Replies: 16 comments 1 reply
-
|
Source Code: https://github.com/jeffreyqdd/rust_bril/ What I DidI implemented Loop Invariant Code Motion as a separate compiler pass that runs after Dead Code Elimination (DCE) and GVN (I'll talk about this later). This pass identifies computations inside loops that do not depend on the loop iteration and safely moves them outside the loop to improve runtime performance. Because my code is in SSA form, I can naively move constants into the loop preheader, allowing me to iteratively move instructions that depend on loop-invariant outputs into the preheader. The LICM implementation runs in four main phases:

Correctness: This pass has been tested on ALL bril benchmarks, and the outputs match those of the original code. This pass is also tested in combination with DCE/LVN. Global Value Numbering Example
Example: In order of left to right, original code, DCE & GVN. Trickiest PartThe trickiest part of implementing LICM was converting out of SSA form which required me to:
To support this, I extended my Basic Block structure with two additional fields:
I personally think this is a necessary but jank solution arising from the tight coupling between my compiler’s CFGs, dominance relationships, and label mappings, which effectively make my I think my compiler would benefit immensely from another pass. By rebuilding the CFG, the compiler could reduce the label and block overhead introduced by:
BenchmarkingI used hyperfine, a command-line benchmarking tool that aggregates statistics across multiple runs. The benchmarks were performed on an Apple M2 Pro (6P + 4E) with 16 GB RAM, with the window open and fans set to max. I had scripts monitoring CPU Freq and Thermal Throttling to ensure all benchmarks were run fairly. I ran with a multiprocessing queue of 3 workers to guarantee performance core scheduling, and to minimize cache pollution between the benchmarks. Each bril file was run on 5 different compilation flags:
The results were unfortunate given the amount of time I spent on task 8. In the worst case, converting into and out of SSA greatly increased dynamic instruction count, and consequently, runtime. However, there were some programs that benefited immensely e.g. Delannoy. 

In general, it was better to not compile the programs at all due to the overhead generated by SSA. Interestingly enough, running optimizations made the programs more stable.
Generative AII used Copilot to help me write the plotting function and write the benchmark scaffolding. SummaryI think I deserve a Michelin star for the time I put into this project to get the optimizations working correctly and performing a comprehensive benchmark. |


Beta Was this translation helpful? Give feedback.
-
|
Explore benchmark plots^ |
Beta Was this translation helpful? Give feedback.
-
|
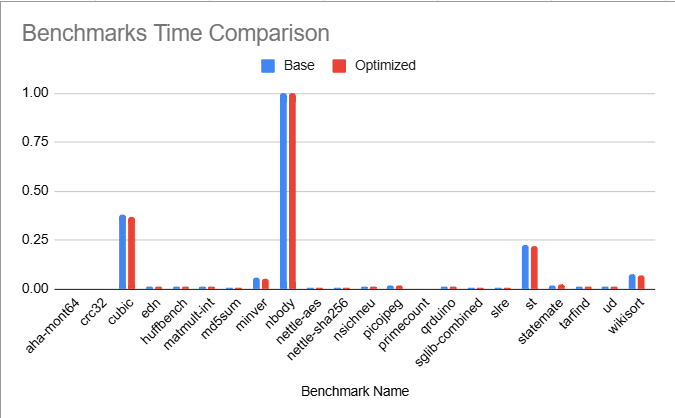
Team Members PassFor this assignment, we implemented LICM with LLVM. We noticed that LLVM had a lot of pre-built functions, such as Working with LLVM for this assignment was pretty frustrating. Namely, we had to juggle dynamically casting between const and non-const instructions (honestly this is pretty terrible C++ coding) as some built in LLVM functions required the parameters to be const, while others did not. TestingTo first sanity check our code, we write a simple C++ program and compared the intermediate representations with and without the pass. When we manually compared the intermediate representations, we noticed that the optimization was being implemented. To more rigorously test our code, we used Embench. Here are our results:
We also created a graph (with normalized values) to help visual the results:
It seems that we were able to speed up some of the programs with our LICM optimization. However, there are also many programs where the speed is unaffected or increased by the optimization. Overall, we observed no substantial results with embench. Perhaps more loop optimizations are necessary for obvious speedups in programs. Hardest PartThe most challenging part of this assignment was trying to navigate the complexity of LLVM and understanding how its internal analyses interacted. While conceptually the LICM algorithm is straightforward, implementing it in LLVM required careful management. Another challenge was setting up and running Embench for testing. The documentation and benchmarking workflow was initially confusing and took a fair amount of time. However, after much trial and error, we were finally able to get Embench working and collect performance data to test our optimization. Michelin StarWe believe that we deserve a michelin star for completely the specification of this assignment. Although we didn't see a desirable outcome, we still learned a lot by completing this assignment. |
Beta Was this translation helpful? Give feedback.
