, P, 2) that contains the coordinates of P
+ sampled points.
+ """
+ assert oversample_ratio >= 1
+ assert importance_sample_ratio <= 1 and importance_sample_ratio >= 0
+ num_boxes = coarse_logits.shape[0]
+ num_sampled = int(num_points * oversample_ratio)
+ point_coords = torch.rand(num_boxes, num_sampled, 2, device=coarse_logits.device)
+ point_logits = point_sample(coarse_logits, point_coords, align_corners=False)
+ # It is crucial to calculate uncertainty based on the sampled prediction value for the points.
+ # Calculating uncertainties of the coarse predictions first and sampling them for points leads
+ # to incorrect results.
+ # To illustrate this: assume uncertainty_func(logits)=-abs(logits), a sampled point between
+ # two coarse predictions with -1 and 1 logits has 0 logits, and therefore 0 uncertainty value.
+ # However, if we calculate uncertainties for the coarse predictions first,
+ # both will have -1 uncertainty, and the sampled point will get -1 uncertainty.
+ point_uncertainties = uncertainty_func(point_logits)
+ num_uncertain_points = int(importance_sample_ratio * num_points)
+ num_random_points = num_points - num_uncertain_points
+ idx = torch.topk(point_uncertainties[:, 0, :], k=num_uncertain_points, dim=1)[1]
+ shift = num_sampled * torch.arange(num_boxes, dtype=torch.long, device=coarse_logits.device)
+ idx += shift[:, None]
+ point_coords = point_coords.view(-1, 2)[idx.view(-1), :].view(
+ num_boxes, num_uncertain_points, 2
+ )
+ if num_random_points > 0:
+ point_coords = torch.cat(
+ [
+ point_coords,
+ torch.rand(num_boxes, num_random_points, 2, device=coarse_logits.device),
+ ],
+ dim=1,
+ )
+ return point_coords
\ No newline at end of file
diff --git a/rfdetr/models/transformer.py b/rfdetr/models/transformer.py
index 9c2343b..343c6fc 100644
--- a/rfdetr/models/transformer.py
+++ b/rfdetr/models/transformer.py
@@ -528,7 +528,7 @@ def forward_post(self, tgt, memory,
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
- tgt = tgt + self.dropout3(tgt2)
+ tgt = (tgt + self.dropout3(tgt2))
tgt = self.norm3(tgt)
return tgt
diff --git a/rfdetr/util/box_ops.py b/rfdetr/util/box_ops.py
index ae3c267..ecedab4 100644
--- a/rfdetr/util/box_ops.py
+++ b/rfdetr/util/box_ops.py
@@ -15,6 +15,7 @@
Utilities for bounding box manipulation and GIoU.
"""
import torch
+import torch.nn.functional as F
from torchvision.ops.boxes import box_area
@@ -96,3 +97,58 @@ def masks_to_boxes(masks):
y_min = y_mask.masked_fill(~(masks.bool()), 1e8).flatten(1).min(-1)[0]
return torch.stack([x_min, y_min, x_max, y_max], 1)
+
+
+def batch_dice_loss(inputs: torch.Tensor, targets: torch.Tensor):
+ """
+ Compute the DICE loss, similar to generalized IOU for masks
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs
+ (0 for the negative class and 1 for the positive class).
+ """
+ inputs = inputs.sigmoid()
+ inputs = inputs.flatten(1)
+ numerator = 2 * torch.einsum("nc,mc->nm", inputs, targets)
+ denominator = inputs.sum(-1)[:, None] + targets.sum(-1)[None, :]
+ loss = 1 - (numerator + 1) / (denominator + 1)
+ return loss
+
+
+batch_dice_loss_jit = torch.jit.script(
+ batch_dice_loss
+) # type: torch.jit.ScriptModule
+
+
+def batch_sigmoid_ce_loss(inputs: torch.Tensor, targets: torch.Tensor):
+ """
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs
+ (0 for the negative class and 1 for the positive class).
+ Returns:
+ Loss tensor
+ """
+ hw = inputs.shape[1]
+
+ pos = F.binary_cross_entropy_with_logits(
+ inputs, torch.ones_like(inputs), reduction="none"
+ )
+ neg = F.binary_cross_entropy_with_logits(
+ inputs, torch.zeros_like(inputs), reduction="none"
+ )
+
+ loss = torch.einsum("nc,mc->nm", pos, targets) + torch.einsum(
+ "nc,mc->nm", neg, (1 - targets)
+ )
+
+ return loss / hw
+
+
+batch_sigmoid_ce_loss_jit = torch.jit.script(
+ batch_sigmoid_ce_loss
+) # type: torch.jit.ScriptModule
diff --git a/rfdetr/util/early_stopping.py b/rfdetr/util/early_stopping.py
index 30bf888..bfc219b 100644
--- a/rfdetr/util/early_stopping.py
+++ b/rfdetr/util/early_stopping.py
@@ -18,7 +18,7 @@ class EarlyStoppingCallback:
verbose (bool): Whether to print early stopping messages
"""
- def __init__(self, model, patience=5, min_delta=0.001, use_ema=False, verbose=True):
+ def __init__(self, model, patience=5, min_delta=0.001, use_ema=False, verbose=True, segmentation_head=False):
self.patience = patience
self.min_delta = min_delta
self.use_ema = use_ema
@@ -26,6 +26,7 @@ def __init__(self, model, patience=5, min_delta=0.001, use_ema=False, verbose=Tr
self.best_map = 0.0
self.counter = 0
self.model = model
+ self.segmentation_head = segmentation_head
def update(self, log_stats):
"""Update early stopping state based on epoch validation metrics"""
@@ -33,10 +34,16 @@ def update(self, log_stats):
ema_map = None
if 'test_coco_eval_bbox' in log_stats:
- regular_map = log_stats['test_coco_eval_bbox'][0]
+ if not self.segmentation_head:
+ regular_map = log_stats['test_coco_eval_bbox'][0]
+ else:
+ regular_map = log_stats['test_coco_eval_masks'][0]
if 'ema_test_coco_eval_bbox' in log_stats:
- ema_map = log_stats['ema_test_coco_eval_bbox'][0]
+ if not self.segmentation_head:
+ ema_map = log_stats['ema_test_coco_eval_bbox'][0]
+ else:
+ ema_map = log_stats['ema_test_coco_eval_masks'][0]
current_map = None
if regular_map is not None and ema_map is not None:
+### Instance Segmentation
+
+We benchmarked RF-DETR on the Microsoft COCO dataset for segmentation. Our results are below.
+
+
+
## 💻 Install
You can install and use `rfdetr` in a
diff --git a/docs/learn/deploy.md b/docs/learn/deploy.md
index 8f618ca..9d7672d 100644
--- a/docs/learn/deploy.md
+++ b/docs/learn/deploy.md
@@ -6,17 +6,33 @@ Deploying to Roboflow allows you to create multi-step computer vision applicatio
To deploy your model to Roboflow, run:
-```python
-from rfdetr import RFDETRNano
-
-x = RFDETRNano(pretrain_weights="")
-x.deploy_to_roboflow(
- workspace="",
- project_id="",
- version=1,
- api_key=""
-)
-```
+=== "Object Detection"
+
+ ```python
+ from rfdetr import RFDETRNano
+
+ x = RFDETRNano(pretrain_weights="")
+ x.deploy_to_roboflow(
+ workspace="",
+ project_id="",
+ version=1,
+ api_key=""
+ )
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ from rfdetr import RFDETRSegPreview
+
+ x = RFDETRSegPreview(pretrain_weights="")
+ x.deploy_to_roboflow(
+ workspace="",
+ project_id="",
+ version=1,
+ api_key=""
+ )
+ ```
Above, set your Roboflow Workspace ID, the ID of the project to which you want to upload your model, and your Roboflow API key.
@@ -25,31 +41,62 @@ Above, set your Roboflow Workspace ID, the ID of the project to which you want t
You can then run your model with Roboflow Inference:
-```python
-import os
-import supervision as sv
-from inference import get_model
-from PIL import Image
-from io import BytesIO
-import requests
-url = "https://media.roboflow.com/dog.jpeg"
-image = Image.open(BytesIO(requests.get(url).content))
+=== "Object Detection"
-model = get_model("rfdetr-base") # replace with your Roboflow model ID
+ ```python
+ import os
+ import supervision as sv
+ from inference import get_model
+ from PIL import Image
+ from io import BytesIO
+ import requests
-predictions = model.infer(image, confidence=0.5)[0]
+ url = "https://media.roboflow.com/dog.jpeg"
+ image = Image.open(BytesIO(requests.get(url).content))
-detections = sv.Detections.from_inference(predictions)
+ model = get_model("rfdetr-base") # replace with your Roboflow model ID
-labels = [prediction.class_name for prediction in predictions.predictions]
+ predictions = model.infer(image, confidence=0.5)[0]
-annotated_image = image.copy()
-annotated_image = sv.BoxAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections)
-annotated_image = sv.LabelAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections, labels)
+ detections = sv.Detections.from_inference(predictions)
-sv.plot_image(annotated_image)
-```
+ labels = [prediction.class_name for prediction in predictions.predictions]
+
+ annotated_image = image.copy()
+ annotated_image = sv.BoxAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections)
+ annotated_image = sv.LabelAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections, labels)
+
+ sv.plot_image(annotated_image)
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ import os
+ import supervision as sv
+ from inference import get_model
+ from PIL import Image
+ from io import BytesIO
+ import requests
+
+ url = "https://media.roboflow.com/dog.jpeg"
+ image = Image.open(BytesIO(requests.get(url).content))
+
+ model = get_model("rfdetr-seg-preview") # replace with your Roboflow model ID
+
+ predictions = model.infer(image, confidence=0.5)[0]
+
+ detections = sv.Detections.from_inference(predictions)
+
+ labels = [prediction.class_name for prediction in predictions.predictions]
+
+ annotated_image = image.copy()
+ annotated_image = sv.MaskAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections)
+ annotated_image = sv.LabelAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections, labels)
+
+ sv.plot_image(annotated_image)
+ ```
Above, replace `rfdetr-base` with the your Roboflow model ID. You can find this ID from the "Models" list in your Roboflow dashboard:
diff --git a/docs/learn/run/detection.md b/docs/learn/run/detection.md
new file mode 100644
index 0000000..0e32164
--- /dev/null
+++ b/docs/learn/run/detection.md
@@ -0,0 +1,201 @@
+# Run an RF-DETR Object Detection Model
+
+You can run any of the four supported object detection RF-DETR base models (Nano, Small, Medium, Large) with [Inference](https://github.com/roboflow/inference), an open source computer vision inference server. The base models are trained on the [Microsoft COCO dataset](https://universe.roboflow.com/microsoft/coco).
+
+## Run a Model
+
+=== "Run on an Image"
+
+ To run RF-DETR on an image, use the following code:
+
+ ```python
+ import os
+ import supervision as sv
+ from inference import get_model
+ from PIL import Image
+ from io import BytesIO
+ import requests
+
+ url = "https://media.roboflow.com/dog.jpeg"
+ image = Image.open(BytesIO(requests.get(url).content))
+
+ model = get_model("rfdetr-base")
+
+ predictions = model.infer(image, confidence=0.5)[0]
+
+ detections = sv.Detections.from_inference(predictions)
+
+ labels = [prediction.class_name for prediction in predictions.predictions]
+
+ annotated_image = image.copy()
+ annotated_image = sv.BoxAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections)
+ annotated_image = sv.LabelAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections, labels)
+
+ sv.plot_image(annotated_image)
+ ```
+
+ Above, replace the image URL with any image you want to use with the model.
+
+ Here are the results from the code above:
+
+
+ { width=300 }
+ RF-DETR Base predictions
+
+
+
+=== "Run on a Video File"
+
+ To run RF-DETR on a video file, use the following code:
+
+ ```python
+ import supervision as sv
+ from rfdetr import RFDETRBase
+ from rfdetr.util.coco_classes import COCO_CLASSES
+
+ model = RFDETRBase()
+
+ def callback(frame, index):
+ detections = model.predict(frame[:, :, ::-1], threshold=0.5)
+
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_frame = frame.copy()
+ annotated_frame = sv.BoxAnnotator().annotate(annotated_frame, detections)
+ annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
+ return annotated_frame
+
+ sv.process_video(
+ source_path=,
+ target_path=,
+ callback=callback
+ )
+ ```
+
+ Above, set your `SOURCE_VIDEO_PATH` and `TARGET_VIDEO_PATH` to the directories of the video you want to process and where you want to save the results from inference, respectively.
