How to operate large CSV files with esProc SPL
esProc SPL provides cursor operations, which can operate large CSV files with very simple code. With slight modifications, it can be converted into parallel computing. It also has a graphical interface, which is much more convenient than Python. First, go here to download esProc SPL: https://www.esproc.com/download-esproc/ If you don't want to bother with the source code, the standard edition can be used., download and install it. Prepare a large CSV file:
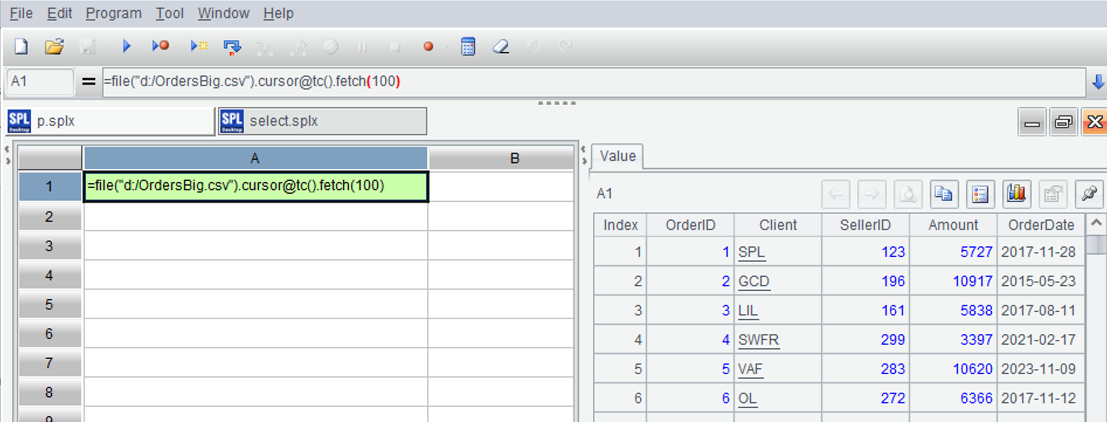
=file("d:/OrdersBig.csv").cursor@tc().fetch(100)
The function cursor represents opening the text file with a cursor, and @ represents the function's extension options, @t represents the first row being column names, @c represents commas as the separator. Because it is a large file, loading it all into memory may overflow, so fetch only 100 entries and take a look. Press ctrl-F9 to execute, and you can see the calculation result data table on the right.
Let's try the calculation. First, count the rows:
| A | |
|---|---|
| 1 | =file("d:/OrdersBig.csv").cursor@tc() |
| 2 | =A1.skip() |
The skip function is used to skip N records and return the number of skipped records. When the parameter is empty, all records are skipped.

Then take a look at the filtering, select records with Amount between 3000 and 4000 and Client containing s:
| A | |
|---|---|
| 1 | =file("d:/OrdersBig.csv").cursor@tc() |
| 2 | =A1.select(Amount>3000 && Amount<=4000 && like@c(Client,"s")) |
| 3 | =A1.fetch(100) |
The select function is used for conditional filtering, the like function is used for string matching, and * is a wildcard, @c means not case sensitive.
Because there may still be many results, we only take the first 100 entries to see, and the execution result is in A3:
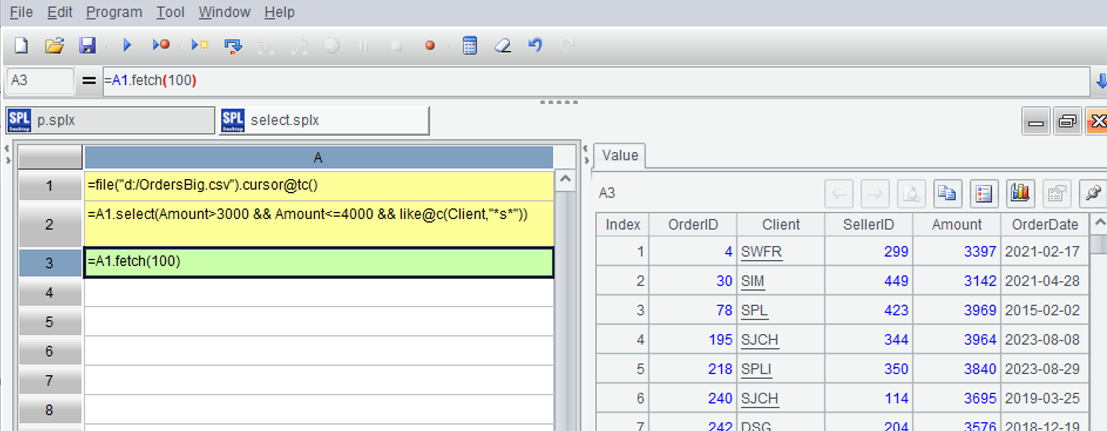
| A | |
|---|---|
| 1 | =file("d:/OrdersBig.csv").cursor@tc() |
| 2 | =A1.sortx(OrderDate,-Amount) |
| 3 | =file("d:/result.csv").export@tc(A2) |
| 4 | =file("d:/result.csv").cursor@tc().fetch(100) |
After sorting, write the results into a new file, then open the new file and retrieve the first 100 entries. The function sortx is used for sorting large files, where - represents reverse order.
