How to check the same status of data in each row within a group with esProc
The ID field of a certain database table is the grouping field of cars, and each group of cars is further subdivided into brand and type.
| ID | Brand | Type |
|---|---|---|
| 1 | Honda | Coupe |
| 1 | Jeep | SUV |
| 2 | Ford | Sedan |
| 2 | Ford | Crossover |
Now we need to group the cars by ID and calculate whether the difference between the cars in the group is in terms of brand or type. If there is more than one brand of car in the group, we will assign the difference column to Brand; If there is more than one type of car in the group, assign the difference as Type.
| ID | Difference |
|---|---|
| 1 | Brand |
| 1 | Type |
| 2 | Type |
After SQL grouping, it is necessary to aggregate immediately, making it difficult to make logical judgments in the grouped subset, and the indirectly implemented code is very complex. SPL can retain the grouped subset for further calculation:
https://try.esproc.com/splx?3c3
| A | |
|---|---|
| 1 | $select * from tbl.txt |
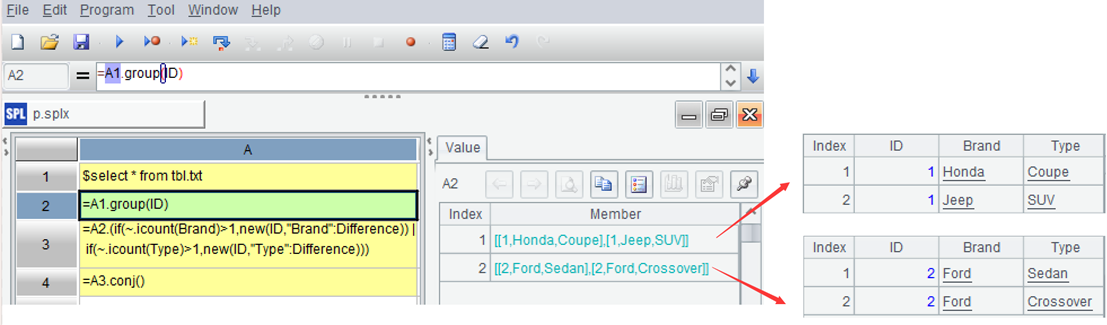
| 2 | =A1.group(ID) |
| 3 | =A2.(if(~.icount(Brand)>1,new(ID,"Brand":Difference)) |
| 4 | =A3.conj() |
A1: Load data.
A2: Use the group function to group by ID, but do not aggregate. Each group is a set of records.
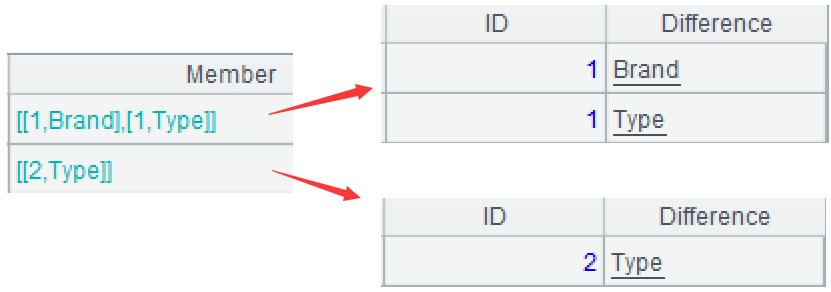

=A1.group(ID). conj(if(~.icount(Brand)>1,new(ID,"Brand":Difference))|if(~.icount(Type)>1,new(ID,"Type":Difference)))