Consensus
Consensus follows the algorithm described by "the latest gossip on BFT consensus". It includes two modifications: fast forwarding and rebasing.
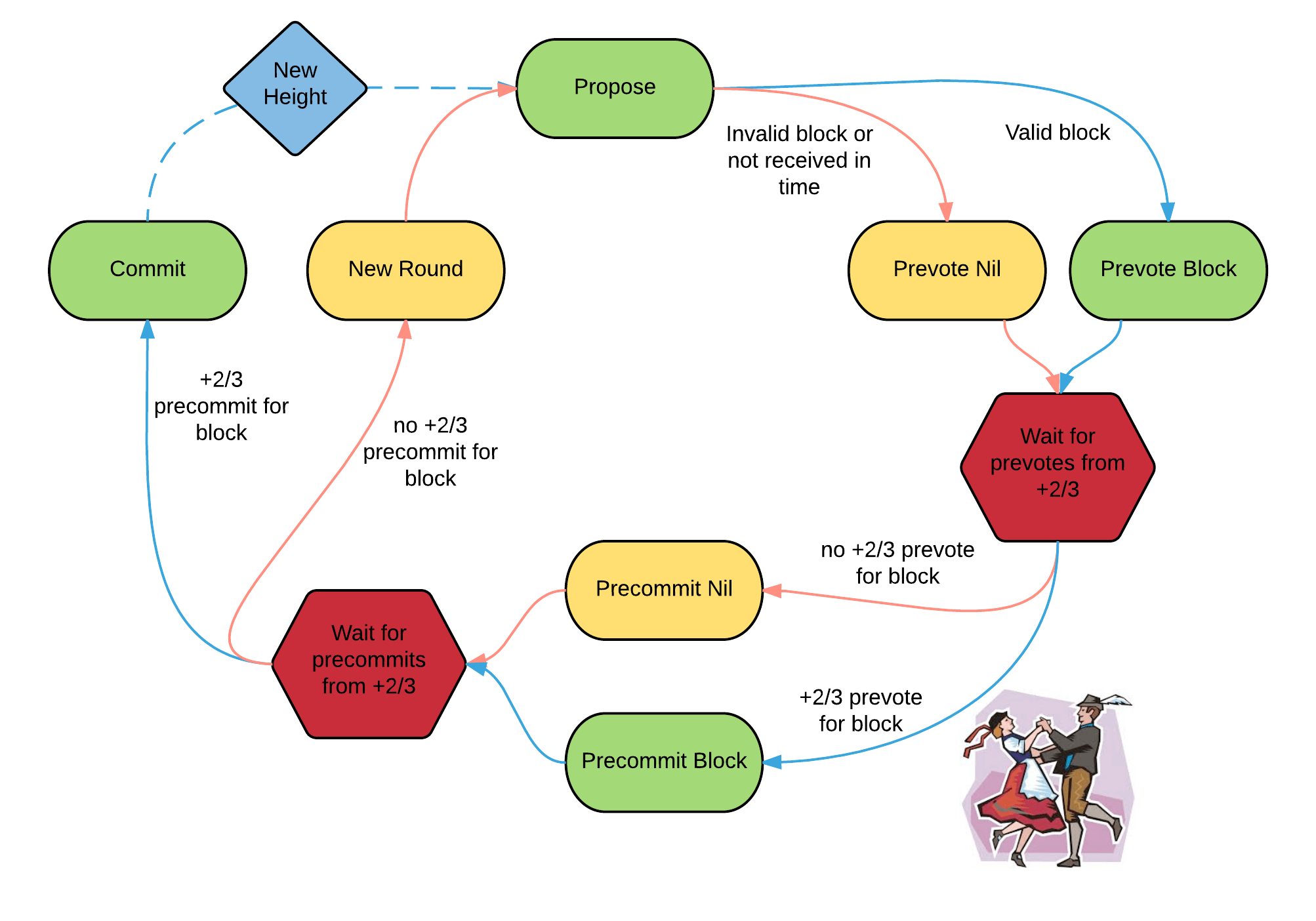
At every height (and every round in that height), a proposer is selected by an agreed proposers schedule (Hyperdrive comes with a simple round-robin schedule). The selected proposer must propose a valid block before the proposing timeout.
Every replica waits to receive the propose. If they see a proposal for a valid block, before their proposing timeout, they will prevote for the proposed block. Otherwise, the replica will prevote for nil.
After prevoting, replicas wait to receive prevotes from all of the other replicas. After receiving 2/3rds of prevotes, they begin their prevoting timeout. If they see 2/3rd+ prevotes for the same block, before their prevoting timeout, they will precommit to that block. Otherwise, they will precommit for nil.
After precommitting, replicas wait to receive precommits from all of the other replicas. After receiving 2/3rds of precommits, they start their precommitting timeout. If they see 2/3rd+ precommits for the same block, before their precommitting timeout, they will commit to that block and consensus is finished for this height and the process begins again for the next height. Otherwise, they will not commit to anything, increase the round, and the process begins again for the same height.