-
Team: Adnan Al Armouti, Tobias WeinbergLoop-Invariant Code Motion (LICM) for BrilFor this assignment, we built a Loop-Invariant Code Motion (LICM) optimization pass for Bril, written completely in Python. What we didWe started by constructing a control-flow graph and computing dominators to detect backedges ( What went wrong (and how we fixed it)At first, things broke in entertaining ways:
We fixed this by tightening our criteria — only hoisting pure arithmetic or logical ops ( ResultsWe evaluated our pass on the full Bril benchmark suite:
About one-third of programs sped up, most stayed the same, and only one regressed. TakeawaysBuilding LICM from scratch made us appreciate how much infrastructure (CFGs, dominators, SSA reasoning) modern compilers already have. GenAI disclaimerWe used ChatGPT (GPT-5) to help debug and structure our implementation — especially to clarify dominance logic, SSA rules, and control-flow algorithms. |

Beta Was this translation helpful? Give feedback.
-
Team MembersNing Wang (nw366), Jiale Lao (jl4492) Source Codehttps://github.com/NingWang0123/cs6120/tree/main/assa8 Implementation SummaryWe implemented Loop Invariant Code Motion (LICM), a classic loop optimization that hoists loop-invariant computations out of loops to reduce redundant work. The implementation works on Bril programs in SSA form. Key Components
Testing MethodologyWe tested the implementation on programs from the Bril benchmark suite (
Evaluation ResultsWe successfully optimized 8 benchmark programs that contain loop-invariant computations. All optimizations preserved program correctness while achieving measurable performance improvements. Benchmark Results
Aggregate Performance:
Visualizations Using GenAIWe generated a visualization of the LICM optimization results: Speedup ComparisonShows the speedup achieved for each of the 8 successfully optimized programs, with:

ChallengesWe selected to use Bril so there are not many challenges when implementating these codes: we are already familiar with Bril. Michelin StarWe have correct implementations, comprehensive tests, evaluations, and visualizations. We think we deserve a michelin star. |
Beta Was this translation helpful? Give feedback.
-
|
Source code: https://github.com/Mond45/llvm-pass-skeleton/tree/loop What I DidI implemented an LLVM pass that performs Loop-Invariant Code Motion (LICM) using the new pass manager. I also used an LLVM's utility functions to create a loop preheader as needed, and moved the collected loop-invariant instructions there once the identification step was complete. The Hardest PartThe most challenging part was figuring out why my pass wasn't performing any transformations, even on a simple example where an instruction was certainly loop-invariant. I eventually discovered that under To fix this, I included GenAI UsageI used ChatGPT as a reference for finding relevant LLVM functions. It was mostly helpful, although in some cases it suggested classes intended for the legacy pass manager. Testing and BenchmarkingI used the PolyBench C benchmark suite to test and evaluate the performance of my LICM optimization pass. For performance evaluation, I wrote a script to run each benchmark five times, collect the median execution time, and compute the speedup (as the ratio between the median times of the optimized and baseline runs). A graph showing speedup for each benchmark are shown below: 
The overall result, computed as the geometric mean of speedups across all benchmarks is 1.1234. ConclusionI believe I deserve a Michelin star for this work. I successfully implemented an LLVM LICM pass, verified its correctness, and provided a performance evaluation. |
Beta Was this translation helpful? Give feedback.