+
+=== "Run on a Webcam Stream"
+
+ To run RF-DETR on a webcam input, use the following code:
+
+ ```python
+ import cv2
+ import supervision as sv
+ from rfdetr import RFDETRBase
+ from rfdetr.util.coco_classes import COCO_CLASSES
+
+ model = RFDETRBase()
+
+ cap = cv2.VideoCapture(0)
+ while True:
+ success, frame = cap.read()
+ if not success:
+ break
+
+ detections = model.predict(frame[:, :, ::-1], threshold=0.5)
+
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_frame = frame.copy()
+ annotated_frame = sv.BoxAnnotator().annotate(annotated_frame, detections)
+ annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
+
+ cv2.imshow("Webcam", annotated_frame)
+
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+=== "Run on an RTSP Stream"
+
+ To run RF-DETR on an RTSP stream, use the following code:
+
+ ```python
+ import cv2
+ import supervision as sv
+ from rfdetr import RFDETRBase
+ from rfdetr.util.coco_classes import COCO_CLASSES
+
+ model = RFDETRBase()
+
+ cap = cv2.VideoCapture()
+ while True:
+ success, frame = cap.read()
+ if not success:
+ break
+
+ detections = model.predict(frame[:, :, ::-1], threshold=0.5)
+
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_frame = frame.copy()
+ annotated_frame = sv.BoxAnnotator().annotate(annotated_frame, detections)
+ annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
+
+ cv2.imshow("RTSP Stream", annotated_frame)
+
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+You can change the RF-DETR model that the code snippet above uses. To do so, update `rfdetr-base` to any of the following values:
+
+- `rfdetr-nano`
+- `rfdetr-small`
+- `rfdetr-medium`
+- `rfdetr-large`
+
+## Batch Inference
+
+You can provide `.predict()` with either a single image or a list of images. When multiple images are supplied, they are processed together in a single forward pass, resulting in a corresponding list of detections.
+
+```python
+import io
+import requests
+import supervision as sv
+from PIL import Image
+from rfdetr import RFDETRBase
+from rfdetr.util.coco_classes import COCO_CLASSES
+
+model = RFDETRBase()
+
+urls = [
+ "https://media.roboflow.com/notebooks/examples/dog-2.jpeg",
+ "https://media.roboflow.com/notebooks/examples/dog-3.jpeg"
+]
+
+images = [Image.open(io.BytesIO(requests.get(url).content)) for url in urls]
+
+detections_list = model.predict(images, threshold=0.5)
+
+for image, detections in zip(images, detections_list):
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_image = image.copy()
+ annotated_image = sv.BoxAnnotator().annotate(annotated_image, detections)
+ annotated_image = sv.LabelAnnotator().annotate(annotated_image, detections, labels)
+
+ sv.plot_image(annotated_image)
+```
\ No newline at end of file
diff --git a/docs/learn/run/segmentation.md b/docs/learn/run/segmentation.md
new file mode 100644
index 0000000..7abef0f
--- /dev/null
+++ b/docs/learn/run/segmentation.md
@@ -0,0 +1,194 @@
+# Run an RF-DETR Instance Segmentation Model
+
+You can run models trained with the RF-DETR-Seg (Preview) architecture with [Inference](https://github.com/roboflow/inference), an open source computer vision inference server. The base models are trained on the [Microsoft COCO dataset](https://universe.roboflow.com/microsoft/coco).
+
+## Run a Model
+
+=== "Run on an Image"
+
+ To run RF-DETR on an image, use the following code:
+
+ ```python
+ import os
+ import supervision as sv
+ from inference import get_model
+ from PIL import Image
+ from io import BytesIO
+ import requests
+
+ url = "https://media.roboflow.com/dog.jpeg"
+ image = Image.open(BytesIO(requests.get(url).content))
+
+ model = get_model("rfdetr-seg-preview")
+
+ predictions = model.infer(image, confidence=0.5)[0]
+
+ detections = sv.Detections.from_inference(predictions)
+
+ labels = [prediction.class_name for prediction in predictions.predictions]
+
+ annotated_image = image.copy()
+ annotated_image = sv.MaskAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections)
+ annotated_image = sv.LabelAnnotator(color=sv.ColorPalette.ROBOFLOW).annotate(annotated_image, detections, labels)
+
+ sv.plot_image(annotated_image)
+ ```
+
+ Above, replace the image URL with any image you want to use with the model.
+
+ Here are the results from the code above:
+
+
+ { width=300 }
+ RF-DETR Base predictions
+
+
+
+=== "Run on a Video File"
+
+ To run RF-DETR on a video file, use the following code:
+
+ ```python
+ import supervision as sv
+ from rfdetr import RFDETRBase
+ from rfdetr.util.coco_classes import COCO_CLASSES
+
+ model = RFDETRBase()
+
+ def callback(frame, index):
+ detections = model.predict(frame[:, :, ::-1], threshold=0.5)
+
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_frame = frame.copy()
+ annotated_frame = sv.MaskAnnotator().annotate(annotated_frame, detections)
+ annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
+ return annotated_frame
+
+ sv.process_video(
+ source_path=,
+ target_path=,
+ callback=callback
+ )
+ ```
+
+ Above, set your `SOURCE_VIDEO_PATH` and `TARGET_VIDEO_PATH` to the directories of the video you want to process and where you want to save the results from inference, respectively.
+
+=== "Run on a Webcam Stream"
+
+ To run RF-DETR on a webcam input, use the following code:
+
+ ```python
+ import cv2
+ import supervision as sv
+ from rfdetr import RFDETRBase
+ from rfdetr.util.coco_classes import COCO_CLASSES
+
+ model = RFDETRBase()
+
+ cap = cv2.VideoCapture(0)
+ while True:
+ success, frame = cap.read()
+ if not success:
+ break
+
+ detections = model.predict(frame[:, :, ::-1], threshold=0.5)
+
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_frame = frame.copy()
+ annotated_frame = sv.MaskAnnotator().annotate(annotated_frame, detections)
+ annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
+
+ cv2.imshow("Webcam", annotated_frame)
+
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+=== "Run on an RTSP Stream"
+
+ To run RF-DETR on an RTSP stream, use the following code:
+
+ ```python
+ import cv2
+ import supervision as sv
+ from rfdetr import RFDETRBase
+ from rfdetr.util.coco_classes import COCO_CLASSES
+
+ model = RFDETRBase()
+
+ cap = cv2.VideoCapture()
+ while True:
+ success, frame = cap.read()
+ if not success:
+ break
+
+ detections = model.predict(frame[:, :, ::-1], threshold=0.5)
+
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_frame = frame.copy()
+ annotated_frame = sv.MaskAnnotator().annotate(annotated_frame, detections)
+ annotated_frame = sv.LabelAnnotator().annotate(annotated_frame, detections, labels)
+
+ cv2.imshow("RTSP Stream", annotated_frame)
+
+ if cv2.waitKey(1) & 0xFF == ord('q'):
+ break
+
+ cap.release()
+ cv2.destroyAllWindows()
+ ```
+
+## Batch Inference
+
+You can provide `.predict()` with either a single image or a list of images using the `rfdetr` package for use in batch inference applications. When multiple images are supplied, they are processed together in a single forward pass, resulting in a corresponding list of detections.
+
+```python
+import io
+import requests
+import supervision as sv
+from PIL import Image
+from rfdetr import RFDETRSegPreview
+from rfdetr.util.coco_classes import COCO_CLASSES
+
+model = RFDETRSegPreview()
+
+urls = [
+ "https://media.roboflow.com/notebooks/examples/dog-2.jpeg",
+ "https://media.roboflow.com/notebooks/examples/dog-3.jpeg"
+]
+
+images = [Image.open(io.BytesIO(requests.get(url).content)) for url in urls]
+
+detections_list = model.predict(images, threshold=0.5)
+
+for image, detections in zip(images, detections_list):
+ labels = [
+ f"{COCO_CLASSES[class_id]} {confidence:.2f}"
+ for class_id, confidence
+ in zip(detections.class_id, detections.confidence)
+ ]
+
+ annotated_image = image.copy()
+ annotated_image = sv.MaskAnnotator().annotate(annotated_image, detections)
+ annotated_image = sv.LabelAnnotator().annotate(annotated_image, detections, labels)
+
+ sv.plot_image(annotated_image)
+```
\ No newline at end of file
diff --git a/docs/learn/train.md b/docs/learn/train/index.md
similarity index 76%
rename from docs/learn/train.md
rename to docs/learn/train/index.md
index 14fcb16..a0efc64 100644
--- a/docs/learn/train.md
+++ b/docs/learn/train/index.md
@@ -1,18 +1,12 @@
# Train an RF-DETR Model
-You can train an RF-DETR model on a custom dataset using the `rfdetr` Python package, or in the cloud using Roboflow.
+You can train RF-DETR object detection and segmentation models on a custom dataset using the `rfdetr` Python package, or in the cloud using Roboflow.
-Training on device is ideal if you want to manage your training pipeline and have a GPU available for training.
-
-Training in the Roboflow Cloud is ideal if you want managed training whose weights you can deploy on your own hardware and with a hosted API.
-
-For this guide, we will train a model using the `rfdetr` Python package.
-
-Once you have trained a model with this guide, see our [deploy an RF-DETR model guide](/learn/deploy/) to learn how to run inference with your model.
+This guide describes how to train both an object detection and segmentation RF-DETR model.
### Dataset structure
-RF-DETR expects the dataset to be in COCO format. Divide your dataset into three subdirectories: `train`, `valid`, and `test`. Each subdirectory should contain its own `_annotations.coco.json` file that holds the annotations for that particular split, along with the corresponding image files. Below is an example of the directory structure:
+RF-DETR expects the dataset to be in COCO format. Divide your dataset into three subdirectories: `train`, `valid`, and `test`. Each sub-directory should contain its own `_annotations.coco.json` file that holds the annotations for that particular split, along with the corresponding image files. Below is an example of the directory structure:
```
dataset/
@@ -35,24 +29,49 @@ dataset/
[Roboflow](https://roboflow.com/annotate) allows you to create object detection datasets from scratch or convert existing datasets from formats like YOLO, and then export them in COCO JSON format for training. You can also explore [Roboflow Universe](https://universe.roboflow.com/) to find pre-labeled datasets for a range of use cases.
-### Fine-tuning
+If you are training a segmentation model, your COCO JSON annotations should have a `segmentation` key with the polygon associated with each annotation.
-You can fine-tune RF-DETR from pre-trained COCO checkpoints. By default, the RF-DETR-B checkpoint will be used. To get started quickly, please refer to our fine-tuning Google Colab [notebook](https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/how-to-finetune-rf-detr-on-detection-dataset.ipynb).
+## Start Training
-```python
-from rfdetr import RFDETRBase
+You can fine-tune RF-DETR from pre-trained COCO checkpoints.
-model = RFDETRBase()
+For object detection, the RF-DETR-B checkpoint is used by default. To get started quickly with training an object detection model, please refer to our fine-tuning Google Colab [notebook](https://colab.research.google.com/github/roboflow-ai/notebooks/blob/main/notebooks/how-to-finetune-rf-detr-on-detection-dataset.ipynb).
-model.train(
- dataset_dir=,
- epochs=10,
- batch_size=4,
- grad_accum_steps=4,
- lr=1e-4,
- output_dir=
-)
-```
+For image segmentation, the RF-DETR-Seg (Preview) checkpoint is used by default.
+
+=== "Object Detection"
+
+ ```python
+ from rfdetr import RFDETRBase
+
+ model = RFDETRBase()
+
+ model.train(
+ dataset_dir=,
+ epochs=100,
+ batch_size=4,
+ grad_accum_steps=4,
+ lr=1e-4,
+ output_dir=
+ )
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ from rfdetr import RFDETRSegPreview
+
+ model = RFDETRSegPreview()
+
+ model.train(
+ dataset_dir=,
+ epochs=100,
+ batch_size=4,
+ grad_accum_steps=4,
+ lr=1e-4,
+ output_dir=
+ )
+ ```
Different GPUs have different VRAM capacities, so adjust batch_size and grad_accum_steps to maintain a total batch size of 16. For example, on a powerful GPU like the A100, use `batch_size=16` and `grad_accum_steps=1`; on smaller GPUs like the T4, use `batch_size=4` and `grad_accum_steps=4`. This gradient accumulation strategy helps train effectively even with limited memory.
