- IMDB is an online database of information on films, television series and video games founded by Col needham in 1990. It os now a subsidiary of Amazon.
- They have currenty 8.7 million titles, 11.4 million person records and 83 million registered users
- Webscrape movie data from https://www.imdb.com/
- Perform exploratory data analysis on the data collected
• Beautiful Soup, Selenium (data collection) • Pandas (data processing) • Matplotlib, Seaborn
-
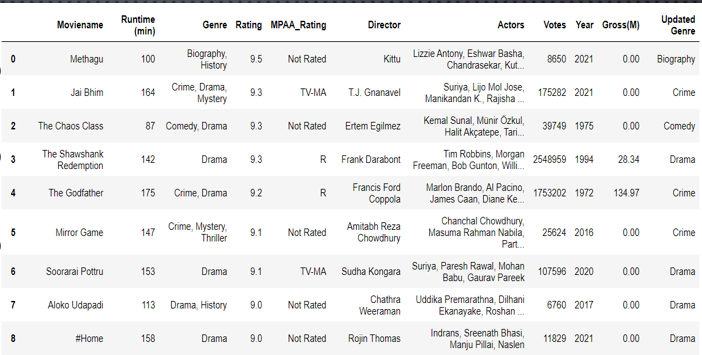
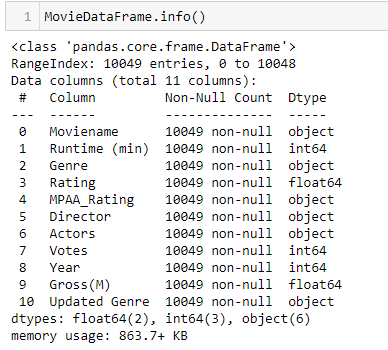