-
Team MembersNate Young (nty3) and Amanda Wang (arw274). Source Codehttps://github.com/arw274/cs6120_tasks/tree/main/task8 Implementation SummaryWe implemented LICM for Bril in Python. Our implementation consisted of two main components: one for detecting natural loops and another for executing LICM. The first part involved finding all backedges, and then for each backedge, we iteratively accumulate predecessors of the tail until we return to the head to form the loop. For executing LICM, we create preheaders wherever necessary, and then identify loop-invariance instructions to move to the corresponding pre-header. TestingWe tested our optimization on all core and float Bril benchmarks and verified that our LICM did not break on any of the benchmarks. To cherry-pick a couple of benchmarks on which LICM actually resulted in a speedup:
The Hardest PartWe thought about edge cases for a while, and didn't fully resolve them here, even though it didn't fail on any benchmarks. In particular, our code for detecting natural loops initially would construct a new loop for each backedge, even if multiple backedges pointed to the same header (say, if there was an if-else statement at the end of a for loop). To resolve this, we just merged all loops that shared the same header. However, it seems like this could be improved if a program contained nested loops that shared the same header (say, if we had several nested do-while loops). In this case, the loop-invariant instructions for the inner and outer loops could be different, and we'd ideally have separate pre-headers. We didn't deal with this because of time constraints though. Michelin StarWe believe we deserve a Michelin star for carefully handling/thinking about edge cases and for producing an implementation of LICM that was successful on all core Bril benchmarks. |
Beta Was this translation helpful? Give feedback.
-
|
Code: https://github.com/Nikil-Shyamsunder/compilers-cs6120/tree/main/llvm/loopFusion What I DidI implemented a simplified Loop Fusion Pass in LLVM that analyzes candidate loops for fusion and merges them when appropriate. The pass uses TestingI tested the pass using a simple program that performs matrix-matrix multiplication followed by ReLU 100 times inside a loop. After applying the pass, I verified through the Hardest PartThe most challenging aspect was understanding LLVM’s internal structure and pass pipeline. Unlike Bril, LLVM’s ecosystem is complex but provides powerful tools like ScalarEvolution and LoopInfo. Setting up the correct pipeline (using Michelin StarI think I deserve a Michelin star for implementing a nontrivial compiler optimization in LLVM. The pass makes some strong assumptions about the form of the program, but it works and I found a way to test and benchmark it effectively. I also made sure to learn and use the other passes and helper constructs in the LLVM ecosystem to make this work. |
Beta Was this translation helpful? Give feedback.
-
|
Source Code: HERE Implementation: I implemented LICM in LLVM. The implementation here was surprisingly trivial once I took advantage of LLVM's internal features (loop finding, preheader finding). I essentially had LLVM find the preheader, get all the components of the loop, and then if those components have ops that are from inside the loop (and aren't being moved) add them to the list. Once that's done iterate through and move them all to the pre-header Testing: I ran my code on all of the embench benchmarks, and observed a moderate speedup in performance across the board. The changes were not dramatic however, and only a few examples saw significant changes. I suspect this is because while I performed LICM, I did not remove dead loops. GAI Statement: I used ChatGPT again for references to methods and types. A good use of this was finding out how loop passes work, and discovering the "move before" function in LLVM, which made this implementation a lot easier. However, it failed pretty badly at embench, completely misunderstanding how to run it (thinking it used make) Michelin Star: I believe I deserve a Michelin star for this as I implemented LICM and performed rigorous testing using embench. |
Beta Was this translation helpful? Give feedback.