@@ -192,41 +211,83 @@ During training, multiple model checkpoints are saved to the output directory:
You can resume training from a previously saved checkpoint by passing the path to the `checkpoint.pth` file using the `resume` argument. This is useful when training is interrupted or you want to continue fine-tuning an already partially trained model. The training loop will automatically load the weights and optimizer state from the provided checkpoint file.
-```python
-from rfdetr import RFDETRBase
+=== "Object Detection"
-model = RFDETRBase()
+ ```python
+ from rfdetr import RFDETRBase
+
+ model = RFDETRBase()
+
+ model.train(
+ dataset_dir=,
+ epochs=100,
+ batch_size=4,
+ grad_accum_steps=4,
+ lr=1e-4,
+ output_dir=,
+ resume=
+ )
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ from rfdetr import RFDETRSegPreview
+
+ model = RFDETRSegPreview()
+
+ model.train(
+ dataset_dir=,
+ epochs=100,
+ batch_size=4,
+ grad_accum_steps=4,
+ lr=1e-4,
+ output_dir=,
+ resume=
+ )
+ ```
-model.train(
- dataset_dir=,
- epochs=10,
- batch_size=4,
- grad_accum_steps=4,
- lr=1e-4,
- output_dir=,
- resume=
-)
-```
### Early stopping
Early stopping monitors validation mAP and halts training if improvements remain below a threshold for a set number of epochs. This can reduce wasted computation once the model converges. Additional parameters—such as `early_stopping_patience`, `early_stopping_min_delta`, and `early_stopping_use_ema`—let you fine-tune the stopping behavior.
-```python
-from rfdetr import RFDETRBase
+=== "Object Detection"
-model = RFDETRBase()
+ ```python
+ from rfdetr import RFDETRBase
+
+ model = RFDETRBase()
+
+ model.train(
+ dataset_dir=,
+ epochs=100,
+ batch_size=4
+ grad_accum_steps=4,
+ lr=1e-4,
+ output_dir=,
+ early_stopping=True
+ )
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ from rfdetr import RFDETRSegPreview
+
+ model = RFDETRSegPreview()
+
+ model.train(
+ dataset_dir=,
+ epochs=100,
+ batch_size=4
+ grad_accum_steps=4,
+ lr=1e-4,
+ output_dir=,
+ early_stopping=True
+ )
+ ```
-model.train(
- dataset_dir=,
- epochs=10,
- batch_size=4
- grad_accum_steps=4,
- lr=1e-4,
- output_dir=,
- early_stopping=True
-)
-```
### Multi-GPU training
@@ -262,7 +323,7 @@ Replace `8` in the `--nproc_per_node argument` with the number of GPUs you want
model.train(
dataset_dir=,
- epochs=10,
+ epochs=100,
batch_size=4,
grad_accum_steps=4,
lr=1e-4,
@@ -320,7 +381,7 @@ Replace `8` in the `--nproc_per_node argument` with the number of GPUs you want
model.train(
dataset_dir=,
- epochs=10,
+ epochs=100,
batch_size=4,
grad_accum_steps=4,
lr=1e-4,
@@ -337,13 +398,25 @@ Replace `8` in the `--nproc_per_node argument` with the number of GPUs you want
### Load and run fine-tuned model
-```python
-from rfdetr import RFDETRBase
+=== "Object Detection"
-model = RFDETRBase(pretrain_weights=)
+ ```python
+ from rfdetr import RFDETRBase
-detections = model.predict()
-```
+ model = RFDETRBase(pretrain_weights=)
+
+ detections = model.predict()
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ from rfdetr import RFDETRSegPreview
+
+ model = RFDETRSegPreview(pretrain_weights=)
+
+ detections = model.predict()
+ ```
## ONNX export
@@ -357,12 +430,24 @@ pip install rfdetr[onnxexport]
Then, run:
-```python
-from rfdetr import RFDETRBase
+=== "Object Detection"
-model = RFDETRBase(pretrain_weights=)
+ ```python
+ from rfdetr import RFDETRBase
-model.export()
-```
+ model = RFDETRBase(pretrain_weights=)
+
+ model.export()
+ ```
+
+=== "Image Segmentation"
+
+ ```python
+ from rfdetr import RFDETRSegPreview
+
+ model = RFDETRSegPreview(pretrain_weights=)
+
+ model.export()
+ ```
This command saves the ONNX model to the `output` directory.
\ No newline at end of file
diff --git a/docs/reference/seg_preview.md b/docs/reference/seg_preview.md
new file mode 100644
index 0000000..7cc335c
--- /dev/null
+++ b/docs/reference/seg_preview.md
@@ -0,0 +1,3 @@
+:::rfdetr.detr.RFDETRSegPreview
+ options:
+ inherited_members: true
diff --git a/mkdocs.yaml b/mkdocs.yaml
index e02ccff..29ef895 100644
--- a/mkdocs.yaml
+++ b/mkdocs.yaml
@@ -23,18 +23,22 @@ extra:
nav:
- Home: index.md
- Learn:
- - Run a Pre-Trained Model: learn/pretrained.md
- - Train an RF-DETR Model: learn/train.md
- - Deploy a Trained Model: learn/deploy.md
- - Benchmarks: learn/benchmarks.md
+ - Run a Model:
+ - Object Detection: learn/run/detection.md
+ - Segmentation: learn/run/segmentation.md
+ - Train a Model: learn/train/index.md
+ - Deploy a Trained Model: learn/deploy.md
+ - Benchmarks: learn/benchmarks.md
- Reference:
- RF-DETR: reference/rfdetr.md
- - Models:
+ - Object Detection Models:
- RF-DETR Nano: reference/nano.md
- RF-DETR Small: reference/small.md
- - RF-DETR Base: reference/base.md
+ - RF-DETR Base (Deprecated): reference/base.md
- RF-DETR Medium: reference/medium.md
- RF-DETR Large: reference/large.md
+ - Image Segmentation Models:
+ - RF-DETR Seg Preview: reference/seg_preview.md
- Changelog: https://github.com/roboflow/rf-detr/releases
theme:
diff --git a/pyproject.toml b/pyproject.toml
index f074930..090a8a3 100644
--- a/pyproject.toml
+++ b/pyproject.toml
@@ -4,7 +4,7 @@ build-backend = "setuptools.build_meta"
[project]
name = "rfdetr"
-version = "1.2.1"
+version = "1.3.0"
description = "RF-DETR"
readme = "README.md"
authors = [
diff --git a/rfdetr/__init__.py b/rfdetr/__init__.py
index ef87e73..e66c3e4 100644
--- a/rfdetr/__init__.py
+++ b/rfdetr/__init__.py
@@ -9,4 +9,4 @@
if os.environ.get("PYTORCH_ENABLE_MPS_FALLBACK") is None:
os.environ["PYTORCH_ENABLE_MPS_FALLBACK"] = "1"
-from rfdetr.detr import RFDETRBase, RFDETRLarge, RFDETRNano, RFDETRSmall, RFDETRMedium
+from rfdetr.detr import RFDETRBase, RFDETRLarge, RFDETRNano, RFDETRSmall, RFDETRMedium, RFDETRSegPreview
diff --git a/rfdetr/config.py b/rfdetr/config.py
index 12f7fd7..8999cdf 100644
--- a/rfdetr/config.py
+++ b/rfdetr/config.py
@@ -33,6 +33,11 @@ class ModelConfig(BaseModel):
group_detr: int = 13
gradient_checkpointing: bool = False
positional_encoding_size: int
+ ia_bce_loss: bool = True
+ cls_loss_coef: float = 1.0
+ segmentation_head: bool = False
+ mask_downsample_ratio: int = 4
+
class RFDETRBaseConfig(ModelConfig):
"""
@@ -102,6 +107,19 @@ class RFDETRMediumConfig(RFDETRBaseConfig):
positional_encoding_size: int = 36
pretrain_weights: Optional[str] = "rf-detr-medium.pth"
+class RFDETRSegPreviewConfig(RFDETRBaseConfig):
+ segmentation_head: bool = True
+ out_feature_indexes: List[int] = [3, 6, 9, 12]
+ num_windows: int = 2
+ dec_layers: int = 4
+ patch_size: int = 12
+ resolution: int = 432
+ positional_encoding_size: int = 36
+ num_queries: int = 200
+ num_select: int = 200
+ pretrain_weights: Optional[str] = "rf-detr-seg-preview.pt"
+ num_classes: int = 90
+
class TrainConfig(BaseModel):
lr: float = 1e-4
lr_encoder: float = 1.5e-4
@@ -112,7 +130,7 @@ class TrainConfig(BaseModel):
ema_tau: int = 100
lr_drop: int = 100
checkpoint_interval: int = 10
- warmup_epochs: int = 0
+ warmup_epochs: float = 0.0
lr_vit_layer_decay: float = 0.8
lr_component_decay: float = 0.7
drop_path: float = 0.0
@@ -140,3 +158,12 @@ class TrainConfig(BaseModel):
run: Optional[str] = None
class_names: List[str] = None
run_test: bool = True
+ segmentation_head: bool = False
+
+
+class SegmentationTrainConfig(TrainConfig):
+ mask_point_sample_ratio: int = 16
+ mask_ce_loss_coef: float = 5.0
+ mask_dice_loss_coef: float = 5.0
+ cls_loss_coef: float = 5.0
+ segmentation_head: bool = True
diff --git a/rfdetr/datasets/coco.py b/rfdetr/datasets/coco.py
index ef47a4b..4e7a51a 100644
--- a/rfdetr/datasets/coco.py
+++ b/rfdetr/datasets/coco.py
@@ -23,6 +23,7 @@
import torch
import torch.utils.data
import torchvision
+import pycocotools.mask as coco_mask
import rfdetr.datasets.transforms as T
@@ -37,11 +38,37 @@ def compute_multi_scale_scales(resolution, expanded_scales=False, patch_size=16,
return proposed_scales
+def convert_coco_poly_to_mask(segmentations, height, width):
+ """Convert polygon segmentation to a binary mask tensor of shape [N, H, W].
+ Requires pycocotools.