Collected 10,000 movie title using function inputMovieData(), data was saved to Moviedataframe (shape :(10049, 11))
-
94 Bestpicture data was collected using function InputSearchResultpage() and saving them into dataframe BestPictureadatframe (shape :(94,11))

- Used regular expression to extract Year, Gross from respective columns.
- Converted columns Year, Runtime, Rating, Votes,Gross from String to numeric.
- Removed null values
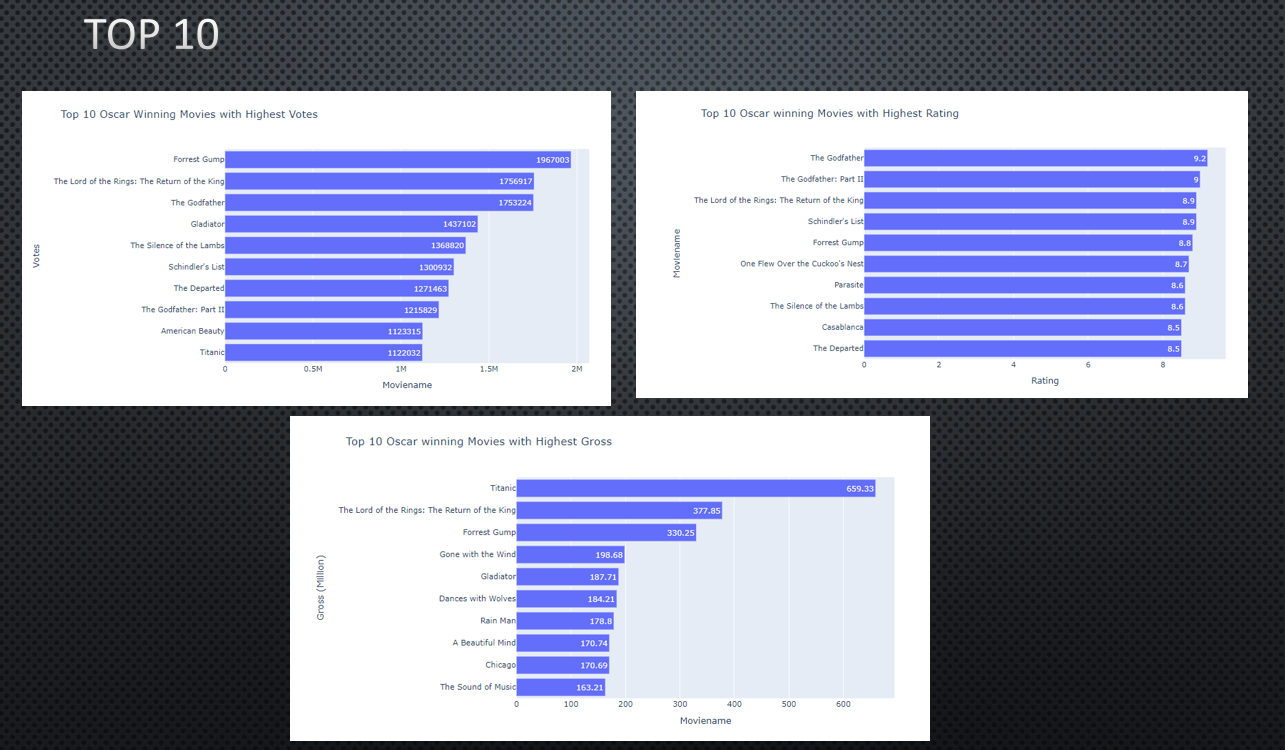
- Drama movies have won maximum Oscar Awards for Best Picture.
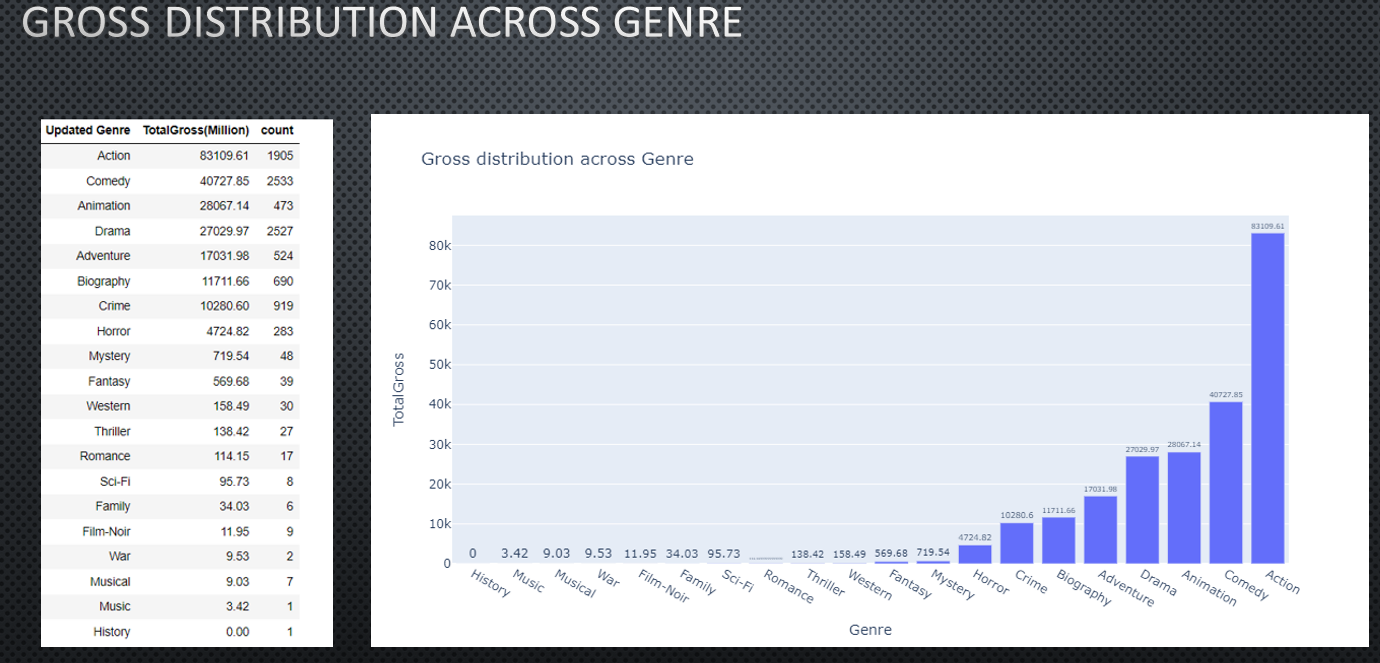
- Action movies tend to make high revenues.
