[6주차] 이동현 JUN7453, JUN9252 #15
Open
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
|
|
||
| public class JUN9252_LeeDongHyun { | ||
| static int[][] map; // LCS를 구하는 표 | ||
| static Stack<Character> result = new Stack<>(); // 표에서 LCS를 찾기위해 역순으로 출력하기 위한 stack |
Comment on lines
+49
to
+74
| * 정렬에서 | ||
| * primitive type -> quicksort ( avg = O(nlog(n)) / worst = O(n^2) ) | ||
| * wrapper type -> merge sort, tim sort ( avg, worst = O(nlog(n)) ) | ||
| * | ||
| * 병합 정렬이 퀵 정렬보다 빠르다고 생각할 수 있지만 | ||
| * 최악의 상황에선 퀵 정렬이 느리지만 보통 퀵 정렬이 더 빠르고 메모리도 적게 먹음 | ||
| * | ||
| * 그 이유는 참조 지역성의 원리에 있음 | ||
| * 정렬의 실제 동작 시간은 C*시간복잡도+a 라고 할 때 a라는 상수 값은 보통 무시할 수 있지만 | ||
| * 곱해지는 C에 대해서 생각해야한다 C라는 변수는 참조 지역성의 원리가 영향을 미친다. | ||
| * | ||
| * Array (primitive)는 메모리적으로 각 값들이 연속적인 주소를 가지고 있기 때문에 | ||
| * C 값이 낮다 (캐시 히트 높음) | ||
| * | ||
| * 하지만 Collections은 메모리적으로 산발적인 LinkedList 등이 있기 때문에 참조 인접성이 좋지 않고 | ||
| * C의 값이 상대적으로 높다. 그렇기 때문에 퀵 정렬이 아니고 최악의 시간이 낮은 Tim정렬이 평균적으로 | ||
| * 더 좋은 성능을 기대할 수 있기 때문에 이용한다. | ||
| * https://d2.naver.com/helloworld/0315536 의 글을 읽어보면 | ||
| * | ||
| * 정렬 알고리즘 중 C 값이 가장 작다고 알려진 QuickSort의 상수 C를 Cq라고 할 때, | ||
| * 작은 n에 대하여 Ci * n^2 < Cq * nlog(n) 이 성립한다. | ||
| * 즉, 작은 n에 대하여 insertion sort(tim sort 의 기반의 되는 정렬) 가 빠르다. | ||
| * | ||
| * 따라서 내가 공부한 결론은 보통 Collections.sort 즉 wrapper타입의 정렬이 빠르다. | ||
| * 하지만 알고리즘에서 stable할 필요가 없고 N이 크다면 quick sort가 빠르다. | ||
| */ |
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
3 participants
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
JUN7453
A+B && C+D 배열 생성 후 sort 각각의 포인터를 차례대로 움직이면서 합이 0되는 곳 찾기
JUN9252
최장 공통 부분 수열이 무엇인지 구글링을 했는데...
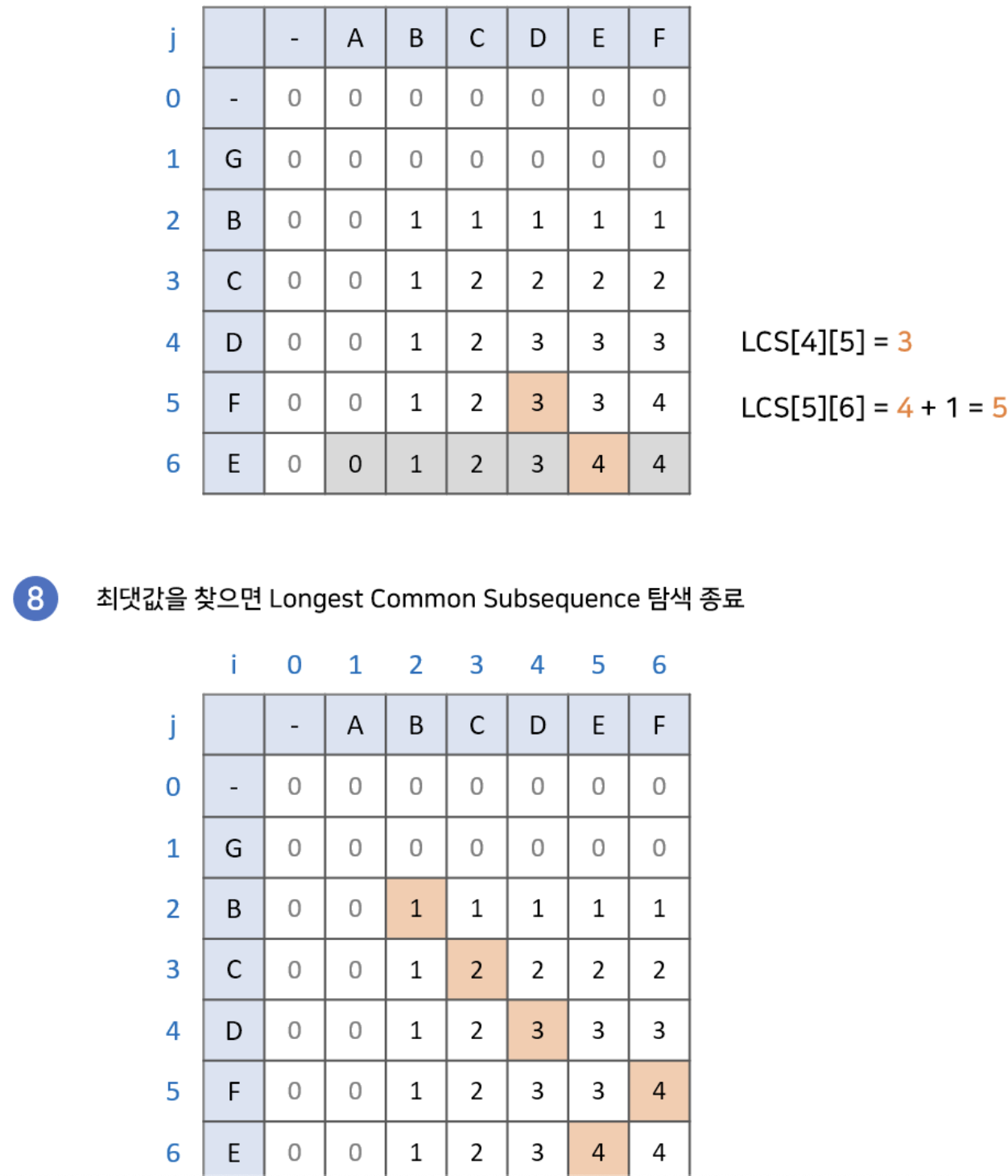
이 그림을 보자마자 이렇게 풀 수 밖에 없는 몸이 되어버렸습니다...
개념에 대한 정석 풀이입니다.
주석 참조