+ """
+ masks = []
+ for polygons in segmentations:
+ if polygons is None or len(polygons) == 0:
+ # empty segmentation for this instance
+ masks.append(torch.zeros((height, width), dtype=torch.uint8))
+ continue
+ try:
+ rles = coco_mask.frPyObjects(polygons, height, width)
+ except:
+ rles = polygons
+ mask = coco_mask.decode(rles)
+ if mask.ndim < 3:
+ mask = mask[..., None]
+ mask = torch.as_tensor(mask, dtype=torch.uint8)
+ mask = mask.any(dim=2)
+ masks.append(mask)
+ if len(masks) == 0:
+ return torch.zeros((0, height, width), dtype=torch.uint8)
+ return torch.stack(masks, dim=0)
+
+
class CocoDetection(torchvision.datasets.CocoDetection):
- def __init__(self, img_folder, ann_file, transforms):
+ def __init__(self, img_folder, ann_file, transforms, include_masks=False):
super(CocoDetection, self).__init__(img_folder, ann_file)
self._transforms = transforms
- self.prepare = ConvertCoco()
+ self.include_masks = include_masks
+ self.prepare = ConvertCoco(include_masks=include_masks)
def __getitem__(self, idx):
img, target = super(CocoDetection, self).__getitem__(idx)
@@ -55,6 +82,9 @@ def __getitem__(self, idx):
class ConvertCoco(object):
+ def __init__(self, include_masks=False):
+ self.include_masks = include_masks
+
def __call__(self, image, target):
w, h = image.size
@@ -90,6 +120,20 @@ def __call__(self, image, target):
target["area"] = area[keep]
target["iscrowd"] = iscrowd[keep]
+ # add segmentation masks if requested, otherwise ensure consistent key when include_masks=True
+ if self.include_masks:
+ if len(anno) > 0 and 'segmentation' in anno[0]:
+ segmentations = [obj.get("segmentation", []) for obj in anno]
+ masks = convert_coco_poly_to_mask(segmentations, h, w)
+ if masks.numel() > 0:
+ target["masks"] = masks[keep]
+ else:
+ target["masks"] = torch.zeros((0, h, w), dtype=torch.uint8)
+ else:
+ target["masks"] = torch.zeros((0, h, w), dtype=torch.uint8)
+
+ target["masks"] = target["masks"].bool()
+
target["orig_size"] = torch.as_tensor([int(h), int(w)])
target["size"] = torch.as_tensor([int(h), int(w)])
@@ -255,6 +299,11 @@ def build_roboflow(image_set, args, resolution):
square_resize_div_64 = args.square_resize_div_64
except:
square_resize_div_64 = False
+
+ try:
+ include_masks = args.segmentation_head
+ except:
+ include_masks = False
if square_resize_div_64:
@@ -266,7 +315,7 @@ def build_roboflow(image_set, args, resolution):
skip_random_resize=not args.do_random_resize_via_padding,
patch_size=args.patch_size,
num_windows=args.num_windows
- ))
+ ), include_masks=include_masks)
else:
dataset = CocoDetection(img_folder, ann_file, transforms=make_coco_transforms(
image_set,
@@ -276,5 +325,5 @@ def build_roboflow(image_set, args, resolution):
skip_random_resize=not args.do_random_resize_via_padding,
patch_size=args.patch_size,
num_windows=args.num_windows
- ))
+ ), include_masks=include_masks)
return dataset
diff --git a/rfdetr/datasets/coco_eval.py b/rfdetr/datasets/coco_eval.py
index 5dd00a5..2c036c0 100644
--- a/rfdetr/datasets/coco_eval.py
+++ b/rfdetr/datasets/coco_eval.py
@@ -130,7 +130,7 @@ def prepare_for_coco_segmentation(self, predictions):
labels = prediction["labels"].tolist()
rles = [
- mask_util.encode(np.array(mask[0, :, :, np.newaxis], dtype=np.uint8, order="F"))[0]
+ mask_util.encode(np.array(mask.cpu()[0, :, :, np.newaxis], dtype=np.uint8, order="F"))[0]
for mask in masks
]
for rle in rles:
diff --git a/rfdetr/datasets/transforms.py b/rfdetr/datasets/transforms.py
index b5da93c..06d3161 100644
--- a/rfdetr/datasets/transforms.py
+++ b/rfdetr/datasets/transforms.py
@@ -253,6 +253,10 @@ def __call__(self, img, target=None):
target["size"] = torch.tensor([h, w])
+ if "masks" in target:
+ target['masks'] = interpolate(
+ target['masks'][:, None].float(), (h, w), mode="nearest")[:, 0] > 0.5
+
return rescaled_img, target
diff --git a/rfdetr/deploy/export.py b/rfdetr/deploy/export.py
index 9a50188..29d6c63 100644
--- a/rfdetr/deploy/export.py
+++ b/rfdetr/deploy/export.py
@@ -258,6 +258,12 @@ def main(args):
if args.backbone_only:
features = model(input_tensors)
print(f"PyTorch inference output shape: {features.shape}")
+ elif args.segmentation_head:
+ outputs = model(input_tensors)
+ dets = outputs['pred_boxes']
+ labels = outputs['pred_logits']
+ masks = outputs['pred_masks']
+ print(f"PyTorch inference output shapes - Boxes: {dets.shape}, Labels: {labels.shape}, Masks: {masks.shape}")
else:
outputs = model(input_tensors)
dets = outputs['pred_boxes']
@@ -273,4 +279,4 @@ def main(args):
output_file = onnx_simplify(output_file, input_names, input_tensors, args)
if args.tensorrt:
- output_file = trtexec(output_file, args)
+ output_file = trtexec(output_file, args)
\ No newline at end of file
diff --git a/rfdetr/detr.py b/rfdetr/detr.py
index 021bf69..1cb03a3 100644
--- a/rfdetr/detr.py
+++ b/rfdetr/detr.py
@@ -29,7 +29,9 @@
RFDETRNanoConfig,
RFDETRSmallConfig,
RFDETRMediumConfig,
+ RFDETRSegPreviewConfig,
TrainConfig,
+ SegmentationTrainConfig,
ModelConfig
)
from rfdetr.main import Model, download_pretrain_weights
@@ -122,19 +124,21 @@ def export(self, **kwargs):
self.model.export(**kwargs)
def train_from_config(self, config: TrainConfig, **kwargs):
- with open(
- os.path.join(config.dataset_dir, "train", "_annotations.coco.json"), "r"
- ) as f:
- anns = json.load(f)
- num_classes = len(anns["categories"])
- class_names = [c["name"] for c in anns["categories"] if c["supercategory"] != "none"]
- self.model.class_names = class_names
+ if config.dataset_file == "roboflow":
+ with open(
+ os.path.join(config.dataset_dir, "train", "_annotations.coco.json"), "r"
+ ) as f:
+ anns = json.load(f)
+ num_classes = len(anns["categories"])
+ class_names = [c["name"] for c in anns["categories"] if c["supercategory"] != "none"]
+ self.model.class_names = class_names
+ elif config.dataset_file == "coco":
+ class_names = COCO_CLASSES
+ num_classes = 90
+ else:
+ raise ValueError(f"Invalid dataset file: {config.dataset_file}")
if self.model_config.num_classes != num_classes:
- logger.warning(
- f"num_classes mismatch: model has {self.model_config.num_classes} classes, but your dataset has {num_classes} classes\n"
- f"reinitializing your detection head with {num_classes} classes."
- )
self.model.reinitialize_detection_head(num_classes)
train_config = config.dict()
@@ -179,7 +183,8 @@ def train_from_config(self, config: TrainConfig, **kwargs):
model=self.model,
patience=config.early_stopping_patience,
min_delta=config.early_stopping_min_delta,
- use_ema=config.early_stopping_use_ema
+ use_ema=config.early_stopping_use_ema,
+ segmentation_head=config.segmentation_head
)
self.callbacks["on_fit_epoch_end"].append(early_stopping_callback.update)
@@ -313,10 +318,11 @@ def predict(
if isinstance(predictions, tuple):
predictions = {
"pred_logits": predictions[1],
- "pred_boxes": predictions[0]
+ "pred_boxes": predictions[0],
+ "pred_masks": predictions[2]
}
target_sizes = torch.tensor(orig_sizes, device=self.model.device)
- results = self.model.postprocessors["bbox"](predictions, target_sizes=target_sizes)
+ results = self.model.postprocess(predictions, target_sizes=target_sizes)
detections_list = []
for result in results:
@@ -329,11 +335,23 @@ def predict(
labels = labels[keep]
boxes = boxes[keep]
- detections = sv.Detections(
- xyxy=boxes.float().cpu().numpy(),
- confidence=scores.float().cpu().numpy(),
- class_id=labels.cpu().numpy(),
- )
+ if "masks" in result:
+ masks = result["masks"]
+ masks = masks[keep]
+
+ detections = sv.Detections(
+ xyxy=boxes.float().cpu().numpy(),
+ confidence=scores.float().cpu().numpy(),
+ class_id=labels.cpu().numpy(),
+ mask=masks.squeeze(1).cpu().numpy(),
+ )
+ else:
+ detections = sv.Detections(
+ xyxy=boxes.float().cpu().numpy(),
+ confidence=scores.float().cpu().numpy(),
+ class_id=labels.cpu().numpy(),
+ )
+
detections_list.append(detections)
return detections_list if len(detections_list) > 1 else detections_list[0]
@@ -447,4 +465,12 @@ def get_model_config(self, **kwargs):
return RFDETRMediumConfig(**kwargs)
def get_train_config(self, **kwargs):
- return TrainConfig(**kwargs)
\ No newline at end of file
+ return TrainConfig(**kwargs)
+
+class RFDETRSegPreview(RFDETR):
+ size = "rfdetr-seg-preview"
+ def get_model_config(self, **kwargs):
+ return RFDETRSegPreviewConfig(**kwargs)
+
+ def get_train_config(self, **kwargs):
+ return SegmentationTrainConfig(**kwargs)
diff --git a/rfdetr/engine.py b/rfdetr/engine.py
index 31e68ca..cb589df 100644
--- a/rfdetr/engine.py
+++ b/rfdetr/engine.py
@@ -249,7 +249,7 @@ def coco_extended_metrics(coco_eval):
"recall" : macro_recall
}
-def evaluate(model, criterion, postprocessors, data_loader, base_ds, device, args=None):
+def evaluate(model, criterion, postprocess, data_loader, base_ds, device, args=None):
model.eval()
if args.fp16_eval:
model.half()
@@ -261,7 +261,7 @@ def evaluate(model, criterion, postprocessors, data_loader, base_ds, device, arg
)
header = "Test:"
- iou_types = tuple(k for k in ("segm", "bbox") if k in postprocessors.keys())
+ iou_types = ("bbox",) if not args.segmentation_head else ("bbox", "segm")
coco_evaluator = CocoEvaluator(base_ds, iou_types)
for samples, targets in metric_logger.log_every(data_loader, 10, header):
@@ -310,10 +310,10 @@ def evaluate(model, criterion, postprocessors, data_loader, base_ds, device, arg
metric_logger.update(class_error=loss_dict_reduced["class_error"])
orig_target_sizes = torch.stack([t["orig_size"] for t in targets], dim=0)
- results = postprocessors["bbox"](outputs, orig_target_sizes)
+ results_all = postprocess(outputs, orig_target_sizes)
res = {
target["image_id"].item(): output
- for target, output in zip(targets, results)
+ for target, output in zip(targets, results_all)
}
if coco_evaluator is not None:
coco_evaluator.update(res)
@@ -332,9 +332,10 @@ def evaluate(model, criterion, postprocessors, data_loader, base_ds, device, arg
if coco_evaluator is not None:
results_json = coco_extended_metrics(coco_evaluator.coco_eval["bbox"])
stats["results_json"] = results_json
- if "bbox" in postprocessors.keys():
+ if "bbox" in iou_types:
stats["coco_eval_bbox"] = coco_evaluator.coco_eval["bbox"].stats.tolist()
- if "segm" in postprocessors.keys():
+ if "segm" in iou_types:
+ results_json = coco_extended_metrics(coco_evaluator.coco_eval["segm"])
stats["coco_eval_masks"] = coco_evaluator.coco_eval["segm"].stats.tolist()
return stats, coco_evaluator
\ No newline at end of file
diff --git a/rfdetr/main.py b/rfdetr/main.py
index 14fe89c..f52a238 100644
--- a/rfdetr/main.py
+++ b/rfdetr/main.py
@@ -39,7 +39,7 @@
import rfdetr.util.misc as utils
from rfdetr.datasets import build_dataset, get_coco_api_from_dataset
from rfdetr.engine import evaluate, train_one_epoch
-from rfdetr.models import build_model, build_criterion_and_postprocessors
+from rfdetr.models import build_model, build_criterion_and_postprocessors, PostProcess
from rfdetr.util.benchmark import benchmark
from rfdetr.util.drop_scheduler import drop_scheduler
from rfdetr.util.files import download_file
@@ -54,12 +54,14 @@
HOSTED_MODELS = {
"rf-detr-base.pth": "https://storage.googleapis.com/rfdetr/rf-detr-base-coco.pth",
+ "rf-detr-base-o365.pth": "https://storage.googleapis.com/rfdetr/top-secret-1234/lwdetr_dinov2_small_o365_checkpoint.pth",
# below is a less converged model that may be better for finetuning but worse for inference
"rf-detr-base-2.pth": "https://storage.googleapis.com/rfdetr/rf-detr-base-2.pth",
"rf-detr-large.pth": "https://storage.googleapis.com/rfdetr/rf-detr-large.pth",
"rf-detr-nano.pth": "https://storage.googleapis.com/rfdetr/nano_coco/checkpoint_best_regular.pth",
"rf-detr-small.pth": "https://storage.googleapis.com/rfdetr/small_coco/checkpoint_best_regular.pth",
"rf-detr-medium.pth": "https://storage.googleapis.com/rfdetr/medium_coco/checkpoint_best_regular.pth",
+ "rf-detr-seg-preview.pt": "https://storage.googleapis.com/rfdetr/rf-detr-seg-preview.pt",
}
def download_pretrain_weights(pretrain_weights: str, redownload=False):
@@ -98,10 +100,6 @@ def __init__(self, **kwargs):
checkpoint_num_classes = checkpoint['model']['class_embed.bias'].shape[0]
if checkpoint_num_classes != args.num_classes + 1:
- logger.warning(
- f"num_classes mismatch: pretrain weights has {checkpoint_num_classes - 1} classes, but your model has {args.num_classes} classes\n"
- f"reinitializing detection head with {checkpoint_num_classes - 1} classes"
- )
self.reinitialize_detection_head(checkpoint_num_classes)
# add support to exclude_keys
# e.g., when load object365 pretrain, do not load `class_embed.[weight, bias]`
@@ -110,7 +108,7 @@ def __init__(self, **kwargs):
for exclude_key in args.pretrain_exclude_keys:
checkpoint['model'].pop(exclude_key)
if args.pretrain_keys_modify_to_load is not None:
- from util.obj365_to_coco_model import get_coco_pretrain_from_obj365
+ from rfdetr.util.obj365_to_coco_model import get_coco_pretrain_from_obj365
assert isinstance(args.pretrain_keys_modify_to_load, list)
for modify_key_to_load in args.pretrain_keys_modify_to_load:
try:
@@ -145,7 +143,7 @@ def __init__(self, **kwargs):
)
self.model.backbone[0].encoder = get_peft_model(self.model.backbone[0].encoder, lora_config)
self.model = self.model.to(self.device)
- self.criterion, self.postprocessors = build_criterion_and_postprocessors(args)