- Average ratings for top gross movies is 7.4
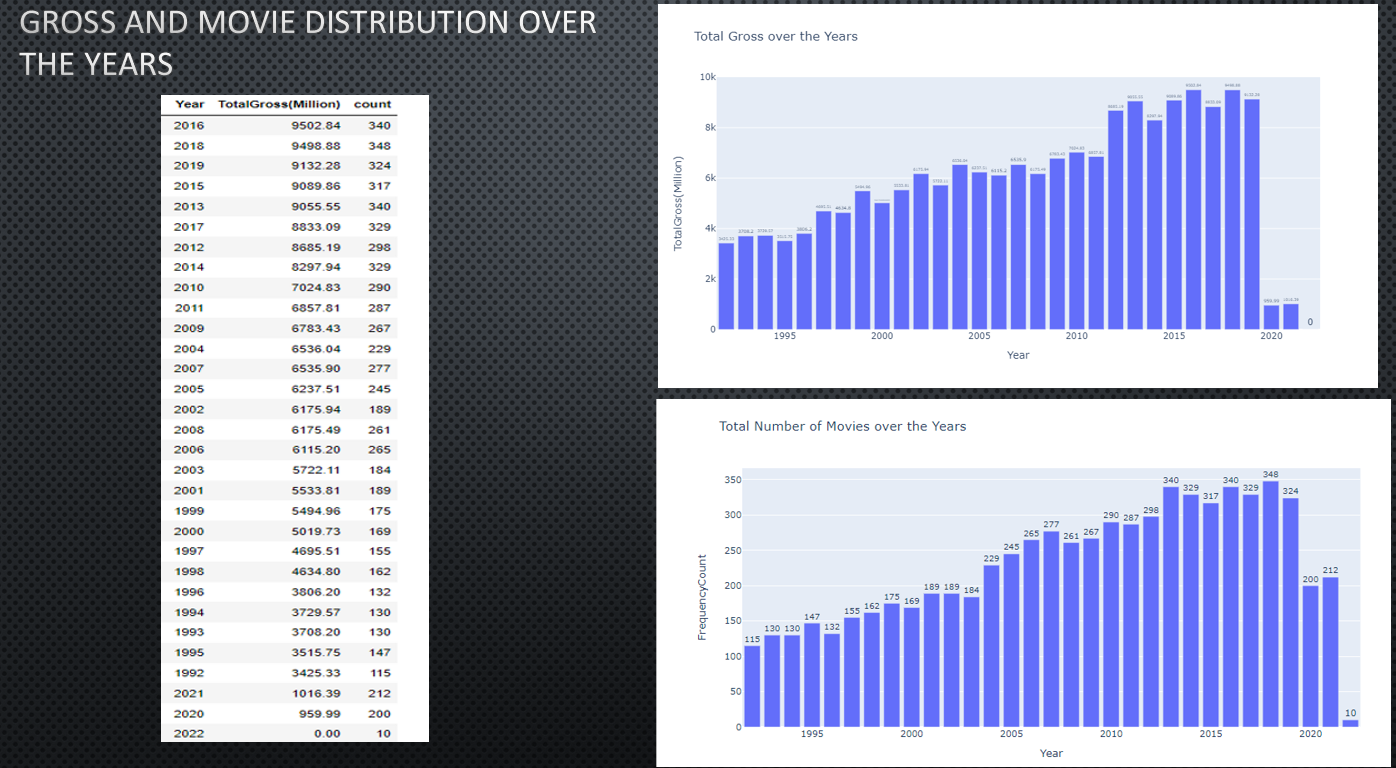
- Gross margin looks to plummet steeply in 2020 which may be an affect due to Covid.