After execution, look at the result on the right, it has been sorted.
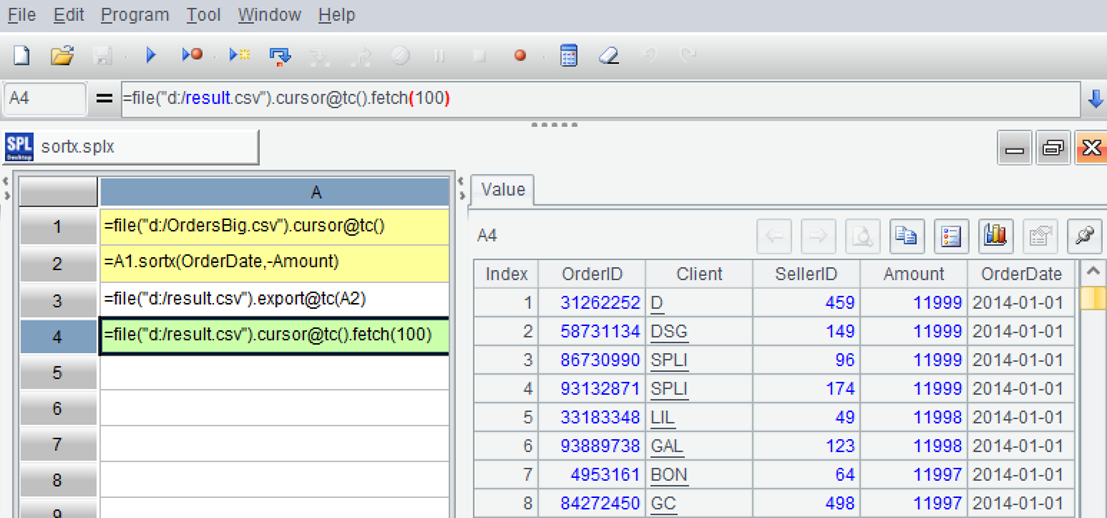
| A | |
|---|---|
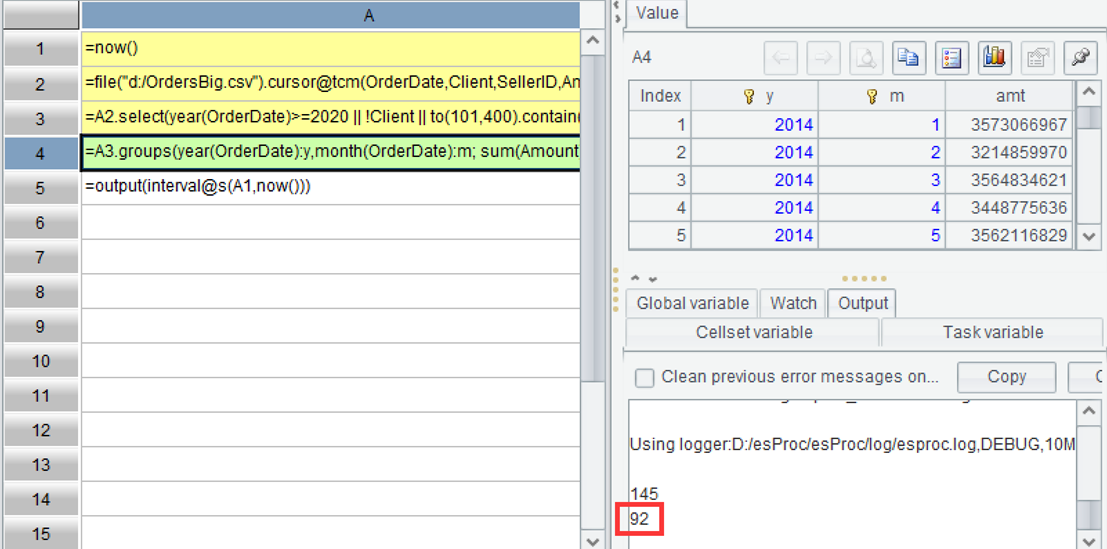
| 1 | =now() |
| 2 | =file("d:/OrdersBig.csv").cursor@tc(OrderDate,Client,SellerID,Amount) |
| 3 | =A2.select(year(OrderDate)>=2020 |
| 4 | =A3.groups(year(OrderDate):y,month(OrderDate):m; sum(Amount):amt) |
| 5 | =output(interval@s(A1,now())) |
SQL programmers must be familiar with the groups function in A4, so we won't go into detail here.