+ self.postprocess = PostProcess(num_select=args.num_select)
self.stop_early = False
def reinitialize_detection_head(self, num_classes):
@@ -179,7 +177,7 @@ def train(self, callbacks: DefaultDict[str, List[Callable]], **kwargs):
np.random.seed(seed)
random.seed(seed)
- criterion, postprocessors = build_criterion_and_postprocessors(args)
+ criterion, postprocess = build_criterion_and_postprocessors(args)
model = self.model
model.to(device)
@@ -202,7 +200,7 @@ def train(self, callbacks: DefaultDict[str, List[Callable]], **kwargs):
dataset_train = build_dataset(image_set='train', args=args, resolution=args.resolution)
dataset_val = build_dataset(image_set='val', args=args, resolution=args.resolution)
- dataset_test = build_dataset(image_set='test', args=args, resolution=args.resolution)
+ dataset_test = build_dataset(image_set='test' if args.dataset_file == "roboflow" else "val", args=args, resolution=args.resolution)
# for cosine annealing, calculate total training steps and warmup steps
total_batch_size_for_lr = args.batch_size * utils.get_world_size() * args.grad_accum_steps
@@ -303,9 +301,12 @@ def lr_lambda(current_step: int):
if args.eval:
test_stats, coco_evaluator = evaluate(
- model, criterion, postprocessors, data_loader_val, base_ds, device, args)
+ model, criterion, postprocess, data_loader_val, base_ds, device, args)
if args.output_dir:
- utils.save_on_master(coco_evaluator.coco_eval["bbox"].eval, output_dir / "eval.pth")
+ if not args.segmentation_head:
+ utils.save_on_master(coco_evaluator.coco_eval["bbox"].eval, output_dir / "eval.pth")
+ else:
+ utils.save_on_master(coco_evaluator.coco_eval["segm"].eval, output_dir / "eval.pth")
return
# for drop
@@ -323,7 +324,6 @@ def lr_lambda(current_step: int):
args.drop_path, args.epochs, num_training_steps_per_epoch,
args.cutoff_epoch, args.drop_mode, args.drop_schedule)
print("Min DP = %.7f, Max DP = %.7f" % (min(schedules['dp']), max(schedules['dp'])))
-
print("Start training")
start_time = time.time()
best_map_holder = BestMetricHolder(use_ema=args.use_ema)
@@ -370,13 +370,20 @@ def lr_lambda(current_step: int):
with torch.inference_mode():
test_stats, coco_evaluator = evaluate(
- model, criterion, postprocessors, data_loader_val, base_ds, device, args=args
+ model, criterion, postprocess, data_loader_val, base_ds, device, args=args
)
- map_regular = test_stats["coco_eval_bbox"][0]
+ if not args.segmentation_head:
+ map_regular = test_stats["coco_eval_bbox"][0]
+ else:
+ map_regular = test_stats["coco_eval_masks"][0]
_isbest = best_map_holder.update(map_regular, epoch, is_ema=False)
if _isbest:
best_map_5095 = max(best_map_5095, map_regular)
- best_map_50 = max(best_map_50, test_stats["coco_eval_bbox"][1])
+ if not args.segmentation_head:
+ map50 = test_stats["coco_eval_bbox"][1]
+ else:
+ map50 = test_stats["coco_eval_masks"][1]
+ best_map_50 = max(best_map_50, map50)
checkpoint_path = output_dir / 'checkpoint_best_regular.pth'
if not args.dont_save_weights:
utils.save_on_master({
@@ -392,14 +399,21 @@ def lr_lambda(current_step: int):
'n_parameters': n_parameters}
if args.use_ema:
ema_test_stats, _ = evaluate(
- self.ema_m.module, criterion, postprocessors, data_loader_val, base_ds, device, args=args
+ self.ema_m.module, criterion, postprocess, data_loader_val, base_ds, device, args=args
)
log_stats.update({f'ema_test_{k}': v for k,v in ema_test_stats.items()})
- map_ema = ema_test_stats["coco_eval_bbox"][0]
+ if not args.segmentation_head:
+ map_ema = ema_test_stats["coco_eval_bbox"][0]
+ else:
+ map_ema = ema_test_stats["coco_eval_masks"][0]
best_map_ema_5095 = max(best_map_ema_5095, map_ema)
_isbest = best_map_holder.update(map_ema, epoch, is_ema=True)
if _isbest:
- best_map_ema_50 = max(best_map_ema_50, ema_test_stats["coco_eval_bbox"][1])
+ if not args.segmentation_head:
+ map_ema_50 = ema_test_stats["coco_eval_bbox"][1]
+ else:
+ map_ema_50 = ema_test_stats["coco_eval_masks"][1]
+ best_map_ema_50 = max(best_map_ema_50, map_ema_50)
checkpoint_path = output_dir / 'checkpoint_best_ema.pth'
if not args.dont_save_weights:
utils.save_on_master({
@@ -437,8 +451,13 @@ def lr_lambda(current_step: int):
if epoch % 50 == 0:
filenames.append(f'{epoch:03}.pth')
for name in filenames:
- torch.save(coco_evaluator.coco_eval["bbox"].eval,
+ if not args.segmentation_head:
+ torch.save(coco_evaluator.coco_eval["bbox"].eval,
+ output_dir / "eval" / name)
+ else:
+ torch.save(coco_evaluator.coco_eval["segm"].eval,
output_dir / "eval" / name)
+
for callback in callbacks["on_fit_epoch_end"]:
callback(log_stats)
@@ -478,14 +497,13 @@ def lr_lambda(current_step: int):
self.model = self.ema_m.module
self.model.eval()
-
if args.run_test:
best_state_dict = torch.load(output_dir / 'checkpoint_best_total.pth', map_location='cpu', weights_only=False)['model']
model.load_state_dict(best_state_dict)
model.eval()
test_stats, _ = evaluate(
- model, criterion, postprocessors, data_loader_test, base_ds_test, device, args=args
+ model, criterion, postprocess, data_loader_test, base_ds_test, device, args=args
)
print(f"Test results: {test_stats}")
with open(output_dir / "results.json", "r") as f:
@@ -529,6 +547,12 @@ def export(self, output_dir="output", infer_dir=None, simplify=False, backbone_
if backbone_only:
features = model(input_tensors)
print(f"PyTorch inference output shape: {features.shape}")
+ elif self.args.segmentation_head:
+ outputs = model(input_tensors)
+ dets = outputs['pred_boxes']
+ labels = outputs['pred_logits']
+ masks = outputs['pred_masks']
+ print(f"PyTorch inference output shapes - Boxes: {dets.shape}, Labels: {labels.shape}, Masks: {masks.shape}")
else:
outputs = model(input_tensors)
dets = outputs['pred_boxes']
diff --git a/rfdetr/models/__init__.py b/rfdetr/models/__init__.py
index ba018eb..cfa4aa1 100644
--- a/rfdetr/models/__init__.py
+++ b/rfdetr/models/__init__.py
@@ -13,4 +13,4 @@
# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.
# ------------------------------------------------------------------------
-from .lwdetr import build_model, build_criterion_and_postprocessors
+from .lwdetr import build_model, build_criterion_and_postprocessors, PostProcess
diff --git a/rfdetr/models/backbone/dinov2_with_windowed_attn.py b/rfdetr/models/backbone/dinov2_with_windowed_attn.py
index b315c46..b3827a0 100644
--- a/rfdetr/models/backbone/dinov2_with_windowed_attn.py
+++ b/rfdetr/models/backbone/dinov2_with_windowed_attn.py
@@ -312,8 +312,8 @@ def forward(self, pixel_values: torch.Tensor, bool_masked_pos: Optional[torch.Te
num_w_patches_per_window = num_w_patches // self.config.num_windows
num_h_patches_per_window = num_h_patches // self.config.num_windows
num_windows = self.config.num_windows
- windowed_pixel_tokens = pixel_tokens_with_pos_embed.view(batch_size, num_windows, num_h_patches_per_window, num_windows, num_h_patches_per_window, -1)
- windowed_pixel_tokens = windowed_pixel_tokens.permute(0, 1, 3, 2, 4, 5)
+ windowed_pixel_tokens = pixel_tokens_with_pos_embed.reshape(batch_size * num_windows, num_h_patches_per_window, num_windows, num_h_patches_per_window, -1)
+ windowed_pixel_tokens = windowed_pixel_tokens.permute(0, 2, 1, 3, 4)
windowed_pixel_tokens = windowed_pixel_tokens.reshape(batch_size * num_windows ** 2, num_h_patches_per_window * num_w_patches_per_window, -1)
windowed_cls_token_with_pos_embed = cls_token_with_pos_embed.repeat(num_windows ** 2, 1, 1)
embeddings = torch.cat((windowed_cls_token_with_pos_embed, windowed_pixel_tokens), dim=1)
@@ -1100,8 +1100,8 @@ def forward(
num_h_patches_per_window = num_h_patches // self.config.num_windows
num_w_patches_per_window = num_w_patches // self.config.num_windows
hidden_state = hidden_state.reshape(B // num_windows_squared, num_windows_squared * HW, C)
- hidden_state = hidden_state.view(B // num_windows_squared, self.config.num_windows, self.config.num_windows, num_h_patches_per_window, num_w_patches_per_window, C)
- hidden_state = hidden_state.permute(0, 1, 3, 2, 4, 5)
+ hidden_state = hidden_state.reshape((B // num_windows_squared) * self.config.num_windows, self.config.num_windows, num_h_patches_per_window, num_w_patches_per_window, C)
+ hidden_state = hidden_state.permute(0, 2, 1, 3, 4)
hidden_state = hidden_state.reshape(batch_size, num_h_patches, num_w_patches, -1)
hidden_state = hidden_state.permute(0, 3, 1, 2).contiguous()
diff --git a/rfdetr/models/backbone/projector.py b/rfdetr/models/backbone/projector.py
index 3817557..cd9be4f 100644
--- a/rfdetr/models/backbone/projector.py
+++ b/rfdetr/models/backbone/projector.py
@@ -41,12 +41,9 @@ def forward(self, x):
LayerNorm forward
TODO: this is a hack to avoid overflow when using fp16
"""
- #if x.dtype == torch.half:
- # x = x / (x.max() + self.eps)
- u = x.mean(1, keepdim=True)
- s = (x - u).pow(2).mean(1, keepdim=True)
- x = (x - u) / torch.sqrt(s + self.eps)
- x = self.weight[:, None, None] * x + self.bias[:, None, None]
+ x = x.permute(0, 2, 3, 1)
+ x = F.layer_norm(x, (x.size(3),), self.weight, self.bias, self.eps)
+ x = x.permute(0, 3, 1, 2)
return x
@@ -103,7 +100,7 @@ def __init__(self, in_planes, out_planes, kernel=3, stride=1, groups=1, dilation
def forward(self, x):
""" forward """
- out = self.act(self.bn(self.conv(x)))
+ out = self.act(self.bn(self.conv(x.contiguous())))
return out
diff --git a/rfdetr/models/lwdetr.py b/rfdetr/models/lwdetr.py
index b871b72..9c1f058 100644
--- a/rfdetr/models/lwdetr.py
+++ b/rfdetr/models/lwdetr.py
@@ -34,12 +34,14 @@
from rfdetr.models.backbone import build_backbone
from rfdetr.models.matcher import build_matcher
from rfdetr.models.transformer import build_transformer
+from rfdetr.models.segmentation_head import SegmentationHead, get_uncertain_point_coords_with_randomness, point_sample
class LWDETR(nn.Module):
""" This is the Group DETR v3 module that performs object detection """
def __init__(self,
backbone,
transformer,
+ segmentation_head,
num_classes,
num_queries,
aux_loss=False,
@@ -64,7 +66,8 @@ def __init__(self,
hidden_dim = transformer.d_model
self.class_embed = nn.Linear(hidden_dim, num_classes)
self.bbox_embed = MLP(hidden_dim, hidden_dim, 4, 3)
-
+ self.segmentation_head = segmentation_head
+
query_dim=4
self.refpoint_embed = nn.Embedding(num_queries * group_detr, query_dim)
self.query_feat = nn.Embedding(num_queries * group_detr, hidden_dim)
@@ -126,7 +129,7 @@ def export(self):
m.export()
def forward(self, samples: NestedTensor, targets=None):
- """ The forward expects a NestedTensor, which consists of:
+ """ The forward expects a NestedTensor, which consists of:
- samples.tensor: batched images, of shape [batch_size x 3 x H x W]
- samples.mask: a binary mask of shape [batch_size x H x W], containing 1 on padded pixels
@@ -176,9 +179,14 @@ def forward(self, samples: NestedTensor, targets=None):
outputs_class = self.class_embed(hs)
+ if self.segmentation_head is not None:
+ outputs_masks = self.segmentation_head(features[0].tensors, hs, samples.tensors.shape[-2:])
+
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]}
+ if self.segmentation_head is not None:
+ out['pred_masks'] = outputs_masks[-1]
if self.aux_loss:
- out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
+ out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord, outputs_masks if self.segmentation_head is not None else None)
if self.two_stage:
group_detr = self.group_detr if self.training else 1
@@ -187,12 +195,22 @@ def forward(self, samples: NestedTensor, targets=None):
for g_idx in range(group_detr):
cls_enc_gidx = self.transformer.enc_out_class_embed[g_idx](hs_enc_list[g_idx])
cls_enc.append(cls_enc_gidx)
+
cls_enc = torch.cat(cls_enc, dim=1)
+
+ if self.segmentation_head is not None:
+ masks_enc = self.segmentation_head(features[0].tensors, [hs_enc,], samples.tensors.shape[-2:], skip_blocks=True)
+ masks_enc = torch.cat(masks_enc, dim=1)
+
if hs is not None:
out['enc_outputs'] = {'pred_logits': cls_enc, 'pred_boxes': ref_enc}
+ if self.segmentation_head is not None:
+ out['enc_outputs']['pred_masks'] = masks_enc
else:
out = {'pred_logits': cls_enc, 'pred_boxes': ref_enc}
-
+ if self.segmentation_head is not None:
+ out['pred_masks'] = masks_enc
+
return out
def forward_export(self, tensors):
@@ -204,6 +222,8 @@ def forward_export(self, tensors):
hs, ref_unsigmoid, hs_enc, ref_enc = self.transformer(
srcs, None, poss, refpoint_embed_weight, query_feat_weight)
+ outputs_masks = None
+
if hs is not None:
if self.bbox_reparam:
outputs_coord_delta = self.bbox_embed(hs)
@@ -215,20 +235,28 @@ def forward_export(self, tensors):
else:
outputs_coord = (self.bbox_embed(hs) + ref_unsigmoid).sigmoid()
outputs_class = self.class_embed(hs)
+ if self.segmentation_head is not None:
+ outputs_masks = self.segmentation_head(srcs[0], [hs,], tensors.shape[-2:])[0]
else:
assert self.two_stage, "if not using decoder, two_stage must be True"
outputs_class = self.transformer.enc_out_class_embed[0](hs_enc)
outputs_coord = ref_enc
-
- return outputs_coord, outputs_class
+ if self.segmentation_head is not None:
+ outputs_masks = self.segmentation_head(srcs[0], [hs_enc,], tensors.shape[-2:], skip_blocks=True)[0]
+
+ return outputs_coord, outputs_class, outputs_masks
@torch.jit.unused
- def _set_aux_loss(self, outputs_class, outputs_coord):
+ def _set_aux_loss(self, outputs_class, outputs_coord, outputs_masks):
