How to set duplicate content in a dataset to null with esProc
The first two fields of a certain database table may have duplicate values, such as the first three records below.
| Column_A | Column_B | Column_C |
|---|---|---|
| 1 | AB | amount1 |
| 1 | AB | amount2 |
| 1 | AB | amount3 |
| 2 | OA | amount4 |
| 3 | OE | amount5 |
| 3 | OE | amount6 |
| 4 | DB | amount7 |
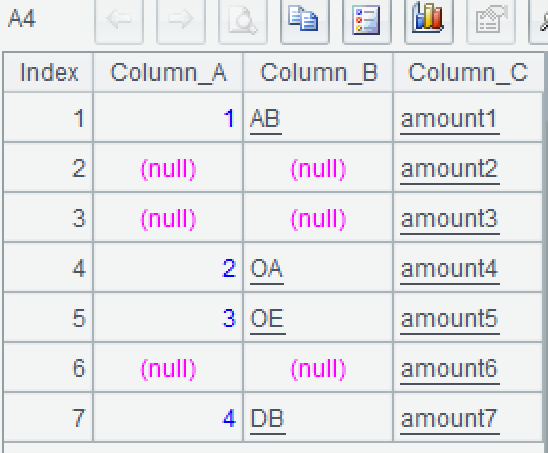
Now we need to change all duplicate values to null. In other words, after grouping by the first two fields (equivalent to grouping by one of the fields), only the first record in the group remains unchanged, and the first two fields of other records are changed to null.
The calculation result is as follows:
| Column_A | Column_B | Column_C |
|---|---|---|
| 1 | AB | amount1 |
| amount2 | ||
| amount3 | ||
| 2 | OA | amount4 |
| 3 | OE | amount5 |
| amount6 | ||
| 4 | DB | amount7 |
After SQL grouping, it must aggregate immediately, and the grouped subsets cannot be kept for further calculation . SQL also does not have natural row numbers within the group, making the code difficult to write.
esProc provides a rich set of calculation functions that can keep grouped subsets for further calculation, with natural row numbers, including row numbers within the group:https://try.esproc.com/splx?505
| A | |
|---|---|
| 1 | $select * from table_name.txt |
| 2 | =A1.group(Column_A) |
| 3 | =A2.run(~.(if(#!=1,Column_A=Column_B=null))) |
| 4 | =A3.conj() |
A1: Load data.
A2: Group by the first field using the group function, but do not aggregate.
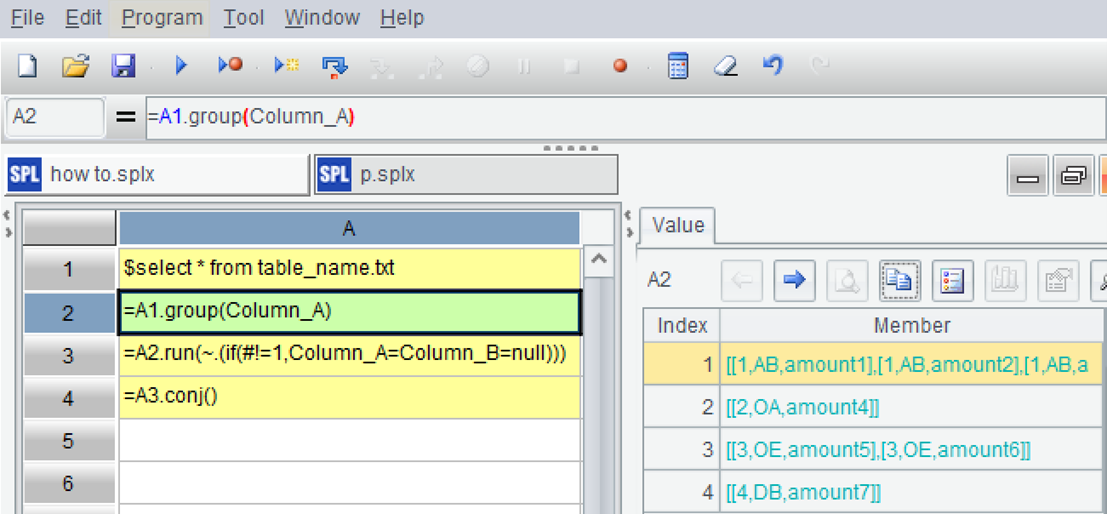
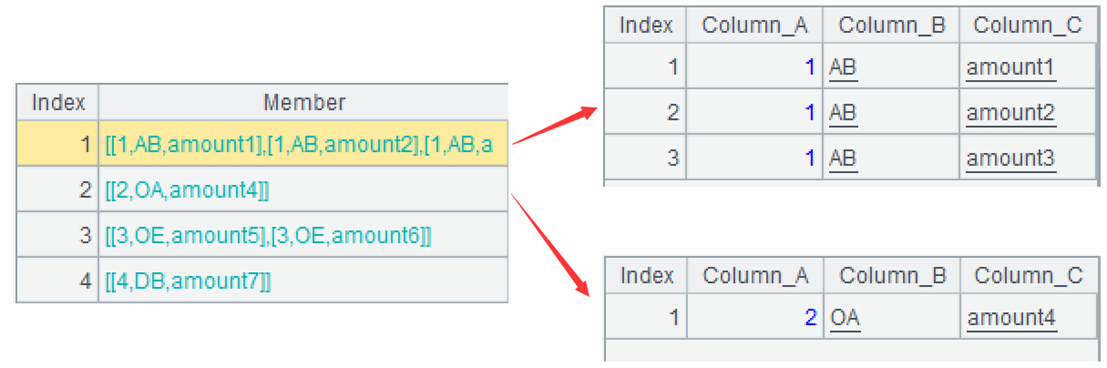

=A1.group(Column_A).run(~.(if(#!=1,Column_A=Column_B=null))).conj()