A2 can read only the columns to be used when opening the cursor, which can improve speed. A1 and A5 have also been added here to track the running time and print it on the console:
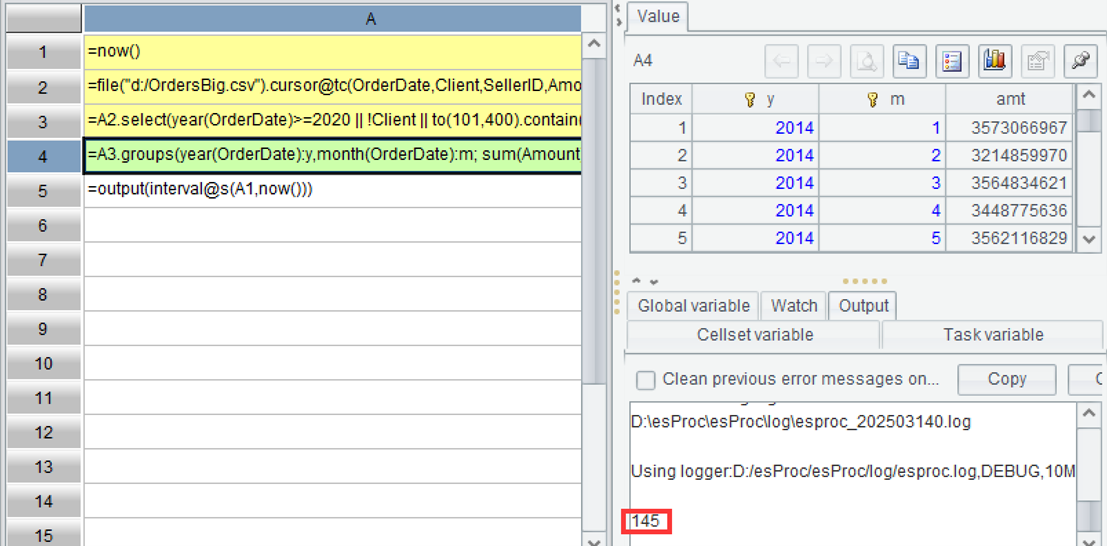
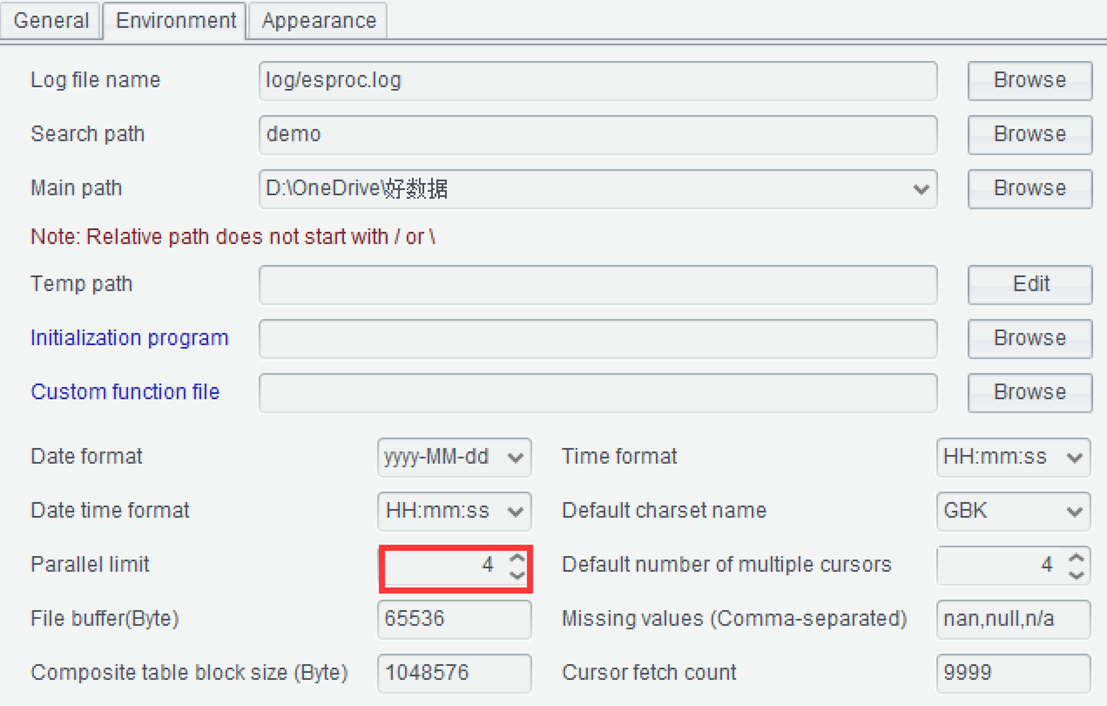
Parallel computing can fully utilize current multi-core CPUs and must be tried. Change the above code to parallel computing, simply add an option @m after the cursor function, and leave the rest unchanged:
| A | |
|---|---|
| 1 | =now() |
| 2 | =file("d:/OrdersBig.csv").cursor@tcm(OrderDate,Client,SellerID,Amount) |
| 3 | =A2.select(year(OrderDate)>=2020 |
| 4 | =A3.groups(year(OrderDate):y,month(OrderDate):m; sum(Amount):amt) |
| 5 | =output(interval@s(A1,now())) |
@m represents performing multi-threaded computation according to the parallel options configured in the option.
At the same time turn on this parallel option.