# this is a workaround to make torchscript happy, as torchscript
# doesn't support dictionary with non-homogeneous values, such
# as a dict having both a Tensor and a list.
- return [{'pred_logits': a, 'pred_boxes': b}
- for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
+ if outputs_masks is not None:
+ return [{'pred_logits': a, 'pred_boxes': b, 'pred_masks': c}
+ for a, b, c in zip(outputs_class[:-1], outputs_coord[:-1], outputs_masks[:-1])]
+ else:
+ return [{'pred_logits': a, 'pred_boxes': b}
+ for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
def update_drop_path(self, drop_path_rate, vit_encoder_num_layers):
""" """
@@ -254,16 +282,17 @@ class SetCriterion(nn.Module):
2) we supervise each pair of matched ground-truth / prediction (supervise class and box)
"""
def __init__(self,
- num_classes,
- matcher,
- weight_dict,
- focal_alpha,
- losses,
- group_detr=1,
- sum_group_losses=False,
- use_varifocal_loss=False,
- use_position_supervised_loss=False,
- ia_bce_loss=False,):
+ num_classes,
+ matcher,
+ weight_dict,
+ focal_alpha,
+ losses,
+ group_detr=1,
+ sum_group_losses=False,
+ use_varifocal_loss=False,
+ use_position_supervised_loss=False,
+ ia_bce_loss=False,
+ mask_point_sample_ratio: int = 16,):
""" Create the criterion.
Parameters:
num_classes: number of object categories, omitting the special no-object category
@@ -284,6 +313,7 @@ def __init__(self,
self.use_varifocal_loss = use_varifocal_loss
self.use_position_supervised_loss = use_position_supervised_loss
self.ia_bce_loss = ia_bce_loss
+ self.mask_point_sample_ratio = mask_point_sample_ratio
def loss_labels(self, outputs, targets, indices, num_boxes, log=True):
"""Classification loss (Binary focal loss)
@@ -412,7 +442,65 @@ def loss_boxes(self, outputs, targets, indices, num_boxes):
box_ops.box_cxcywh_to_xyxy(target_boxes)))
losses['loss_giou'] = loss_giou.sum() / num_boxes
return losses
+
+ def loss_masks(self, outputs, targets, indices, num_boxes):
+ """Compute BCE-with-logits and Dice losses for segmentation masks on matched pairs.
+ Expects outputs to contain 'pred_masks' of shape [B, Q, H, W] and targets with key 'masks'.
+ """
+ assert 'pred_masks' in outputs, "pred_masks missing in model outputs"
+ pred_masks = outputs['pred_masks'] # [B, Q, H, W]
+ # gather matched prediction masks
+ idx = self._get_src_permutation_idx(indices)
+ src_masks = pred_masks[idx] # [N, H, W]
+ # handle no matches
+ if src_masks.numel() == 0:
+ return {
+ 'loss_mask_ce': src_masks.sum(),
+ 'loss_mask_dice': src_masks.sum(),
+ }
+ # gather matched target masks
+ target_masks = torch.cat([t['masks'][j] for t, (_, j) in zip(targets, indices)], dim=0) # [N, Ht, Wt]
+
+ # No need to upsample predictions as we are using normalized coordinates :)
+ # N x 1 x H x W
+ src_masks = src_masks.unsqueeze(1)
+ target_masks = target_masks.unsqueeze(1).float()
+
+ num_points = max(src_masks.shape[-2], src_masks.shape[-2] * src_masks.shape[-1] // self.mask_point_sample_ratio)
+
+ with torch.no_grad():
+ # sample point_coords
+ point_coords = get_uncertain_point_coords_with_randomness(
+ src_masks,
+ lambda logits: calculate_uncertainty(logits),
+ num_points,
+ 3,
+ 0.75,
+ )
+ # get gt labels
+ point_labels = point_sample(
+ target_masks,
+ point_coords,
+ align_corners=False,
+ mode="nearest",
+ ).squeeze(1)
+
+ point_logits = point_sample(
+ src_masks,
+ point_coords,
+ align_corners=False,
+ ).squeeze(1)
+
+ losses = {
+ "loss_mask_ce": sigmoid_ce_loss_jit(point_logits, point_labels, num_boxes),
+ "loss_mask_dice": dice_loss_jit(point_logits, point_labels, num_boxes),
+ }
+ del src_masks
+ del target_masks
+ return losses
+
+
def _get_src_permutation_idx(self, indices):
# permute predictions following indices
batch_idx = torch.cat([torch.full_like(src, i) for i, (src, _) in enumerate(indices)])
@@ -430,6 +518,7 @@ def get_loss(self, loss, outputs, targets, indices, num_boxes, **kwargs):
'labels': self.loss_labels,
'cardinality': self.loss_cardinality,
'boxes': self.loss_boxes,
+ 'masks': self.loss_masks,
}
assert loss in loss_map, f'do you really want to compute {loss} loss?'
return loss_map[loss](outputs, targets, indices, num_boxes, **kwargs)
@@ -540,6 +629,75 @@ def position_supervised_loss(inputs, targets, num_boxes, alpha: float = 0.25, ga
return loss.mean(1).sum() / num_boxes
+def dice_loss(
+ inputs: torch.Tensor,
+ targets: torch.Tensor,
+ num_masks: float,
+ ):
+ """
+ Compute the DICE loss, similar to generalized IOU for masks
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs
+ (0 for the negative class and 1 for the positive class).
+ """
+ inputs = inputs.sigmoid()
+ inputs = inputs.flatten(1)
+ numerator = 2 * (inputs * targets).sum(-1)
+ denominator = inputs.sum(-1) + targets.sum(-1)
+ loss = 1 - (numerator + 1) / (denominator + 1)
+ return loss.sum() / num_masks
+
+
+dice_loss_jit = torch.jit.script(
+ dice_loss
+) # type: torch.jit.ScriptModule
+
+
+def sigmoid_ce_loss(
+ inputs: torch.Tensor,
+ targets: torch.Tensor,
+ num_masks: float,
+ ):
+ """
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs
+ (0 for the negative class and 1 for the positive class).
+ Returns:
+ Loss tensor
+ """
+ loss = F.binary_cross_entropy_with_logits(inputs, targets, reduction="none")
+
+ return loss.mean(1).sum() / num_masks
+
+
+sigmoid_ce_loss_jit = torch.jit.script(
+ sigmoid_ce_loss
+) # type: torch.jit.ScriptModule
+
+
+def calculate_uncertainty(logits):
+ """
+ We estimate uncerainty as L1 distance between 0.0 and the logit prediction in 'logits' for the
+ foreground class in `classes`.
+ Args:
+ logits (Tensor): A tensor of shape (R, 1, ...) for class-specific or
+ class-agnostic, where R is the total number of predicted masks in all images and C is
+ the number of foreground classes. The values are logits.
+ Returns:
+ scores (Tensor): A tensor of shape (R, 1, ...) that contains uncertainty scores with
+ the most uncertain locations having the highest uncertainty score.