-
|
Implementation code: Link What I didI implemented a Loop-Invariant Code Motion (LICM) pass in LLVM that identifies computations inside loops which don’t depend on the loop iteration and moves them to the loop preheader. I used LLVM’s analyses like LoopInfo, DominatorTree, and AliasAnalysis to ensure safety and correctness. I tested the pass on a subset of Embench benchmarks. The results showed small but consistent speedups on arithmetic kernels, confirming the pass works correctly. EvaluationI evaluated on a subset ( The result are as the following: I plotted them out for better visualization: The results show that my LICM pass achieves modest performance gains on arithmetic-heavy benchmarks, with speedups typically around 1–3%. This suggests that the pass successfully hoisted loop-invariant computations and reduced redundant operations. However, the improvements are limited maybe because LLVM’s default optimization pipeline already performs similar transformations, leaving little redundant work for my pass to eliminate. Minor slowdowns in a few cases may be due to measurement noise or additional analysis overhead. It could also be that the benchmarks are the ones that are simpler so that there's not much space to optimize. The hardest partThe implementation is rather trivial like other people in this thread mentioned. I found it quite tricky to run the embench benchmark. I used a lot of help from GPT to figure it out. Gen AI usageI used ChatGPT to help me do this homework. I used it to:
|


Beta Was this translation helpful? Give feedback.
-
|
What I did |


Beta Was this translation helpful? Give feedback.
-
Team & CodeJake Hyun | Codebase What I DidI implemented Loop-Invariant Code Motion (LICM) for Bril and built a harness to evaluate it across benchmark suites. The pass identifies natural loops via back-edges (tail -> head where head dominates tail), computes a dependency-closed set of invariant instructions, creates a fresh preheader for each loop, and hoists safe, pure, single-def instructions out of the loop. Safety checks include purity (no effects, conservative op allowlist), unique def of destinations within the loop, and dominance criteria so the hoisted values are available at all loop entries. I also added an optional SSA mode: convert to SSA, run LICM, then convert back. The harness can additionally run the raw SSA program as a baseline. This allows comparing "After vs Before" (original program) and "After vs SSA" (benefit of LICM beyond SSA form alone). Testing and ResultsCorrectness: The harness runs original and optimized programs with identical
Geometric-mean ratios (we use GM because these are relative speedup/slowdown ratios; it aggregates multiplicative effects across programs). Lower is better when After/Before or After/SSA are reported:
Observations
Example run summaries: # All suites, no SSA wrapper
python test_licm.py benchmarks/core/ --out results_licm_core.json --plot --png licm_core.png
Matplotlib is building the font cache; this may take a moment.
Target programs: 66
100%|███████████████████████████████████████████████████████| 66/66 [00:20<00:00, 3.22it/s]
Successful optimizations: 63/66
Static Instr Ratio (GM): 1.004x
Dynamic Instr Ratio (GM): 0.987x
Wrote results to results_licm_core.json
Saved plot to licm_core.png# All suites, with SSA wrapper and SSA baseline comparison
python test_licm.py benchmarks/core benchmarks/float benchmarks/long benchmarks/mem benchmarks/mixed --plot --png ssa_licm_all.png --ssa --out results_ssa_licm.json
Target programs: 122
100%|███████████████████████████████████████████████| 122/122 [01:51<00:00, 1.10it/s]
Successful optimizations: 122/122
Static Instr Ratio (GM): 1.149x
Dynamic Instr Ratio (GM): 1.130x
Static vs SSA (GM): 0.965x
Dynamic vs SSA (GM): 0.894x
Wrote results to results_ssa_licm.json
Saved plot to ssa_licm_all.pngPlots:
Hardest Part
Generative AII used ChatGPT to port the SSA harness from lesson 6 to this LICM lesson, adapting it for the new optimization while maintaining similar structure and functionality. This accelerated iteration, helped spot subtle correctness issues. Michelin StarRuns across all 122 benchmarks, with and without SSA, and validates end-to-end (equivalence, JSON stats, plots). It's a compact, disciplined LICM pass that does real work across the suite, and I claim a Michelin star for completeness. |


Beta Was this translation helpful? Give feedback.