The algorithm described by "the latest gossip on BFT consensus" assumes that processes will eventually see all messages. This allows the algorithm to restrict its cases to messages that are bound for the H_p (the current height of the honest process). However, this is not true in practice, since honest processes may find themselves crashing unexpectedly, or on the wrong side of a network partition.
For example, an honest process could become unavailable at height H_p and not become available again until H_p+N. At this point, none of the cases described by "the latest gossip on BFT consensus" will be triggered. Ideally, such an honest process is able to fast forward to H_p + N without relying on other honest processes relaying all missing messages.
We introduce the case:
upon (PROPOSAL, H, Round, V, *) and 2F+1 (PRECOMMIT, H, Round, id(V)) while H > H_p do
if valid(V) then
Decision_p [H_p] = V
H_p = H + 1
reset LockedRound_p, LockedValue_p, ValidRound_p, and ValidValue_p to initial values and empty message log
startRound 0
This case applies no limit on the number of blocks that can be fast-forwarded. However, there is an implicit limit applied by rebasing: a replica cannot fast-forward over a base block, unless it has seen the base block. This is because, without the base block, the replica cannot verify if the 2/3rd+ signatories on later blocks are the required signatories. In practice, the (PROPOSAL, H, Round, V, *) and (PRECOMMIT, H, Round, id(V)) messages required to trigger this case are optionally sent as part of a new (PROPOSAL, H + N, *, *, *) message.
Let's look at an example:
- We assume that the network is operating as expected: there are no malicious adversaries and no replicas are offline, and blocks have been successfully produced up to height
H. Suddenly, 1/3rd- of replicas suddenly find themselves in a network partition; they are unable to see any of the messages sent by the other 2/3rd+ of replicas. - In the large partition there are 2/3rd+ honest replicas, and it follows from the liveliness properties of the Tendermint consensus algorithm that this partition is able to continue producing blocks. In the other, smaller, partition there are 1/3rd- replicas. This smaller partition does not have enough replicas to produce any blocks, so the replicas remain at height
Huntil the partition is healed. - After some time, the partition is healed, and the replicas that were in the larger partition have successfully produced blocks up to height
H+100(with no base blocks). All replicas can now receive messages from all other replicas. - In the next propose, for height
H+101, the proposer will attach the latest 2/3rd+ precommits that it received at heightH+100(it must have received these precommits because the larger partition remained lively, so eventually some proposer will exist that has seen these precommits). - All replicas that were in the smaller partition see this propose and therefore see the 2/3rd+ precommits from the previous height. Without fast-forwarding, the height difference would prevent these replicas from making accepting the propose. However, by acknowledging that the 2/3rd+ precommits imply no other blockchain history can exist they are able to set their height to
H+101and handle the propose.
Rebasing is used to change the signatories that are responsible for maintaining consensus. This is done by introducing special blocks that suggest new signatories. The existing signatories approve this suggestion by committing these special blocks in the usual way. After commitment, the new signatories become responsible.
It is assumed that the application using Hyperdrive will call the Rebase method when appropriate. For example, when some condition is true in the latest committed application-specific block state, when a special application-specific transaction is executed, or when some external event is triggered. In RenVM, rebasing is triggered once every 24 hours at midnight GMT.
Base blocks
Base blocks define the signatories that are responsible for proposing, prevoting, and precommitting blocks up to, and including, the next base block. All blocks must reference the most recently committed base block. Base blocks themselves reference the previously committed base block. This makes it easy to lookup which signatories should be proposing, prevoting, and precommitting at any given height.
- Base blocks must reference a rebase block as their parent,
- must define the same set of signatories in their header (as defined in the header of their parent),
- must include the previous state,
- must not include transactions, and
- must not include an execution plan.
The genesis block is a base block with no reference to a parent block, no reference to a previously committed base block, and it is assumed to be finalised.
Hyperdrive assumes that all commitments to base blocks will eventually be seen. In practice, this can be implemented at as part of the broadcaster, where the broadcaster will persist proposals and precommits for base blocks until they are sent, or it can be implemented as a separate resynchronisation mechanism, where nodes explicitly request missing base blocks from each other (by requesting the proposal and precommits for the missing base block, or some other proof that the base block was committed).
Rebase blocks
Rebase blocks are used to suggest that the blockchain rebases to a new set of signatories. Committing the rebase block implies that all of the current signatories approve of the suggestion, and the next block will be a base block. The existence of the base block is required to finalise any new state produced by the rebase block.
- Rebase blocks must reference a standard block as their parent,
- must define some set of signatories in their header,
- must include the previous state,
- can include transactions, and
- can include an execution plan.
Standard blocks
- Standard blocks must not define a set of signatories in their header,
- must include the previous state,
- can include transactions, and
- can include an execution plan.