+ """
+ assert logits.shape[1] == 1
+ gt_class_logits = logits.clone()
+ return -(torch.abs(gt_class_logits))
+
+
class PostProcess(nn.Module):
""" This module converts the model's output into the format expected by the coco api"""
def __init__(self, num_select=300) -> None:
@@ -556,6 +714,7 @@ def forward(self, outputs, target_sizes):
For visualization, this should be the image size after data augment, but before padding
"""
out_logits, out_bbox = outputs['pred_logits'], outputs['pred_boxes']
+ out_masks = outputs.get('pred_masks', None)
assert len(out_logits) == len(target_sizes)
assert target_sizes.shape[1] == 2
@@ -573,7 +732,19 @@ def forward(self, outputs, target_sizes):
scale_fct = torch.stack([img_w, img_h, img_w, img_h], dim=1)
boxes = boxes * scale_fct[:, None, :]
- results = [{'scores': s, 'labels': l, 'boxes': b} for s, l, b in zip(scores, labels, boxes)]
+ # Optionally gather masks corresponding to the same top-K queries and resize to original size
+ results = []
+ if out_masks is not None:
+ for i in range(out_masks.shape[0]):
+ res_i = {'scores': scores[i], 'labels': labels[i], 'boxes': boxes[i]}
+ k_idx = topk_boxes[i]
+ masks_i = torch.gather(out_masks[i], 0, k_idx.unsqueeze(-1).unsqueeze(-1).repeat(1, out_masks.shape[-2], out_masks.shape[-1])) # [K, Hm, Wm]
+ h, w = target_sizes[i].tolist()
+ masks_i = F.interpolate(masks_i.unsqueeze(1), size=(int(h), int(w)), mode='bilinear', align_corners=False) # [K,1,H,W]
+ res_i['masks'] = masks_i > 0.0
+ results.append(res_i)
+ else:
+ results = [{'scores': s, 'labels': l, 'boxes': b} for s, l, b in zip(scores, labels, boxes)]
return results
@@ -638,9 +809,12 @@ def build_model(args):
args.num_feature_levels = len(args.projector_scale)
transformer = build_transformer(args)
+ segmentation_head = SegmentationHead(args.hidden_dim, args.dec_layers, downsample_ratio=args.mask_downsample_ratio) if args.segmentation_head else None
+
model = LWDETR(
backbone,
transformer,
+ segmentation_head,
num_classes=num_classes,
num_queries=args.num_queries,
aux_loss=args.aux_loss,
@@ -656,6 +830,9 @@ def build_criterion_and_postprocessors(args):
matcher = build_matcher(args)
weight_dict = {'loss_ce': args.cls_loss_coef, 'loss_bbox': args.bbox_loss_coef}
weight_dict['loss_giou'] = args.giou_loss_coef
+ if args.segmentation_head:
+ weight_dict['loss_mask_ce'] = args.mask_ce_loss_coef
+ weight_dict['loss_mask_dice'] = args.mask_dice_loss_coef
# TODO this is a hack
if args.aux_loss:
aux_weight_dict = {}
@@ -666,18 +843,29 @@ def build_criterion_and_postprocessors(args):
weight_dict.update(aux_weight_dict)
losses = ['labels', 'boxes', 'cardinality']
+ if args.segmentation_head:
+ losses.append('masks')
try:
sum_group_losses = args.sum_group_losses
except:
sum_group_losses = False
- criterion = SetCriterion(args.num_classes + 1, matcher=matcher, weight_dict=weight_dict,
- focal_alpha=args.focal_alpha, losses=losses,
- group_detr=args.group_detr, sum_group_losses=sum_group_losses,
- use_varifocal_loss = args.use_varifocal_loss,
- use_position_supervised_loss=args.use_position_supervised_loss,
- ia_bce_loss=args.ia_bce_loss)
+ if args.segmentation_head:
+ criterion = SetCriterion(args.num_classes + 1, matcher=matcher, weight_dict=weight_dict,
+ focal_alpha=args.focal_alpha, losses=losses,
+ group_detr=args.group_detr, sum_group_losses=sum_group_losses,
+ use_varifocal_loss = args.use_varifocal_loss,
+ use_position_supervised_loss=args.use_position_supervised_loss,
+ ia_bce_loss=args.ia_bce_loss,
+ mask_point_sample_ratio=args.mask_point_sample_ratio)
+ else:
+ criterion = SetCriterion(args.num_classes + 1, matcher=matcher, weight_dict=weight_dict,
+ focal_alpha=args.focal_alpha, losses=losses,
+ group_detr=args.group_detr, sum_group_losses=sum_group_losses,
+ use_varifocal_loss = args.use_varifocal_loss,
+ use_position_supervised_loss=args.use_position_supervised_loss,
+ ia_bce_loss=args.ia_bce_loss)
criterion.to(device)
- postprocessors = {'bbox': PostProcess(num_select=args.num_select)}
+ postprocess = PostProcess(num_select=args.num_select)
- return criterion, postprocessors
+ return criterion, postprocess
diff --git a/rfdetr/models/matcher.py b/rfdetr/models/matcher.py
index 1e9afb7..fe8f019 100644
--- a/rfdetr/models/matcher.py
+++ b/rfdetr/models/matcher.py
@@ -23,8 +23,11 @@
import torch
from scipy.optimize import linear_sum_assignment
from torch import nn
+import torch.nn.functional as F
+
+from rfdetr.util.box_ops import box_cxcywh_to_xyxy, generalized_box_iou, batch_sigmoid_ce_loss, batch_dice_loss
+from rfdetr.models.segmentation_head import point_sample
-from rfdetr.util.box_ops import box_cxcywh_to_xyxy, generalized_box_iou
class HungarianMatcher(nn.Module):
"""This class computes an assignment between the targets and the predictions of the network
@@ -34,7 +37,7 @@ class HungarianMatcher(nn.Module):
"""
def __init__(self, cost_class: float = 1, cost_bbox: float = 1, cost_giou: float = 1, focal_alpha: float = 0.25, use_pos_only: bool = False,
- use_position_modulated_cost: bool = False):
+ use_position_modulated_cost: bool = False, mask_point_sample_ratio: int = 16, cost_mask_ce: float = 1, cost_mask_dice: float = 1):
"""Creates the matcher
Params:
cost_class: This is the relative weight of the classification error in the matching cost
@@ -47,6 +50,9 @@ def __init__(self, cost_class: float = 1, cost_bbox: float = 1, cost_giou: float
self.cost_giou = cost_giou
assert cost_class != 0 or cost_bbox != 0 or cost_giou != 0, "all costs cant be 0"
self.focal_alpha = focal_alpha
+ self.mask_point_sample_ratio = mask_point_sample_ratio
+ self.cost_mask_ce = cost_mask_ce
+ self.cost_mask_dice = cost_mask_dice
@torch.no_grad()
def forward(self, outputs, targets, group_detr=1):
@@ -59,6 +65,7 @@ def forward(self, outputs, targets, group_detr=1):
"labels": Tensor of dim [num_target_boxes] (where num_target_boxes is the number of ground-truth
objects in the target) containing the class labels
"boxes": Tensor of dim [num_target_boxes, 4] containing the target box coordinates
+ "masks": Tensor of dim [num_target_boxes, H, W] containing the target mask coordinates
group_detr: Number of groups used for matching.
Returns:
A list of size batch_size, containing tuples of (index_i, index_j) where:
@@ -70,13 +77,20 @@ def forward(self, outputs, targets, group_detr=1):
bs, num_queries = outputs["pred_logits"].shape[:2]
# We flatten to compute the cost matrices in a batch
- out_prob = outputs["pred_logits"].flatten(0, 1).sigmoid() # [batch_size * num_queries, num_classes]
+ flat_pred_logits = outputs["pred_logits"].flatten(0, 1)
+ out_prob = flat_pred_logits.sigmoid() # [batch_size * num_queries, num_classes]
out_bbox = outputs["pred_boxes"].flatten(0, 1) # [batch_size * num_queries, 4]
# Also concat the target labels and boxes
tgt_ids = torch.cat([v["labels"] for v in targets])
tgt_bbox = torch.cat([v["boxes"] for v in targets])
+ masks_present = "masks" in targets[0]
+
+ if masks_present:
+ tgt_masks = torch.cat([v["masks"] for v in targets])
+ out_masks = outputs["pred_masks"].flatten(0, 1)
+
# Compute the giou cost betwen boxes
giou = generalized_box_iou(box_cxcywh_to_xyxy(out_bbox), box_cxcywh_to_xyxy(tgt_bbox))
cost_giou = -giou
@@ -85,16 +99,49 @@ def forward(self, outputs, targets, group_detr=1):
alpha = 0.25
gamma = 2.0
- neg_cost_class = (1 - alpha) * (out_prob ** gamma) * (-(1 - out_prob + 1e-8).log())
- pos_cost_class = alpha * ((1 - out_prob) ** gamma) * (-(out_prob + 1e-8).log())
+ # neg_cost_class = (1 - alpha) * (out_prob ** gamma) * (-(1 - out_prob + 1e-8).log())
+ # pos_cost_class = alpha * ((1 - out_prob) ** gamma) * (-(out_prob + 1e-8).log())
+ # we refactor these with logsigmoid for numerical stability
+ neg_cost_class = (1 - alpha) * (out_prob ** gamma) * (-F.logsigmoid(-flat_pred_logits))
+ pos_cost_class = alpha * ((1 - out_prob) ** gamma) * (-F.logsigmoid(flat_pred_logits))
cost_class = pos_cost_class[:, tgt_ids] - neg_cost_class[:, tgt_ids]
# Compute the L1 cost between boxes
cost_bbox = torch.cdist(out_bbox, tgt_bbox, p=1)
+ if masks_present:
+ # Resize predicted masks to target mask size if needed
+ # if out_masks.shape[-2:] != tgt_masks.shape[-2:]:
+ # # out_masks = F.interpolate(out_masks.unsqueeze(1), size=tgt_masks.shape[-2:], mode="bilinear", align_corners=False).squeeze(1)
+ # tgt_masks = F.interpolate(tgt_masks.unsqueeze(1).float(), size=out_masks.shape[-2:], mode="bilinear", align_corners=False).squeeze(1)
+
+ # # Flatten masks
+ # pred_masks_logits = out_masks.flatten(1) # [P, HW]
+ # tgt_masks_flat = tgt_masks.flatten(1).float() # [T, HW]
+
+ num_points = out_masks.shape[-2] * out_masks.shape[-1] // self.mask_point_sample_ratio
+
+ tgt_masks = tgt_masks.to(out_masks.dtype)
+
+ point_coords = torch.rand(1, num_points, 2, device=out_masks.device)
+ pred_masks_logits = point_sample(out_masks.unsqueeze(1), point_coords.repeat(out_masks.shape[0], 1, 1), align_corners=False).squeeze(1)
+ tgt_masks_flat = point_sample(tgt_masks.unsqueeze(1), point_coords.repeat(tgt_masks.shape[0], 1, 1), align_corners=False, mode="nearest").squeeze(1)
+
+ # Binary cross-entropy with logits cost (mean over pixels), computed pairwise efficiently
+ cost_mask_ce = batch_sigmoid_ce_loss(pred_masks_logits, tgt_masks_flat)
+
+ # Dice loss cost (1 - dice coefficient)
+ cost_mask_dice = batch_dice_loss(pred_masks_logits, tgt_masks_flat)
+
# Final cost matrix
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
- C = C.view(bs, num_queries, -1).cpu()
+ if masks_present:
+ C = C + self.cost_mask_ce * cost_mask_ce + self.cost_mask_dice * cost_mask_dice
+ C = C.view(bs, num_queries, -1).float().cpu() # convert to float because bfloat16 doesn't play nicely with CPU
+
+ # we assume any good match will not cause NaN or Inf, so we replace them with a large value
+ max_cost = C.max() if C.numel() > 0 else 0
+ C[C.isinf() | C.isnan()] = max_cost * 2
sizes = [len(v["boxes"]) for v in targets]
indices = []
@@ -114,8 +161,19 @@ def forward(self, outputs, targets, group_detr=1):
def build_matcher(args):
- return HungarianMatcher(
- cost_class=args.set_cost_class,
- cost_bbox=args.set_cost_bbox,
- cost_giou=args.set_cost_giou,
- focal_alpha=args.focal_alpha,)
\ No newline at end of file
+ if args.segmentation_head:
+ return HungarianMatcher(
+ cost_class=args.set_cost_class,
+ cost_bbox=args.set_cost_bbox,
+ cost_giou=args.set_cost_giou,
+ focal_alpha=args.focal_alpha,
+ cost_mask_ce=args.mask_ce_loss_coef,
+ cost_mask_dice=args.mask_dice_loss_coef,
+ mask_point_sample_ratio=args.mask_point_sample_ratio,)
+ else:
+ return HungarianMatcher(
+ cost_class=args.set_cost_class,
+ cost_bbox=args.set_cost_bbox,
+ cost_giou=args.set_cost_giou,
+ focal_alpha=args.focal_alpha,
+ )
\ No newline at end of file
diff --git a/rfdetr/models/segmentation_head.py b/rfdetr/models/segmentation_head.py
new file mode 100644
index 0000000..20e9164
--- /dev/null
+++ b/rfdetr/models/segmentation_head.py
@@ -0,0 +1,202 @@
+# ------------------------------------------------------------------------
+# RF-DETR
+# Copyright (c) 2025 Roboflow. All Rights Reserved.