-
|
Loop-Invariant Code Motion in SSA Land! LICM I picked Bril and implemented in Racket loop-invariant code motion optimization. I added 3 passes to my compiler pipeline, broken into three stages: finding natural loops, loop-invariant analysis, and hoisting invariants. Loop-invariant analysis is completed in SSA form which simplifies the analysis. Hoisting invariants is also in SSA form and happens before hoisting phis. Finding Natural Loops I implemented natural loop detection following the SCC definition of a natural loop: a natural loop is a strongly connected component (SCC) of the CFG, with a single-entry point called the header which dominates all nodes in the SCC. First, I compute dominators for every node in the CFG. Then, I iteratively identify back edges, edges where the target dominates the source. For each strongly connected component (SCC), computed with Racket's Graph Library, I compute the unique header node as the intersection of the SCC with the dominator sets. If a header exists, I filter back edges ending at that header and pick one whose source’s dominator set fully contains all sources of such edges; this is done to handle nested loops. This back edge is temporarily removed to isolate the loop. The loop body is identified as the SCC nodes, and exits are computed as nodes in the SCC whose successors lie outside the SCC. The process recurses on a copy of the CFG with the back edge removed, building a hash mapping fresh loop identifiers to Loop-Invariant Analysis The procedure works in three steps. First, I identify all Hoisting Invariants
In SSA form, conditions (1) and (2) are automatically satisfied, so only (3) must be explicitly verified. To do this, for a given assignment, I extract the basic block ID from the destination (as in the loop-invariant analysis) and check that this block dominates all loop exits computed during natural loop identification. Once verified, the remaining safe invariants are hoisted to the loop preheader, using the same mechanism employed for hoisting phi nodes. Testing
Results Total: 56 | Improved: 14 (25.0%) | Worsened: 1 (1.8%) | Unchanged: 41 (73.2%) 
Overall, LICM improves 1/4 of the benchmarks. In Hardest Part Conclusion |
Beta Was this translation helpful? Give feedback.
-
|
I implemented a LICM pass in LLVM. I made use of several of LLVM's utility functions, e.g. There were several challenging aspects of this task: specifically, working with LLVM, and testing/debugging. I spent a fair amount of time trying to figure out why my LICM pass was not doing anything; this turned out to be because a I tested on all programs in the PolyBench benchmark suite. (1) I validated correctness, meaning that my LICM pass does not change the result of any of the computations, and (2) I ran each program with and without the LICM pass 5x, and computed the mean execution times and percentage speedup of the LICM optimization over the baseline. See the script for running the benchmarks, and the results. I sort of reinvented the wheel here; the benchmark suite has some utilities for running benchmarks, but it was fairly trivial with some help from ChatGPT to write a new script to compile and run everything with the desired flags. My LICM pass does not seem to generate much speedup on these benchmarks in practice. It does indeed move some instructions out of the loops, but I suspect that the logic may be too conservative. Another factor is variance in measurements across runs. However, I haven't had time to investigate this further. GenAI: I used ChatGPT to help write the script to run the PolyBench benchmarks. I gave it an example of the correct compiler commands to use for one benchmark, and asked it to run each baseline and LICM optimization 5 times and compute the mean runtimes and percentage speedups. It did a passable job; I'm sure we can further decrease verbosity/improve extensibility, but it works just fine. Star? I think so! The results don't show consistent or significant speedups, but I learned more about LLVM and did some pretty complete testing/benchmarking, so I think it was a good effort. |
Beta Was this translation helpful? Give feedback.
-
ImplementationI implemented the recommended LICM pass that follows the standard rule. An instruction is loop-invariant if all the values it depends on come from outside the loop or from other already-invariant instructions. The pass works in four steps: 1. It first calls simplifyLoop() to make sure each loop has a proper preheader and exit blocks before running the optimization. 2. It repeatedly scans the loop, marking any instruction as invariant if it is safe to remove, has no side effects, is not a PHI node or terminator, and all its operands are either constants, defined outside the loop, or already marked invariant. 3. Before moving anything, it verifies that the instruction dominates all its uses, is not used by PHI nodes, and that its basic block dominates all loop exits. 4. Safe invariant instructions are then moved to the loop preheader. The pass is conservative. It skips anything that might have side effects or isn’t safe to remove, so it doesn’t hoist loads or other risky operations. I tested it on three of the Embench and confirmed that it detects and moves invariant instructions in normalized loops. TestingThe LICM pass was tested using three benchmarks from Embench: cubic, matmult-int, and nbody. The testing pipeline followed three steps. First, each benchmark’s source code was compiled to LLVM Intermediate Representation (IR). Second, the custom LICM pass implemented as skeleton-pass inside SkeletonPass.dylib was applied to the generated IR using the LLVM opt tool. Finally, the original and transformed IR files were compared using diff to quantify the modifications. The pass successfully transformed all three benchmarks: 1. cubic: from 275 to 281 lines, with 42 lines changed and 3 loop exit blocks added. 2. matmult-int: from 297 to 303 lines, with 32 lines changed and 3 loop exit blocks added. 3. nbody: from 403 to 440 lines, with 117 lines changed and 23 loop exit blocks added. |
Beta Was this translation helpful? Give feedback.
-
|
open source: https://github.com/CynyuS/loop_opt Cynthia Shao and Jonathan Brown worked together on this task. SummaryWe implemented LICM in LLVM. Furthermore, we created .sh scripts to automate running the benchmarks for the Embench Suite. Overall, this task was very fun and playing around with LLVM and benchmarking libraries was a great learning experience! LICMThe first step to implementing LICM was to identify when code was loop invariant. I first took all the Loop Invariant instructions and stored them into a vector, then removed them and inserted them before the preheader terminator. Then I quickly realized that my Loop invariant implementation… didn’t work. I realized I had to account for if the instr is a terminator, mayHaveSideEffects, and make sure that it isn’t a store/load. After this, we had to make sure that the instr wasn’t used within the loop. Testing and BenchmarkingFor testing, we used the llvm-test-suite to test our passes correctness on 2463 designs. This test suite also conveniently functions as a benchmark, but we decided to use Embench instead! For benchmarking, we utilized the Embench Suite. This was a simple and easy way to benchmark our pass compared to the baseline of no opts pass -O0 for clang. We had to implement a new script that would use the time module in python to capture the correct runtime of running these programs, as the original benchmark times in milliseconds were captured on a much slower processor. The good news is that the LICM pass on a variety of programs resulted in an overall speedup, and no slow downs!! Hardest PartWe struggled while researching LoopPass and LLVM to find the functions necessary to complete this assignment. Something that was helpful was using the autocomplete that would list all possible methods / fields of a given variable. Reading through this as well as researching was significantly helpful in discovering the methods and types to implement our LICM pass. We also struggled to set up and find appropriate benchmarking methods and correctness verification suites, and we were wondering what methods were used to formally verify LLVM passes. Self AssessmentWe believe we deserve a Michelin star because we are proud of our work! We brainstormed an implementation of LICM within LLVM, and thoroughly tested it. We tested thoroughly using the LLVM lit test suite, and the Embench test suite for performance. We also practiced good team coding practices with git, and learned a lot about LLVM and the benchmarking process, ensuring correctness across all programs! We believe we deserve a Michelin star for the tenacity and persistence put into the task. |
Beta Was this translation helpful? Give feedback.
-
Loop-invariant code motionBy Helen and Pedro, at our Codeberg repo We implemented a loop-invariant code motion (LICM) pass that operates on Bril programs in SSA. EvaluationThe pass was tested in isolation by comparing SSA+LICM to an SSA baseline. We did not want to rely on the performance of our out-of-SSA pass as it would likely produce noisier results. We evaluated using the core Bril benchmarks, and the pass produced correct output in all cases. Figure 1 displays the benchmarking results as percentage speedup of SSA+LICM over SSA.
We observed that near half of the benchmarks presented speedups, a few of them above the 10% threshold. In particular, we found that benchmarks that were loop-heavy had relatively large performance gains. For example: We initially also found that some benchmarks showed speeddowns. The implementation of the pass (see below) depends on several passes that can add overhead, and further work was needed to undo the simplifications that the LICM pass depends on. We found that, in particular, loop canonicalization sometimes added empty blocks that end up unutilized, and similarly with unnecessary jump instructions. We were able to revert these additions after the LICM pass by implementing an empty block removal pass and a redundant jump/return removal pass. With these passes added, none of the benchmarks showed speeddowns. ImplementationThe Bril development suite is undergoing a major redesign that created very significant task dependency and delays in testing loop-related code. The redesign involved adapting the entire code base to new interfaces and was very challenging. Nonetheless, we believe that managing the technical debt now instead of postponing it further was the correct decision to move forward with the project. Workflow aside, we began our loop journey by ensuring that blocks had a canonical form, beginning with a label and ending with a terminator instruction. This was desirable because the loop canonicalization pass needed to insert blocks, and repointing predecessors and successors was much easier in this canonical block form. We also built an interface to insert empty blocks given a set of predecessors and a successor. Afterwards, we began work on the analysis pass to detect natural loops. We used dominance analysis to identify backedges and construct the loop body for a given header block, and also stored information about preheader candidates, exiting blocks, latches, and exit blocks. We used the LLVM loop terminology guide to identify edge cases. The next step was canonicalizing loops. We built a pass to ensure that every natural loop had:
We modeled these conditions after the LLVM LoopSimplify pass. The pass was designed to be as non-conservative as possible; for example, if unique preheaders, latches, or exits already exist, the pass does not create new ones. Finally, we got to implementing LICM. Since the code was in SSA form, some of the conditions become trivial --- for instance, the reaching definitions analysis is redundant since there is only one definition per variable. We identified instructions that were loop-invariant to convergence, excluding side effects and PHI nodes. We were relatively conservative in this assessment, which meant that thanks to the SSA guarantees, we were always able to move an instruction marked as loop-invariant to the preheader. Lastly, we designed the pass itself, collecting loops, canonicalizing them, and conducting LICM on each of them. Afterwards, we worked to undo some of the loop simplification as we found it added performance overhead. As discussed above, we implemented an empty block removal pass and a redundant jump removal pass. Challenges and starBoth the redesign and the natural loop detection and canonicalization were very major challenges. We initially considered simply implementing LICM in LLVM, which already has those passes as well as helper functions to determine whether an instruction is loop-invariant or safe to hoist. But ultimately, we felt that a large part of our learning about loops would have been greatly diminished had we used LLVM. We are also consistent in our choice of not using generative AI for this project. We worked hard on this and are proud of our evolving code base, which throughout this redesign has become very significantly more flexible and usable. We find our loop detection and canonicalization well-documented, elegant, modular, and simple in most ways. And it is also performant, demonstrating significant speedups in about half of the benchmarks in the suite. In summary, despite the two-day delay on delivery, we are happy with our work and believe we deserve a star! |

{kind=link}
{kind=link}
{kind=link}
Beta Was this translation helpful? Give feedback.
Uh oh!
There was an error while loading. Please reload this page.
-
Which loop optimization did you pick?
Beta Was this translation helpful? Give feedback.
All reactions