This GitHub repository preserves a script used to evaluate extractive question answering models on the LegalQAEval legal question answering benchmark.
Currently, the best performing models on the benchmark are Isaacus' Kanon Answer Extractor and Kanon Answer Extractor Mini as shown below.
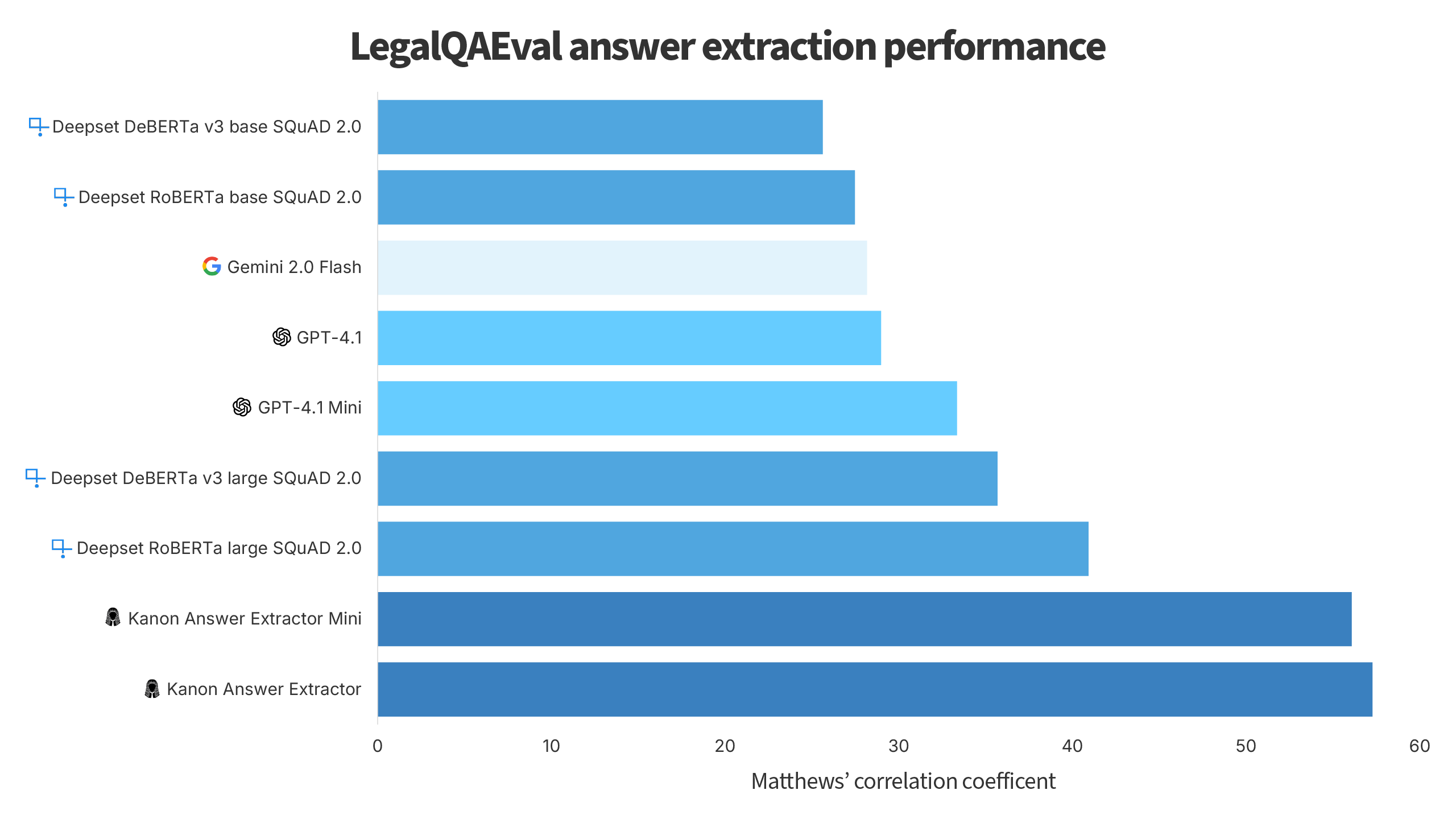
To take into account both the ability of models to determine when a question has an answer that is extractable from a particular text as well as their ability to extract the correct answers from texts, this code evaluates models as if they were classification models, where a ground label would only be positive if an example had an answer and the prediction would only be positive if the answer was correctly extracted by a model (correct in this context meaning that the answer had a Levenshtein similarity to any of the ground truth answers that was greater than 0.4). Matthews’ correlation coefficient, widely regarded as the gold standard for evaluating the balanced predictive power of classifiers, is then used to determine the overall performance of the models.
The full benchmarks of the most popular legal and general-purpose information extraction models on LegalQAEval may be found here.