+# Licensed under the Apache License, Version 2.0 [see LICENSE for details]
+# ------------------------------------------------------------------------
+
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from typing import Callable
+
+
+class DepthwiseConvBlock(nn.Module):
+ r""" Simplified ConvNeXt block without the MLP subnet
+ """
+ def __init__(self, dim, layer_scale_init_value=0):
+ super().__init__()
+ self.dwconv = nn.Conv2d(dim, dim, kernel_size=3, padding=1, groups=dim) # depthwise conv
+ self.norm = nn.LayerNorm(dim, eps=1e-6)
+ self.pwconv1 = nn.Linear(dim, dim) # pointwise/1x1 convs, implemented with linear layers
+ self.act = nn.GELU()
+ self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
+ requires_grad=True) if layer_scale_init_value > 0 else None
+
+ def forward(self, x):
+ input = x
+ x = self.dwconv(x)
+ x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
+ x = self.norm(x)
+ x = self.pwconv1(x)
+ x = self.act(x)
+ if self.gamma is not None:
+ x = self.gamma * x
+ x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
+
+ return x + input
+
+
+class MLPBlock(nn.Module):
+ def __init__(self, dim, layer_scale_init_value=0):
+ super().__init__()
+ self.norm_in = nn.LayerNorm(dim)
+ self.layers = nn.ModuleList([
+ nn.Linear(dim, dim*4),
+ nn.GELU(),
+ nn.Linear(dim*4, dim),
+ ])
+ self.gamma = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
+ requires_grad=True) if layer_scale_init_value > 0 else None
+
+ def forward(self, x):
+ input = x
+ x = self.norm_in(x)
+ for layer in self.layers:
+ x = layer(x)
+ if self.gamma is not None:
+ x = self.gamma * x
+ return x + input
+
+
+class SegmentationHead(nn.Module):
+ def __init__(self, in_dim, num_blocks: int, bottleneck_ratio: int=1, downsample_ratio: int=4):
+ super().__init__()
+
+ self.downsample_ratio = downsample_ratio
+ self.interaction_dim = in_dim // bottleneck_ratio if bottleneck_ratio is not None else in_dim
+ self.blocks = nn.ModuleList([DepthwiseConvBlock(in_dim) for _ in range(num_blocks)])
+ self.spatial_features_proj = nn.Identity() if bottleneck_ratio is None else nn.Conv2d(in_dim, self.interaction_dim, kernel_size=1)
+
+ self.query_features_block = MLPBlock(in_dim)
+ self.query_features_proj = nn.Identity() if bottleneck_ratio is None else nn.Linear(in_dim, self.interaction_dim)
+
+ self.bias = nn.Parameter(torch.zeros(1), requires_grad=True)
+
+ self._export = False
+
+ def export(self):
+ self._export = True
+ self._forward_origin = self.forward
+ self.forward = self.forward_export
+ for name, m in self.named_modules():
+ if hasattr(m, "export") and isinstance(m.export, Callable) and hasattr(m, "_export") and not m._export:
+ m.export()
+
+ def forward(self, spatial_features: torch.Tensor, query_features: list[torch.Tensor], image_size: tuple[int, int], skip_blocks: bool=False) -> list[torch.Tensor]:
+ # spatial features: (B, C, H, W)
+ # query features: [(B, N, C)] for each decoder layer
+ # output: (B, N, H*r, W*r)
+ target_size = (image_size[0] // self.downsample_ratio, image_size[1] // self.downsample_ratio)
+ spatial_features = F.interpolate(spatial_features, size=target_size, mode='bilinear', align_corners=False)
+
+ mask_logits = []
+ if not skip_blocks:
+ for block, qf in zip(self.blocks, query_features):
+ spatial_features = block(spatial_features)
+ spatial_features_proj = self.spatial_features_proj(spatial_features)
+ qf = self.query_features_proj(self.query_features_block(qf))
+ mask_logits.append(torch.einsum('bchw,bnc->bnhw', spatial_features_proj, qf) + self.bias)
+ else:
+ assert len(query_features) == 1, "skip_blocks is only supported for length 1 query features"
+ qf = self.query_features_proj(self.query_features_block(query_features[0]))
+ mask_logits.append(torch.einsum('bchw,bnc->bnhw', spatial_features, qf) + self.bias)
+
+ return mask_logits
+
+ def forward_export(self, spatial_features: torch.Tensor, query_features: list[torch.Tensor], image_size: tuple[int, int], skip_blocks: bool=False) -> list[torch.Tensor]:
+ assert len(query_features) == 1, "at export time, segmentation head expects exactly one query feature"
+
+ target_size = (image_size[0] // self.downsample_ratio, image_size[1] // self.downsample_ratio)
+ spatial_features = F.interpolate(spatial_features, size=target_size, mode='bilinear', align_corners=False)
+
+ if not skip_blocks:
+ for block in self.blocks:
+ spatial_features = block(spatial_features)
+
+ spatial_features_proj = self.spatial_features_proj(spatial_features)
+
+ qf = self.query_features_proj(self.query_features_block(query_features[0]))
+ return [torch.einsum('bchw,bnc->bnhw', spatial_features_proj, qf) + self.bias]
+
+
+def point_sample(input, point_coords, **kwargs):
+ """
+ A wrapper around :function:`torch.nn.functional.grid_sample` to support 3D point_coords tensors.
+ Unlike :function:`torch.nn.functional.grid_sample` it assumes `point_coords` to lie inside
+ [0, 1] x [0, 1] square.
+
+ Args:
+ input (Tensor): A tensor of shape (N, C, H, W) that contains features map on a H x W grid.
+ point_coords (Tensor): A tensor of shape (N, P, 2) or (N, Hgrid, Wgrid, 2) that contains
+ [0, 1] x [0, 1] normalized point coordinates.
+
+ Returns:
+ output (Tensor): A tensor of shape (N, C, P) or (N, C, Hgrid, Wgrid) that contains
+ features for points in `point_coords`. The features are obtained via bilinear
+ interplation from `input` the same way as :function:`torch.nn.functional.grid_sample`.
+ """
+ add_dim = False
+ if point_coords.dim() == 3:
+ add_dim = True
+ point_coords = point_coords.unsqueeze(2)
+ output = F.grid_sample(input, 2.0 * point_coords - 1.0, **kwargs)
+ if add_dim:
+ output = output.squeeze(3)
+ return output
+
+
+def get_uncertain_point_coords_with_randomness(
+ coarse_logits, uncertainty_func, num_points, oversample_ratio=3, importance_sample_ratio=0.75
+):
+ """
+ Sample points in [0, 1] x [0, 1] coordinate space based on their uncertainty. The unceratinties
+ are calculated for each point using 'uncertainty_func' function that takes point's logit
+ prediction as input.
+ See PointRend paper for details.
+
+ Args:
+ coarse_logits (Tensor): A tensor of shape (N, C, Hmask, Wmask) or (N, 1, Hmask, Wmask) for
+ class-specific or class-agnostic prediction.
+ uncertainty_func: A function that takes a Tensor of shape (N, C, P) or (N, 1, P) that
+ contains logit predictions for P points and returns their uncertainties as a Tensor of
+ shape (N, 1, P).
+ num_points (int): The number of points P to sample.
+ oversample_ratio (int): Oversampling parameter.
+ importance_sample_ratio (float): Ratio of points that are sampled via importnace sampling.
+
+ Returns:
+ point_coords (Tensor): A tensor of shape (N, P, 2) that contains the coordinates of P
+ sampled points.
+ """
+ assert oversample_ratio >= 1
+ assert importance_sample_ratio <= 1 and importance_sample_ratio >= 0
+ num_boxes = coarse_logits.shape[0]
+ num_sampled = int(num_points * oversample_ratio)
+ point_coords = torch.rand(num_boxes, num_sampled, 2, device=coarse_logits.device)
+ point_logits = point_sample(coarse_logits, point_coords, align_corners=False)
+ # It is crucial to calculate uncertainty based on the sampled prediction value for the points.
+ # Calculating uncertainties of the coarse predictions first and sampling them for points leads
+ # to incorrect results.
+ # To illustrate this: assume uncertainty_func(logits)=-abs(logits), a sampled point between
+ # two coarse predictions with -1 and 1 logits has 0 logits, and therefore 0 uncertainty value.
+ # However, if we calculate uncertainties for the coarse predictions first,
+ # both will have -1 uncertainty, and the sampled point will get -1 uncertainty.
+ point_uncertainties = uncertainty_func(point_logits)
+ num_uncertain_points = int(importance_sample_ratio * num_points)
+ num_random_points = num_points - num_uncertain_points
+ idx = torch.topk(point_uncertainties[:, 0, :], k=num_uncertain_points, dim=1)[1]
+ shift = num_sampled * torch.arange(num_boxes, dtype=torch.long, device=coarse_logits.device)
+ idx += shift[:, None]
+ point_coords = point_coords.view(-1, 2)[idx.view(-1), :].view(
+ num_boxes, num_uncertain_points, 2
+ )
+ if num_random_points > 0:
+ point_coords = torch.cat(
+ [
+ point_coords,
+ torch.rand(num_boxes, num_random_points, 2, device=coarse_logits.device),
+ ],
+ dim=1,
+ )
+ return point_coords
\ No newline at end of file
diff --git a/rfdetr/models/transformer.py b/rfdetr/models/transformer.py
index 9c2343b..343c6fc 100644
--- a/rfdetr/models/transformer.py
+++ b/rfdetr/models/transformer.py
@@ -528,7 +528,7 @@ def forward_post(self, tgt, memory,
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
- tgt = tgt + self.dropout3(tgt2)
+ tgt = (tgt + self.dropout3(tgt2))
tgt = self.norm3(tgt)
return tgt
diff --git a/rfdetr/util/box_ops.py b/rfdetr/util/box_ops.py
index ae3c267..ecedab4 100644
--- a/rfdetr/util/box_ops.py
+++ b/rfdetr/util/box_ops.py
@@ -15,6 +15,7 @@
Utilities for bounding box manipulation and GIoU.
"""
import torch
+import torch.nn.functional as F
from torchvision.ops.boxes import box_area
@@ -96,3 +97,58 @@ def masks_to_boxes(masks):
y_min = y_mask.masked_fill(~(masks.bool()), 1e8).flatten(1).min(-1)[0]
return torch.stack([x_min, y_min, x_max, y_max], 1)
+
+
+def batch_dice_loss(inputs: torch.Tensor, targets: torch.Tensor):
+ """
+ Compute the DICE loss, similar to generalized IOU for masks
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs
+ (0 for the negative class and 1 for the positive class).
+ """
+ inputs = inputs.sigmoid()
+ inputs = inputs.flatten(1)
+ numerator = 2 * torch.einsum("nc,mc->nm", inputs, targets)
+ denominator = inputs.sum(-1)[:, None] + targets.sum(-1)[None, :]
+ loss = 1 - (numerator + 1) / (denominator + 1)
+ return loss
+
+
+batch_dice_loss_jit = torch.jit.script(
+ batch_dice_loss
+) # type: torch.jit.ScriptModule
+
+
+def batch_sigmoid_ce_loss(inputs: torch.Tensor, targets: torch.Tensor):
+ """
+ Args:
+ inputs: A float tensor of arbitrary shape.
+ The predictions for each example.
+ targets: A float tensor with the same shape as inputs. Stores the binary
+ classification label for each element in inputs
+ (0 for the negative class and 1 for the positive class).
+ Returns:
+ Loss tensor
+ """
+ hw = inputs.shape[1]
+
+ pos = F.binary_cross_entropy_with_logits(
+ inputs, torch.ones_like(inputs), reduction="none"
+ )
+ neg = F.binary_cross_entropy_with_logits(
+ inputs, torch.zeros_like(inputs), reduction="none"
+ )
+
+ loss = torch.einsum("nc,mc->nm", pos, targets) + torch.einsum(
+ "nc,mc->nm", neg, (1 - targets)
+ )
+
+ return loss / hw
+
+
+batch_sigmoid_ce_loss_jit = torch.jit.script(
+ batch_sigmoid_ce_loss
+) # type: torch.jit.ScriptModule
diff --git a/rfdetr/util/early_stopping.py b/rfdetr/util/early_stopping.py
index 30bf888..bfc219b 100644
--- a/rfdetr/util/early_stopping.py
+++ b/rfdetr/util/early_stopping.py
@@ -18,7 +18,7 @@ class EarlyStoppingCallback:
verbose (bool): Whether to print early stopping messages
"""
- def __init__(self, model, patience=5, min_delta=0.001, use_ema=False, verbose=True):
+ def __init__(self, model, patience=5, min_delta=0.001, use_ema=False, verbose=True, segmentation_head=False):
self.patience = patience
self.min_delta = min_delta
self.use_ema = use_ema
@@ -26,6 +26,7 @@ def __init__(self, model, patience=5, min_delta=0.001, use_ema=False, verbose=Tr
self.best_map = 0.0
self.counter = 0
self.model = model
+ self.segmentation_head = segmentation_head
def update(self, log_stats):
"""Update early stopping state based on epoch validation metrics"""
@@ -33,10 +34,16 @@ def update(self, log_stats):
ema_map = None
if 'test_coco_eval_bbox' in log_stats:
- regular_map = log_stats['test_coco_eval_bbox'][0]
+ if not self.segmentation_head:
+ regular_map = log_stats['test_coco_eval_bbox'][0]
+ else:
+ regular_map = log_stats['test_coco_eval_masks'][0]
if 'ema_test_coco_eval_bbox' in log_stats:
- ema_map = log_stats['ema_test_coco_eval_bbox'][0]
+ if not self.segmentation_head:
+ ema_map = log_stats['ema_test_coco_eval_bbox'][0]
+ else:
+ ema_map = log_stats['ema_test_coco_eval_masks'][0]
current_map = None
if regular_map is not None and ema_map is not None: