- Docker version 19.03.6
- docker-compose version 1.17.1
$ docker-compose up -d
$ docker exec -ti model bash
$ python3 src/main.py
$ docker exec -ti model bash
$ python3
$ from train.predict import Predict
$ from main as mn
$ mn.main()
$ predict_obj = Predict()
$ predict_obj.predict(10)
$ docker exec -ti model bash
$ pytest test/
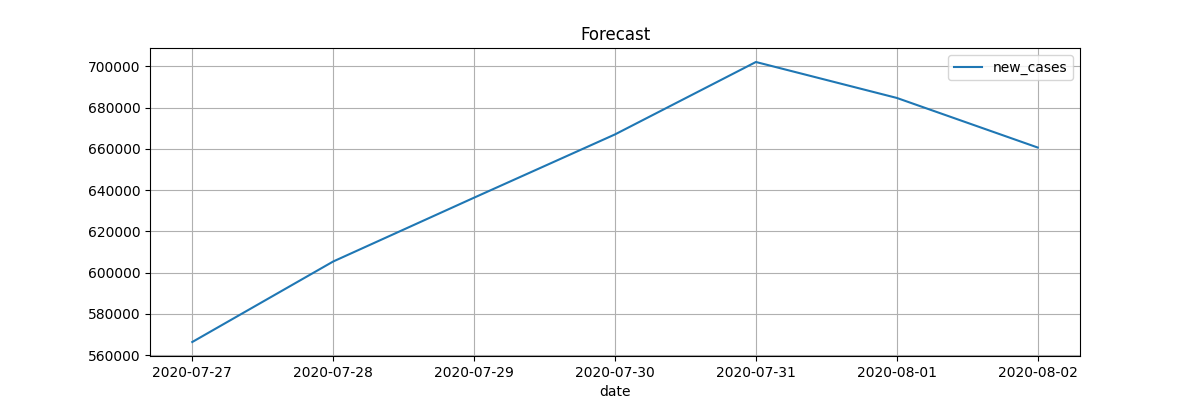
O treino gera alguns gráficos que são exibidos nessa página, a cada predict o primeiro gráfico pode alterar dependendo da quantidade de dias e do seu novo aprendizado.
http://127.0.0.1:5000
`datalake` -> *Repositório de dados*
`|__history` -> *Modelos e Parquets do resultado das predições por dia*
`|__images` -> *Gráficos gerados durante a predição*
`|__results` -> *Modelo atual e parquet atual para predição*
`|__sources` -> *Dados brutos*
`doc` -> *Arquivos auxiliares para essa documentação*
`fluentd` -> *Agregador de logs para o elasticsearch*
`ipynb` -> *Notebook com raciocínio para encontrar uma melhor solução*
`model` -> *Aplicação de treino*
`|__src` -> *Código fonte*
`..|__datalake` -> *Volume que aponta para o diretório datalake*
`..|__train` -> *Fonte de treino e predição*
`..|__utils` -> *Classes auxiliares*
`..|__settings.py` -> *Garante que todas as variáveis de ambiente existem*
`|__test` -> *Testes unitários com pytest*
`web` -> *Projeto web para exibir gráficos gerados no treino e predição*
`|__src` -> *Código fonte*
`..|__static` -> *Volume para o diretório images do datalake*
`..|__templates` -> *Arquivos html*
`..|__app.py` -> *Aplicação flask*
`|__test` -> *Testes unitários com pytest*
TIMESTAMP -> timestamp para o projeto
URL_DATASOURCE -> URL da fonte dos dados
ALL_COLS -> Colunas importantes no momento
DAYS_MEAN -> Quantidade de dias para calcular uma Média de evolução
START_DATE_DATA -> Iniciar o treino a partir dessa data YYYY-mm-dd
COLUMNS_PREDICT -> Colunas padrão para predição
ESTIMATORS -> Quantidade de estimators do RandomForestRegressor
N_JOBS= -> Quantidade de núcleos do processador a serem utilizados
RANDOM_STATE -> Quantidade de randomização dos dados
TEST_VARIABLES -> Testar ou não cada combinação de variável
PREDICT_DAYS -> Default de dias pra prever
DATALAKE -> Path do datalake
PYTHONPATH -> Diretórios que contém os módulos python
PYTHONUNBUFFERED -> Exibir saídas do stdout
PYTHONIOENCODING -> Encode padrão
FLUENTD_HOST -> Host do fluentd para registro dos logs
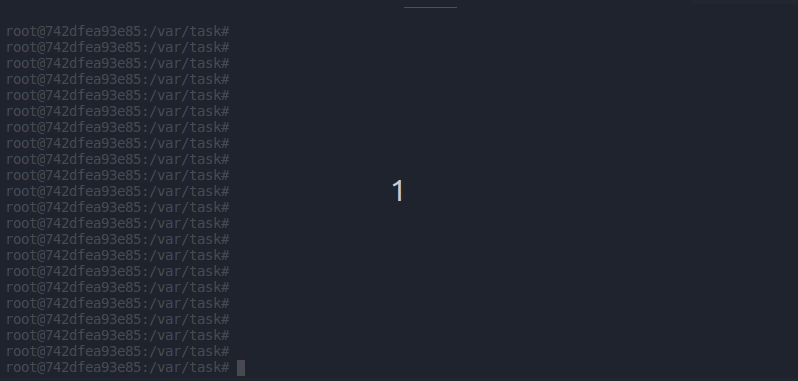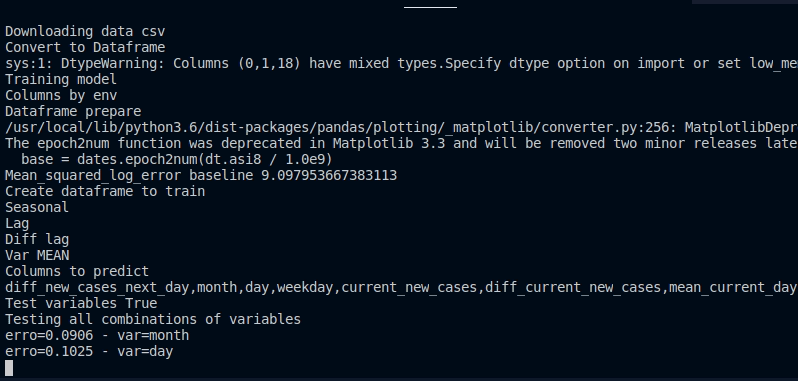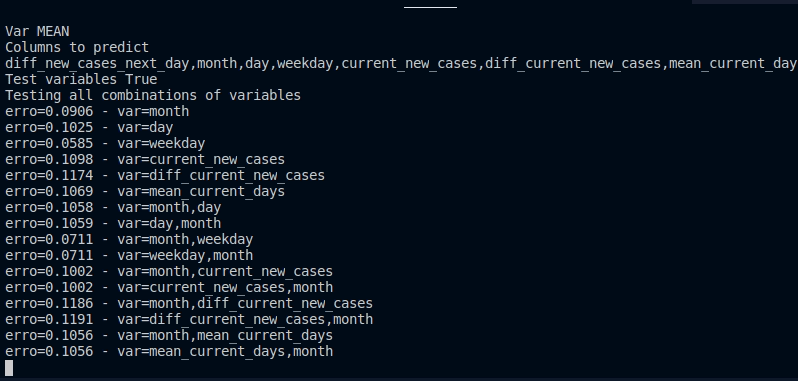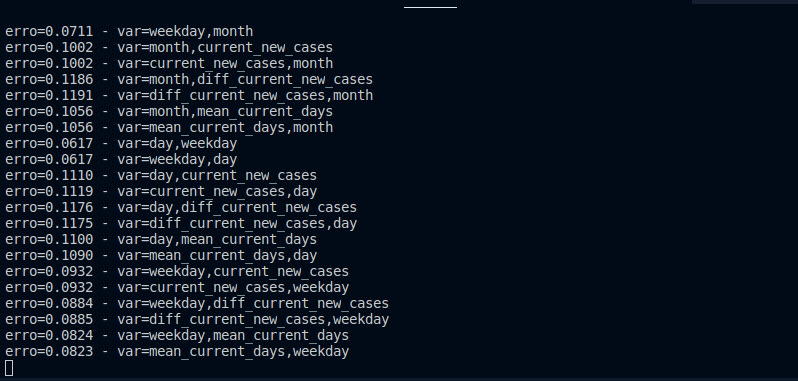
FLUENTD_PORT -> Porta do fluentdComo a ordem das variáveis e a quantidade podem influenciar para uma melhor predição, definindo a variável TEST_VARIABLES com o valor 1, o projeto irá testar todas as variáveis do dataframe de treino, e retornar qual o erro quadrático médio, a combinação com menor erro será salva no datalake como datalake/results/columns.json
Dessa forma toda nova predição seguirá essas colunas e não as colunas definidas no COLUMNS_PREDICT
Nesse projeto inclui o fluentd, onde todos os logs gerados pelo projeto model, são enviados para elasticsearch, mas podemos alterar o driver do fluentd e salvar esses logs em outro lugar, como arquivo de texto, banco de dados etc...
Isso nos auxilia para atuar no troubleshooting.